M$^3$KG-RAG: Multi-hop Multimodal Knowledge Graph-enhanced Retrieval-Augmented Generation
作者: Hyeongcheol Park, Jiyoung Seo, Jaewon Mun, Hogun Park, Wonmin Byeon, Sung June Kim, Hyeonsoo Im, JeungSub Lee, Sangpil Kim
分类: cs.CL, cs.AI
发布日期: 2025-12-23 (更新: 2025-12-24)
💡 一句话要点
提出M$^3$KG-RAG,通过多跳多模态知识图增强检索增强生成,提升MLLM在视听领域的推理和 grounding 能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 知识图谱 检索增强生成 多跳推理 视听理解
📋 核心要点
- 现有方法在视听领域多模态RAG中,面临MMKG覆盖范围有限和检索结果冗余等问题。
- M$^3$KG-RAG构建多跳MMKG,并提出GRASP方法进行精确检索和冗余知识剪枝。
- 实验结果表明,M$^3$KG-RAG显著提升了MLLM在多模态推理和 grounding 方面的性能。
📝 摘要(中文)
检索增强生成(RAG)最近已扩展到多模态设置,将多模态大型语言模型(MLLM)与海量的外部知识语料库(如多模态知识图(MMKG))连接起来。尽管取得了进展,但视听领域的多模态RAG仍然面临挑战,原因在于:1)现有MMKG的模态覆盖范围和多跳连接性有限;2)仅基于共享多模态嵌入空间的相似性进行检索,无法过滤掉离题或冗余的知识。为了解决这些限制,我们提出了M$^3$KG-RAG,一种多跳多模态知识图增强RAG,它从MMKG中检索与查询对齐的视听知识,从而提高MLLM的推理深度和答案的忠实性。具体来说,我们设计了一个轻量级的多智能体流水线来构建多跳MMKG(M$^3$KG),其中包含上下文丰富的多模态实体三元组,从而能够基于输入查询进行模态感知检索。此外,我们引入了GRASP(Grounded Retrieval And Selective Pruning),它确保精确的实体 grounding 到查询,评估答案支持的相关性,并修剪冗余上下文,仅保留生成响应所需的知识。在各种多模态基准上的大量实验表明,与现有方法相比,M$^3$KG-RAG显著增强了MLLM的多模态推理和 grounding 能力。
🔬 方法详解
问题定义:现有方法在视听领域的多模态RAG中,面临两个主要问题:一是现有的多模态知识图谱(MMKG)在模态覆盖范围和多跳连接性方面存在局限,导致无法充分利用外部知识;二是检索过程仅依赖于共享多模态嵌入空间的相似性,容易检索到与查询无关或冗余的信息,影响生成答案的质量。
核心思路:M$^3$KG-RAG的核心思路是通过构建一个更全面、更具连接性的多跳多模态知识图谱(M$^3$KG),并结合一种新的检索和剪枝方法(GRASP),来提高多模态RAG系统的性能。M$^3$KG旨在提供更丰富的上下文信息,而GRASP则负责精确地检索与查询相关的知识,并去除冗余信息,从而提高生成答案的准确性和忠实性。
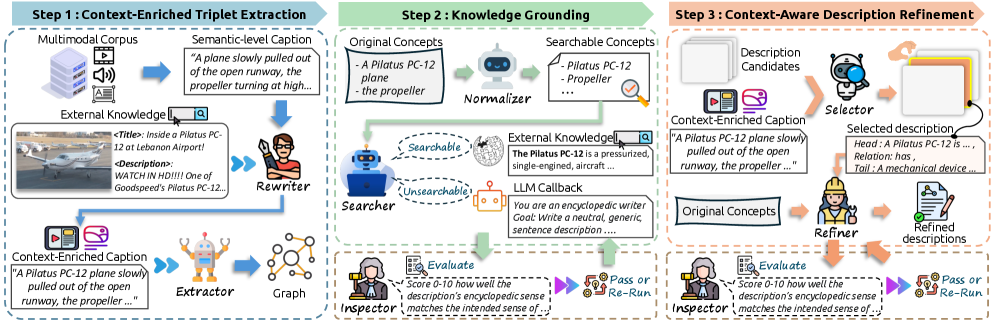
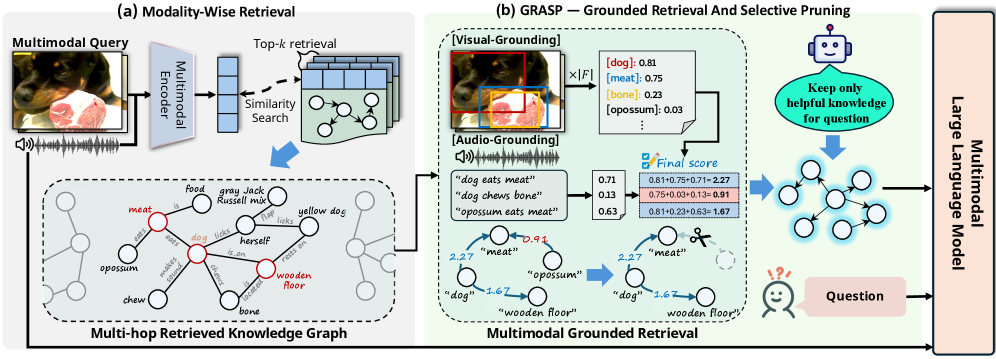
技术框架:M$^3$KG-RAG包含两个主要组成部分:多跳多模态知识图谱构建(M$^3$KG)和基于 grounding 的检索与选择性剪枝(GRASP)。首先,利用多智能体流水线构建M$^3$KG,该图谱包含上下文丰富的多模态实体三元组。然后,GRASP模块根据输入查询,进行实体 grounding,评估知识的相关性,并剪除冗余上下文,最终将精简后的知识提供给MLLM进行答案生成。
关键创新:该论文的关键创新在于:1)提出了一个轻量级的多智能体流水线,用于构建多跳多模态知识图谱(M$^3$KG),该图谱能够提供更丰富的上下文信息和多跳连接;2)引入了GRASP方法,该方法能够精确地将实体 grounding 到查询,并选择性地剪除冗余上下文,从而提高检索的准确性和效率。与现有方法相比,M$^3$KG-RAG能够更好地利用外部知识,并生成更准确、更忠实的答案。
