FaithLens: Detecting and Explaining Faithfulness Hallucination
作者: Shuzheng Si, Qingyi Wang, Haozhe Zhao, Yuzhuo Bai, Guanqiao Chen, Kangyang Luo, Gang Chen, Fanchao Qi, Minjia Zhang, Baobao Chang, Maosong Sun
分类: cs.CL, cs.AI
发布日期: 2025-12-23 (更新: 2026-01-05)
💡 一句话要点
提出FaithLens,用于检测并解释大语言模型中的忠实性幻觉问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 忠实性幻觉检测 可解释AI 大语言模型 强化学习 数据合成
📋 核心要点
- 大型语言模型(LLM)的幻觉问题严重影响其在实际应用中的可靠性,尤其是在检索增强生成和摘要等任务中。
- FaithLens通过合成带有解释的训练数据,并结合数据过滤和强化学习,实现了对幻觉的有效检测和解释。
- 实验结果表明,FaithLens在多个任务上超越了GPT-4.1等先进模型,同时提供了高质量的解释,提升了模型的可信度。
📝 摘要(中文)
本文介绍FaithLens,一种经济高效且有效的忠实性幻觉检测模型,能够联合提供二元预测和相应的解释,以提高可信度。为了实现这一目标,我们首先通过先进的大语言模型合成带有解释的训练数据,并应用精心设计的数据过滤策略,以确保标签正确性、解释质量和数据多样性。随后,我们使用这些精心策划的训练数据对模型进行冷启动微调,并使用基于规则的强化学习进一步优化模型,奖励预测正确性和解释质量。在12个不同任务上的结果表明,80亿参数的FaithLens优于GPT-4.1和o3等先进模型。此外,FaithLens可以生成高质量的解释,从而在可信度、效率和有效性之间实现独特的平衡。
🔬 方法详解
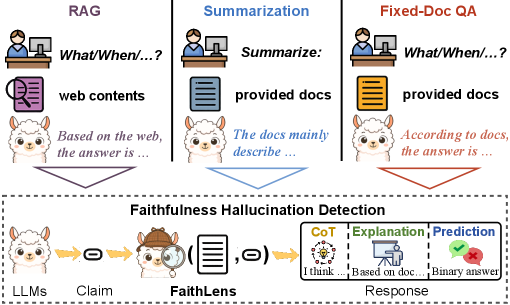
问题定义:论文旨在解决大型语言模型(LLM)中普遍存在的“忠实性幻觉”问题。具体来说,就是LLM生成的文本内容与输入上下文或知识库不一致,甚至完全捏造信息。现有方法要么检测精度不足,要么缺乏对幻觉原因的解释,难以提升用户信任度。
核心思路:FaithLens的核心思路是训练一个能够同时预测幻觉存在与否,并提供解释的模型。通过让模型学习解释幻觉产生的原因,可以提高检测的准确性,并增强模型的可信度。这种方法借鉴了“可解释AI”的思想,将解释作为模型输出的一部分。
技术框架:FaithLens的训练分为三个主要阶段:1) 数据合成:利用先进的LLM生成带有解释的训练数据,包括幻觉样本和非幻觉样本。2) 数据过滤:设计一套规则和指标,对合成的数据进行过滤,确保标签的正确性、解释的质量和数据的多样性。3) 模型训练:首先使用过滤后的数据进行冷启动微调,然后使用基于规则的强化学习进一步优化模型,奖励预测的准确性和解释的质量。
关键创新:FaithLens的关键创新在于:1) 联合预测和解释:模型不仅预测是否存在幻觉,还生成对幻觉原因的解释,提高了可信度。2) 基于规则的强化学习:使用规则定义的奖励函数来优化模型的预测准确性和解释质量,避免了人工标注奖励的成本。3) 高效的数据合成和过滤策略:利用LLM生成训练数据,并设计有效的过滤策略,降低了数据标注成本,并保证了数据质量。
关键设计:在数据合成阶段,使用了prompt engineering来引导LLM生成包含解释的样本。数据过滤阶段,定义了多个指标来评估解释的质量,例如相关性、完整性和一致性。强化学习阶段,奖励函数综合考虑了预测的准确性和解释的质量,并使用规则来定义奖励值。
🖼️ 关键图片

📊 实验亮点
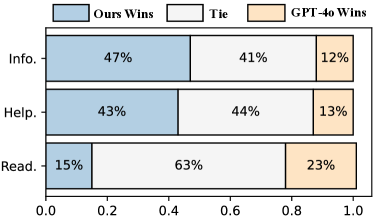
FaithLens在12个不同的任务上进行了评估,结果表明,80亿参数的FaithLens优于GPT-4.1和o3等先进模型。具体来说,FaithLens在幻觉检测的准确率和召回率上均取得了显著提升,并且能够生成高质量的解释,帮助用户理解模型预测的原因。这些结果表明,FaithLens在可信度、效率和有效性之间实现了良好的平衡。
🎯 应用场景
FaithLens可应用于各种需要大语言模型生成文本的场景,例如检索增强生成、文本摘要、问答系统等。通过检测和解释幻觉,可以提高生成文本的可靠性和可信度,减少错误信息的传播,增强用户对AI系统的信任。未来,该技术还可以用于评估和改进LLM的训练数据和模型架构,从而从根本上减少幻觉的产生。
📄 摘要(原文)
Recognizing whether outputs from large language models (LLMs) contain faithfulness hallucination is crucial for real-world applications, e.g., retrieval-augmented generation and summarization. In this paper, we introduce FaithLens, a cost-efficient and effective faithfulness hallucination detection model that can jointly provide binary predictions and corresponding explanations to improve trustworthiness. To achieve this, we first synthesize training data with explanations via advanced LLMs and apply a well-defined data filtering strategy to ensure label correctness, explanation quality, and data diversity. Subsequently, we fine-tune the model on these well-curated training data as a cold start and further optimize it with rule-based reinforcement learning, using rewards for both prediction correctness and explanation quality. Results on 12 diverse tasks show that the 8B-parameter FaithLens outperforms advanced models such as GPT-4.1 and o3. Also, FaithLens can produce high-quality explanations, delivering a distinctive balance of trustworthiness, efficiency, and effectiveness.