Fun-Audio-Chat Technical Report
作者: Tongyi Fun Team, Qian Chen, Luyao Cheng, Chong Deng, Xiangang Li, Jiaqing Liu, Chao-Hong Tan, Wen Wang, Junhao Xu, Jieping Ye, Qinglin Zhang, Qiquan Zhang, Jingren Zhou
分类: cs.CL, cs.AI, cs.SD, eess.AS
发布日期: 2025-12-23 (更新: 2026-01-20)
备注: Authors are listed in alphabetical order, 21 pages, open-source at https://github.com/FunAudioLLM/Fun-Audio-Chat
🔗 代码/项目: GITHUB
💡 一句话要点
Fun-Audio-Chat:通过双分辨率语音表示和核心鸡尾酒训练,实现高效且强大的大型音频语言模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型音频语言模型 双分辨率语音表示 核心鸡尾酒训练 语音理解 语音生成 指令遵循 语音共情
📋 核心要点
- 现有语音-文本模型存在语音和文本token时间分辨率不匹配的问题,导致语义信息损失、计算成本高昂以及文本知识遗忘。
- Fun-Audio-Chat通过双分辨率语音表示(DRSR)和核心鸡尾酒训练,在保证效率的同时提升音频理解和生成能力。
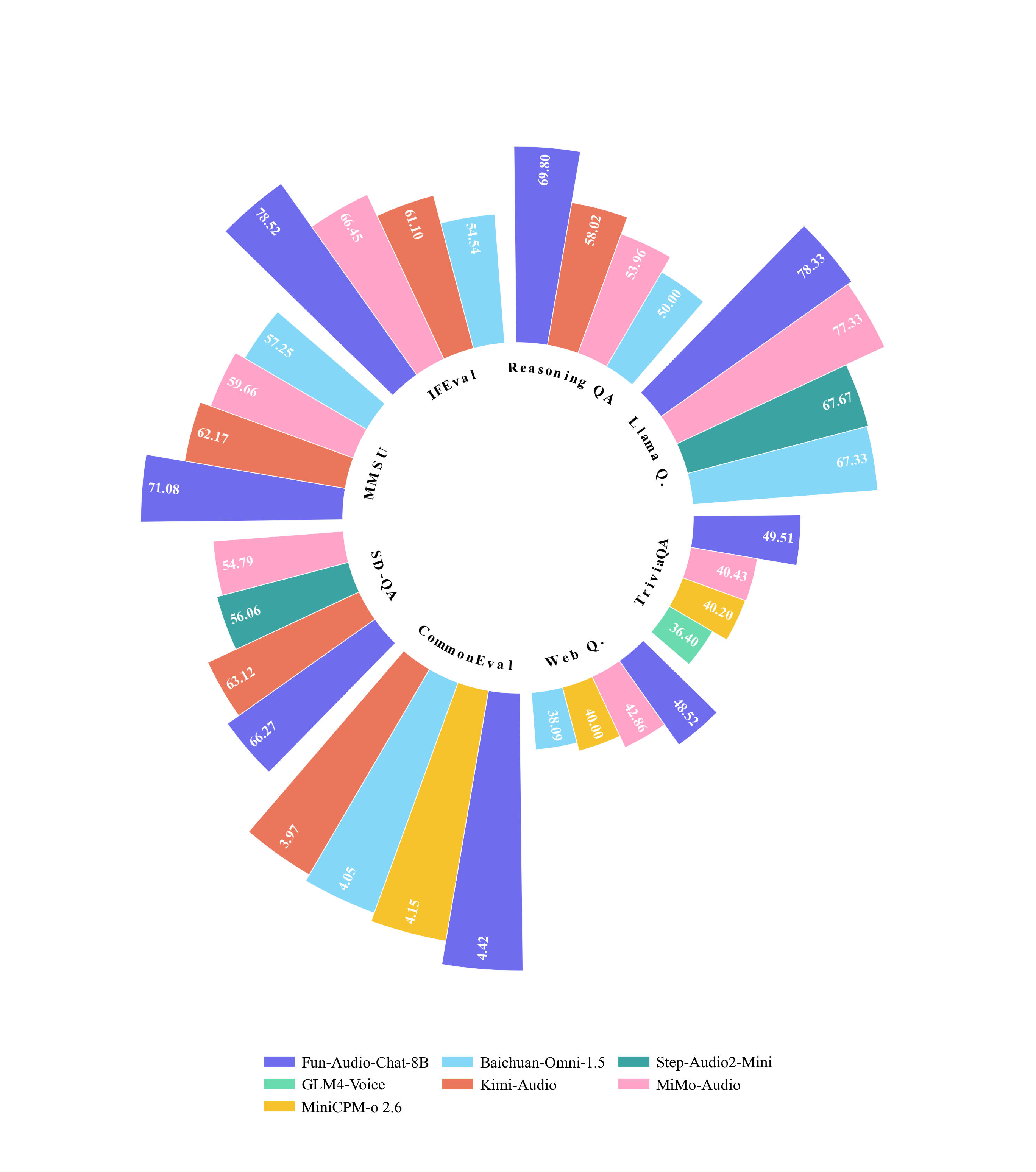
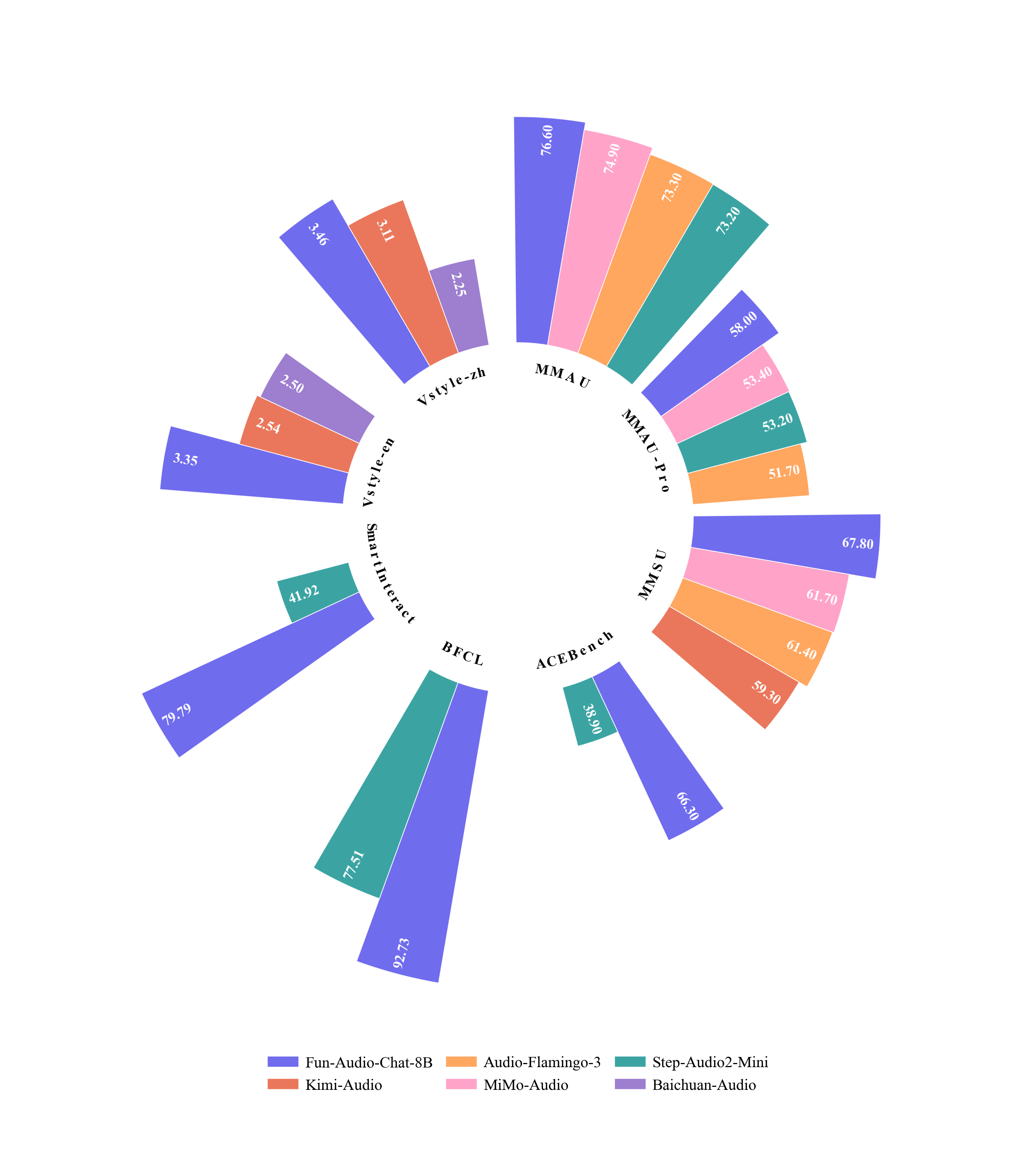
- Fun-Audio-Chat在语音到文本、语音到语音任务以及口语QA基准测试中表现出色,并在音频理解等方面优于同等规模模型。
📝 摘要(中文)
本文介绍了Fun-Audio-Chat,一种大型音频语言模型,旨在解决现有语音-文本模型中语音token(25Hz)和文本token(~3Hz)之间的时间分辨率不匹配问题,该问题会稀释语义信息、增加计算成本并导致文本LLM知识的灾难性遗忘。Fun-Audio-Chat通过借鉴DrVoice的两项创新来解决这些限制。首先,双分辨率语音表示(DRSR)允许共享LLM以高效的5Hz处理音频(通过token分组),而语音精炼头以高质量的25Hz生成token,从而平衡效率(GPU减少约50%)和质量。其次,核心鸡尾酒训练是一种两阶段微调方法,通过中间合并来减轻灾难性遗忘。