SpidR: Learning Fast and Stable Linguistic Units for Spoken Language Models Without Supervision
作者: Maxime Poli, Mahi Luthra, Youssef Benchekroun, Yosuke Higuchi, Martin Gleize, Jiayi Shen, Robin Algayres, Yu-An Chung, Mido Assran, Juan Pino, Emmanuel Dupoux
分类: cs.CL, cs.SD, eess.AS
发布日期: 2025-12-23 (更新: 2025-12-26)
备注: Published in Transactions on Machine Learning Research. 30 pages, 16 figures
🔗 代码/项目: GITHUB
💡 一句话要点
SpidR:一种无需监督即可学习快速稳定语音单元的语音语言模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 自监督学习 语音表征学习 语音语言模型 在线聚类 自蒸馏
📋 核心要点
- 现有语音语言模型依赖文本中间过程,限制了直接从语音学习语言的能力,需要更有效的语音语义表征方法。
- SpidR通过掩码预测、自蒸馏和在线聚类,从原始波形中学习具有高度可访问语音信息的表征,无需文本监督。
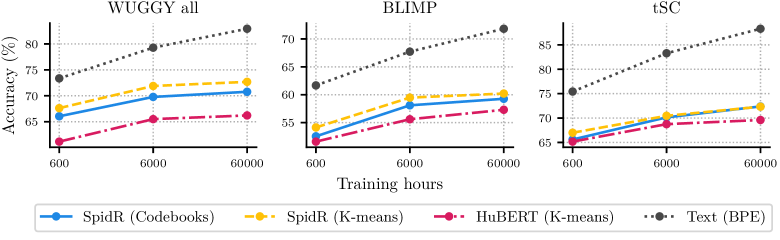
- SpidR在语言建模基准测试中优于现有模型,且预训练时间显著减少,仅需一天,验证了其效率和有效性。
📝 摘要(中文)
语言建模和语音表征学习的并行发展,提高了直接从语音中学习语言而无需文本中间过程的可能性。这需要直接从语音中提取语义表征。本文提出了三点贡献。首先,我们引入了SpidR,一种自监督语音表征模型,可以高效地学习具有高度可访问语音信息的表征,这使得它特别适合于无文本语音语言建模。它使用掩码预测目标、自蒸馏和在线聚类在原始波形上进行训练。学生模型的中间层学习预测来自教师模型中间层的分配。与以往的方法相比,这种学习目标稳定了在线聚类过程,从而产生更高质量的码本。在下游语言建模基准测试(sWUGGY、sBLIMP、tSC)中,SpidR优于wav2vec 2.0、HuBERT、WavLM和DinoSR。其次,我们系统地评估了跨模型和层级的语音单元质量(ABX、PNMI)与语言建模性能之间的相关性,验证了这些指标作为可靠的代理。最后,与HuBERT相比,SpidR显著减少了预训练时间,仅需在16个GPU上预训练一天,而不是一周。这种加速得益于预训练方法和高效的代码库,从而可以更快地迭代和更容易地进行实验。我们在https://github.com/facebookresearch/spidr开源了训练代码和模型检查点。
🔬 方法详解
问题定义:现有语音语言模型通常依赖于文本标注数据进行训练,或者需要复杂的pipeline进行语音到文本的转换,这限制了模型在低资源场景下的应用,并且无法充分利用语音信号中蕴含的丰富信息。现有自监督语音表征学习方法,例如HuBERT,预训练时间长,计算资源消耗大,阻碍了快速迭代和实验。
核心思路:SpidR的核心思路是通过自监督学习,直接从原始语音波形中学习高质量的语音单元表征,无需文本标注。通过结合掩码预测、自蒸馏和在线聚类,稳定在线聚类过程,生成更高质量的码本。这种方法旨在提高语音表征的语音信息可访问性,从而提升下游语音语言建模任务的性能。
技术框架:SpidR的整体框架包括以下几个主要模块:1) 特征提取器:将原始语音波形转换为特征序列。2) 掩码预测模块:随机掩盖部分特征,并预测被掩盖的特征。3) 自蒸馏模块:使用教师模型生成的目标来指导学生模型的学习,稳定训练过程。4) 在线聚类模块:将语音特征聚类成离散的语音单元,形成码本。学生模型的中间层学习预测来自教师模型中间层的分配。
关键创新:SpidR的关键创新在于结合了自蒸馏和在线聚类,稳定了在线聚类过程。传统的在线聚类方法容易受到噪声和不稳定的影响,导致码本质量不高。SpidR通过自蒸馏,利用教师模型的知识来指导学生模型的学习,从而提高了在线聚类的稳定性和码本质量。此外,SpidR还优化了训练流程和代码库,显著减少了预训练时间。
关键设计:SpidR的关键设计包括:1) 使用Transformer网络作为特征提取器和预测器。2) 使用交叉熵损失函数来衡量预测结果与目标之间的差异。3) 使用动量更新策略来更新教师模型的参数。4) 使用k-means算法进行在线聚类。5) 优化了代码库,使用了高效的GPU计算和数据加载方法。
🖼️ 关键图片


📊 实验亮点
SpidR在sWUGGY、sBLIMP和tSC等下游语言建模基准测试中,性能优于wav2vec 2.0、HuBERT、WavLM和DinoSR等模型。更重要的是,SpidR显著减少了预训练时间,仅需在16个GPU上预训练一天,而HuBERT则需要一周。这表明SpidR在效率和性能方面都具有显著优势。
🎯 应用场景
SpidR具有广泛的应用前景,包括语音识别、语音合成、语音翻译、语音搜索等。它特别适用于低资源语言的语音处理,因为它可以无需文本标注数据进行训练。此外,SpidR还可以用于开发新型的语音交互系统,例如智能助手和语音控制设备。该研究的成果有助于推动语音技术的发展,并为人类提供更自然、更便捷的语音交互体验。
📄 摘要(原文)
The parallel advances in language modeling and speech representation learning have raised the prospect of learning language directly from speech without textual intermediates. This requires extracting semantic representations directly from speech. Our contributions are threefold. First, we introduce SpidR, a self-supervised speech representation model that efficiently learns representations with highly accessible phonetic information, which makes it particularly suited for textless spoken language modeling. It is trained on raw waveforms using a masked prediction objective combined with self-distillation and online clustering. The intermediate layers of the student model learn to predict assignments derived from the teacher's intermediate layers. This learning objective stabilizes the online clustering procedure compared to previous approaches, resulting in higher quality codebooks. SpidR outperforms wav2vec 2.0, HuBERT, WavLM, and DinoSR on downstream language modeling benchmarks (sWUGGY, sBLIMP, tSC). Second, we systematically evaluate across models and layers the correlation between speech unit quality (ABX, PNMI) and language modeling performance, validating these metrics as reliable proxies. Finally, SpidR significantly reduces pretraining time compared to HuBERT, requiring only one day of pretraining on 16 GPUs, instead of a week. This speedup is enabled by the pretraining method and an efficient codebase, which allows faster iteration and easier experimentation. We open-source the training code and model checkpoints at https://github.com/facebookresearch/spidr.