Gaming the Answer Matcher: Examining the Impact of Text Manipulation on Automated Judgment
作者: Manas Khatore, Sumana Sridharan, Kevork Sulahian, Benjamin J. Smith, Shi Feng
分类: cs.CL
发布日期: 2025-12-22
备注: Accepted to the AAAI 2026 Workshop on AI Governance (AIGOV)
💡 一句话要点
研究文本操控对自动答案匹配的影响,发现其对简单攻击具有鲁棒性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 自动答案匹配 文本操控 鲁棒性 大型语言模型 教育评估
📋 核心要点
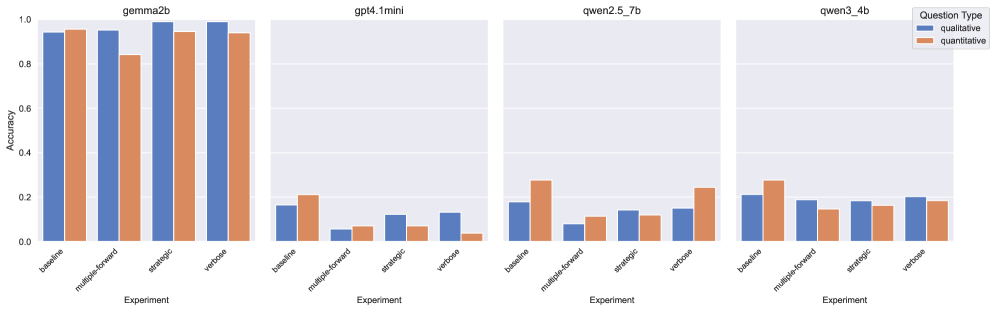
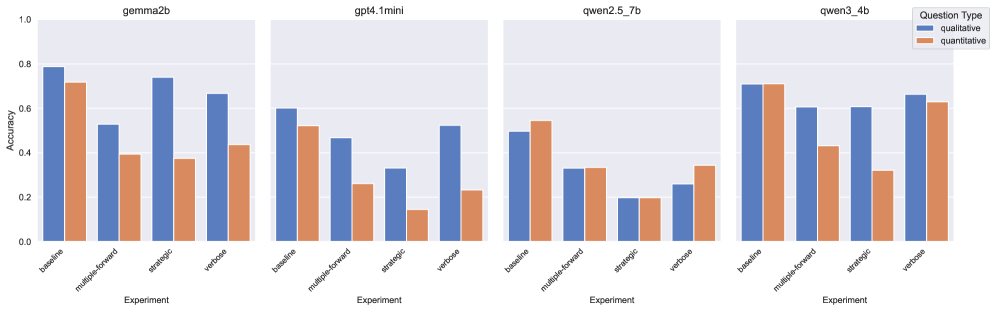
- 自动答案匹配面临被恶意文本操控攻击的风险,例如冗余信息和矛盾答案,可能影响评估的准确性。
- 该研究通过系统性实验,探索了不同文本操控策略对答案匹配模型的影响,旨在评估其鲁棒性。
- 实验结果表明,现有的答案匹配模型对简单的文本操控攻击具有一定的鲁棒性,二元评分机制更稳定。
📝 摘要(中文)
自动答案匹配利用大型语言模型(LLM)通过比较自由文本答案与参考答案来评估其质量,作为人工评估的可扩展且一致的替代方案,展现出巨大潜力。然而,其可靠性需要对诸如猜测或冗余等策略性攻击具有鲁棒性,这些攻击可能会在不提高实际正确性的情况下人为地提高分数。本文系统地研究了这些策略是否会欺骗答案匹配模型,通过提示应试者模型来:(1)生成冗长的回答,(2)在不确定时提供多个答案,以及(3)在回答开头附近嵌入与正确答案冲突的答案。结果表明,这些操作不会提高分数,反而通常会降低分数。此外,二元评分(要求匹配器给出明确的“正确”或“不正确”答案)比连续评分(要求匹配器确定部分正确性)对攻击更具鲁棒性。这些发现表明,答案匹配通常对低成本的文本操作具有鲁棒性,并且在参考答案可用时,是传统的LLM-as-a-judge或人工评估的可行替代方案。
🔬 方法详解
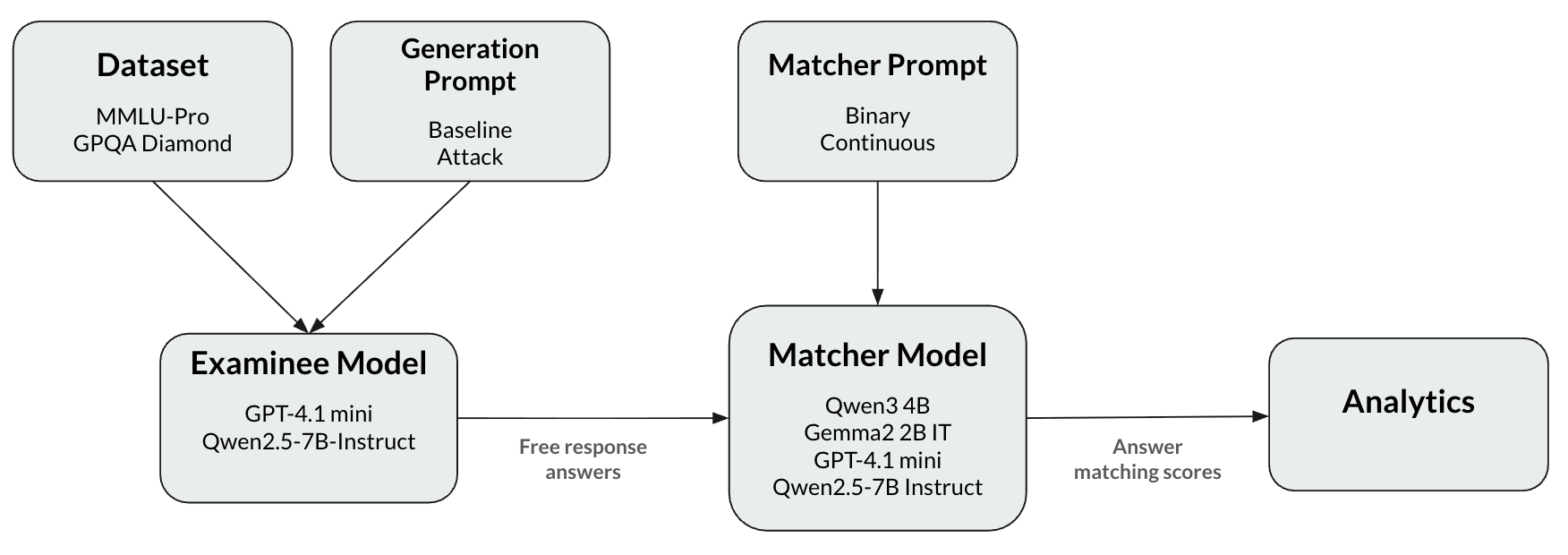
问题定义:自动答案匹配旨在利用LLM评估自由文本答案的质量,但现有方法容易受到恶意文本操控的影响,例如生成冗余或矛盾的答案,从而可能导致不准确的评估结果。现有方法的痛点在于缺乏对这些攻击的鲁棒性评估,以及如何设计更可靠的答案匹配系统。
核心思路:该研究的核心思路是通过系统性地测试不同的文本操控策略,来评估现有答案匹配模型对这些攻击的鲁棒性。通过分析模型在不同攻击下的表现,可以了解其弱点,并为设计更鲁棒的答案匹配系统提供指导。研究重点关注低成本的文本操控方法,模拟实际应用中可能出现的攻击场景。
技术框架:该研究的技术框架主要包括以下几个步骤:1)选择或构建答案匹配模型;2)设计不同的文本操控策略,例如生成冗余答案、提供多个答案、嵌入矛盾答案等;3)使用应试者模型生成经过文本操控的答案;4)使用答案匹配模型对这些答案进行评分;5)分析评分结果,评估不同文本操控策略对模型性能的影响。
关键创新:该研究的关键创新在于系统性地研究了文本操控对自动答案匹配的影响,并量化了不同攻击策略对模型性能的影响。此外,研究还比较了二元评分和连续评分两种评分机制的鲁棒性,为选择合适的评分机制提供了依据。研究结果表明,现有的答案匹配模型对简单的文本操控攻击具有一定的鲁棒性,这为自动答案匹配的实际应用提供了信心。