然后,应用多任务DPO训练来增强鲁棒性、音频理解、指令遵循和语音共情。这种多阶段后训练使Fun-Audio-Chat能够在获得强大的音频理解、推理和生成能力的同时,保留文本LLM知识。Fun-Audio-Chat 8B和MoE 30B-A3B在语音到文本和语音到语音任务上表现出竞争优势,在口语QA基准测试中名列同等规模模型的前茅。它们还在音频理解、语音功能调用、指令遵循和语音共情方面取得了具有竞争力的甚至更优越的性能。我们开发了Fun-Audio-Chat-Duplex,这是一种全双工变体,在口语QA和全双工交互方面表现出色。我们开源了Fun-Audio-Chat-8B,包括训练和推理代码,并提供了一个交互式演示。
🔬 方法详解
问题定义:现有联合语音-文本模型在处理语音和文本时,由于两者token的时间分辨率差异显著(语音25Hz,文本~3Hz),导致模型在理解和生成语音内容时面临信息稀释、计算资源消耗大以及灾难性遗忘文本LLM知识等问题。这些问题限制了模型在实际语音交互应用中的性能和效率。
核心思路:Fun-Audio-Chat的核心思路是通过双分辨率语音表示(DRSR)来解决语音和文本token的时间分辨率不匹配问题,并利用核心鸡尾酒训练(Core-Cocktail Training)来缓解灾难性遗忘。DRSR允许模型在不同分辨率下处理语音信息,兼顾效率和质量。核心鸡尾酒训练则通过两阶段微调,在保留文本知识的同时,提升音频理解能力。
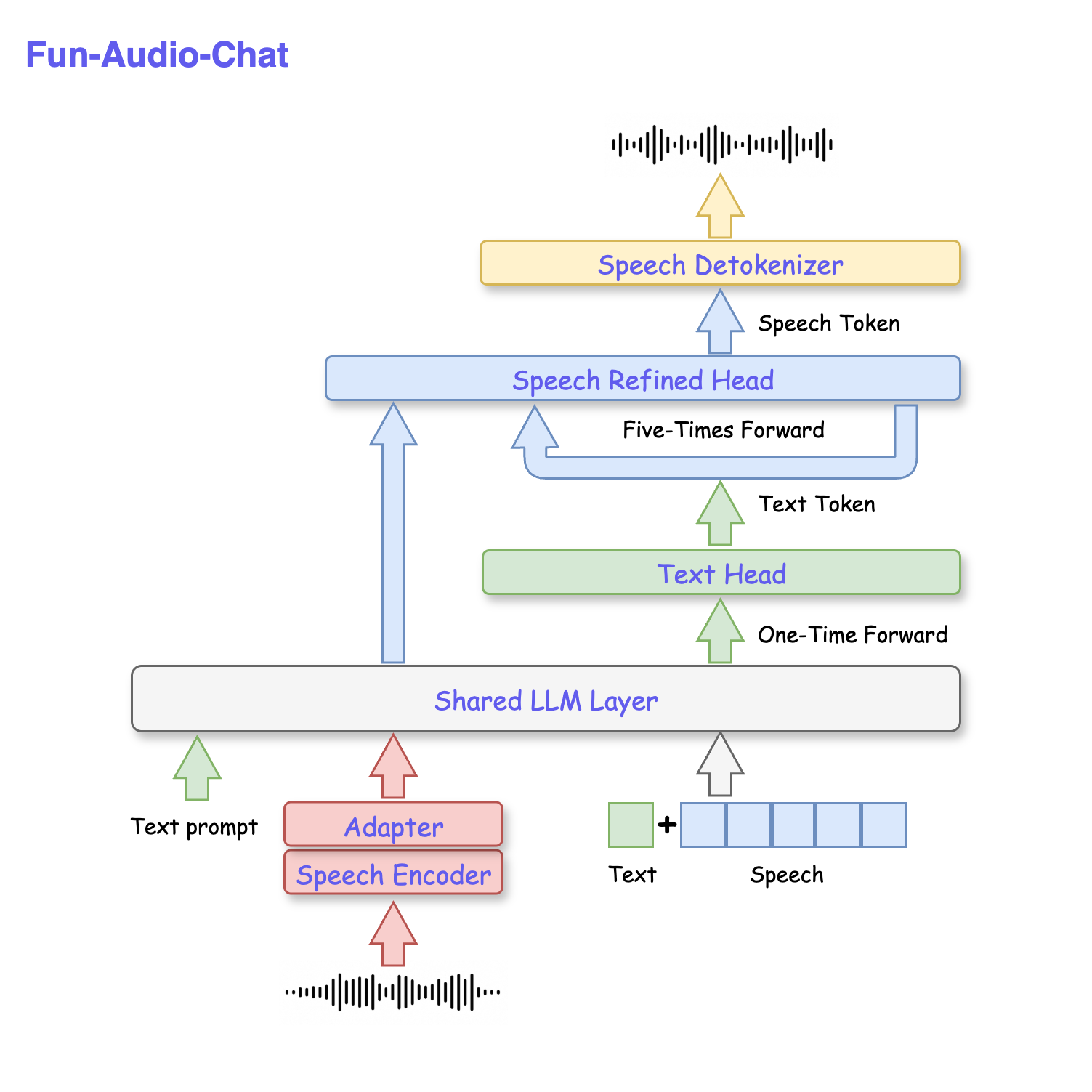
技术框架:Fun-Audio-Chat的技术框架主要包括以下几个模块/阶段:1) 双分辨率语音表示(DRSR):将语音信号处理成两种不同分辨率的token,低分辨率(5Hz)的token用于LLM处理,高分辨率(25Hz)的token由语音精炼头生成。2) 核心鸡尾酒训练:包括两个阶段,首先进行预训练模型的微调,然后进行中间合并,以减轻灾难性遗忘。3) 多任务DPO训练:用于增强模型的鲁棒性、音频理解、指令遵循和语音共情能力。
关键创新:Fun-Audio-Chat的关键创新在于双分辨率语音表示(DRSR)和核心鸡尾酒训练。DRSR允许模型在不同分辨率下处理语音信息,从而在效率和质量之间取得平衡。核心鸡尾酒训练则通过两阶段微调,有效缓解了灾难性遗忘问题。与需要大规模音频-文本预训练的LALM不同,Fun-Audio-Chat利用预训练模型和广泛的后训练。
关键设计:在双分辨率语音表示中,低分辨率token通过token分组实现,以降低计算成本。语音精炼头负责生成高质量的高分辨率token。核心鸡尾酒训练的具体实现细节(未知)。多任务DPO训练中,任务的选择和权重设置对模型性能至关重要(未知)。