关键设计:M$^3$KG的构建依赖于多智能体流水线,具体实现细节未知。GRASP方法的关键在于相关性评估和冗余剪枝策略,具体实现细节未知。论文中没有明确提及关键的参数设置、损失函数或网络结构等技术细节。
🖼️ 关键图片

📊 实验亮点
实验结果表明,M$^3$KG-RAG在多个多模态基准测试中显著优于现有方法,证明了其在多模态推理和 grounding 方面的有效性。具体性能数据和提升幅度在摘要中未给出,需要查阅原文。
🎯 应用场景
M$^3$KG-RAG可应用于各种需要多模态信息推理和 grounding 的场景,例如视听问答、视频内容理解、多模态对话系统等。该研究有助于提升机器在理解和生成多模态内容方面的能力,具有重要的实际应用价值和未来发展潜力。
📄 摘要(原文)
Retrieval-Augmented Generation (RAG) has recently been extended to multimodal settings, connecting multimodal large language models (MLLMs) with vast corpora of external knowledge such as multimodal knowledge graphs (MMKGs). Despite their recent success, multimodal RAG in the audio-visual domain remains challenging due to 1) limited modality coverage and multi-hop connectivity of existing MMKGs, and 2) retrieval based solely on similarity in a shared multimodal embedding space, which fails to filter out off-topic or redundant knowledge. To address these limitations, we propose M$^3$KG-RAG, a Multi-hop Multimodal Knowledge Graph-enhanced RAG that retrieves query-aligned audio-visual knowledge from MMKGs, improving reasoning depth and answer faithfulness in MLLMs. Specifically, we devise a lightweight multi-agent pipeline to construct multi-hop MMKG (M$^3$KG), which contains context-enriched triplets of multimodal entities, enabling modality-wise retrieval based on input queries. Furthermore, we introduce GRASP (Grounded Retrieval And Selective Pruning), which ensures precise entity grounding to the query, evaluates answer-supporting relevance, and prunes redundant context to retain only knowledge essential for response generation. Extensive experiments across diverse multimodal benchmarks demonstrate that M$^3$KG-RAG significantly enhances MLLMs' multimodal reasoning and grounding over existing approaches.