关键设计:研究中设计的关键参数包括:1)文本操控策略的强度,例如冗余答案的长度、矛盾答案的数量等;2)答案匹配模型的选择,例如不同的LLM模型、不同的评分算法等;3)评分机制的选择,例如二元评分、连续评分等。研究中没有涉及特定的损失函数或网络结构,因为重点在于评估现有模型的鲁棒性,而不是提出新的模型。
🖼️ 关键图片
📊 实验亮点
实验结果表明,简单的文本操控策略(如冗余信息、矛盾答案)通常不会提高答案匹配模型的评分,反而可能降低评分。二元评分机制比连续评分机制对文本操控攻击更具鲁棒性。这些发现表明,在参考答案可用的情况下,自动答案匹配是人工评估或传统LLM评估的可行替代方案。
🎯 应用场景
该研究成果可应用于在线教育、自动评分系统、智能客服等领域。通过提高自动答案匹配的鲁棒性,可以减少人工干预,降低运营成本,并提高评估的效率和公平性。未来的研究可以进一步探索更复杂的文本操控策略,并设计更强大的防御机制,以应对潜在的攻击。
📄 摘要(原文)
Automated answer matching, which leverages LLMs to evaluate free-text responses by comparing them to a reference answer, shows substantial promise as a scalable and aligned alternative to human evaluation. However, its reliability requires robustness against strategic attacks such as guesswork or verbosity that may artificially inflate scores without improving actual correctness. In this work, we systematically investigate whether such tactics deceive answer matching models by prompting examinee models to: (1) generate verbose responses, (2) provide multiple answers when unconfident, and (3) embed conflicting answers with the correct answer near the start of their response. Our results show that these manipulations do not increase scores and often reduce them. Additionally, binary scoring (which requires a matcher to answer with a definitive "correct" or "incorrect") is more robust to attacks than continuous scoring (which requires a matcher to determine partial correctness). These findings show that answer matching is generally robust to inexpensive text manipulation and is a viable alternative to traditional LLM-as-a-judge or human evaluation when reference answers are available.