🖼️ 关键图片
📊 实验亮点
Fun-Audio-Chat 8B和MoE 30B-A3B在语音到文本和语音到语音任务上表现出竞争优势,在口语QA基准测试中名列同等规模模型的前茅。它们还在音频理解、语音功能调用、指令遵循和语音共情方面取得了具有竞争力的甚至更优越的性能。Fun-Audio-Chat-Duplex,这是一种全双工变体,在口语QA和全双工交互方面表现出色。
🎯 应用场景
Fun-Audio-Chat具有广泛的应用前景,包括智能助手、语音搜索、语音翻译、语音内容创作等领域。它可以用于构建更自然、更智能的语音交互系统,提升用户体验。此外,该模型还可以应用于语音情感识别、语音诊断等领域,具有重要的实际价值和潜在的社会影响。
📄 摘要(原文)
Recent advancements in joint speech-text models show great potential for seamless voice interactions. However, existing models face critical challenges: temporal resolution mismatch between speech tokens (25Hz) and text tokens (~3Hz) dilutes semantic information, incurs high computational costs, and causes catastrophic forgetting of text LLM knowledge. We introduce Fun-Audio-Chat, a Large Audio Language Model addressing these limitations via two innovations from our previous work DrVoice. First, Dual-Resolution Speech Representations (DRSR): the Shared LLM processes audio at efficient 5Hz (via token grouping), while the Speech Refined Head generates high-quality tokens at 25Hz, balancing efficiency (~50% GPU reduction) and quality. Second, Core-Cocktail Training, a two-stage fine-tuning with intermediate merging that mitigates catastrophic forgetting. We then apply Multi-Task DPO Training to enhance robustness, audio understanding, instruction-following and voice empathy. This multi-stage post-training enables Fun-Audio-Chat to retain text LLM knowledge while gaining powerful audio understanding, reasoning, and generation. Unlike recent LALMs requiring large-scale audio-text pre-training, Fun-Audio-Chat leverages pre-trained models and extensive post-training. Fun-Audio-Chat 8B and MoE 30B-A3B achieve competitive performance on Speech-to-Text and Speech-to-Speech tasks, ranking top among similar-scale models on Spoken QA benchmarks. They also achieve competitive to superior performance on Audio Understanding, Speech Function Calling, Instruction-Following and Voice Empathy. We develop Fun-Audio-Chat-Duplex, a full-duplex variant with strong performance on Spoken QA and full-duplex interactions. We open-source Fun-Audio-Chat-8B with training and inference code, and provide an interactive demo, at https://github.com/FunAudioLLM/Fun-Audio-Chat .