Directional Attractors in LLM Reasoning: How Similarity Retrieval Steers Iterative Summarization Based Reasoning
作者: Cagatay Tekin, Charbel Barakat, Luis Joseph Luna Limgenco
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-12-22
备注: 6 pages, 2 figures. Code available at: github.com/cagopat/InftyThink-with-Cross-Chain-Memory
💡 一句话要点
提出InftyThink with Cross-Chain Memory,通过语义缓存提升LLM迭代推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 迭代推理 语义缓存 长程推理 知识推理
📋 核心要点
- 现有基于迭代摘要的推理框架在长程推理中存在重复生成相似推理策略的问题。
- InftyThink with Cross-Chain Memory通过语义缓存先前成功的推理模式来指导推理,避免盲目扩展上下文。
- 实验表明,该方法在结构化领域提高了准确性,并揭示了在异构领域中的局限性。
📝 摘要(中文)
本文提出InftyThink with Cross-Chain Memory,旨在通过增强迭代推理框架,提升大型语言模型(LLM)的长程推理能力。该方法利用基于嵌入的语义缓存,存储先前成功的推理模式。在每个推理步骤中,模型检索并利用语义上最相似的已存储引理,从而在不盲目扩展上下文窗口的情况下指导推理。在MATH500、AIME2024和GPQA-Diamond数据集上的实验表明,语义引理检索提高了结构化领域的准确性,同时也暴露了包含异构领域的测试中的失败模式。对推理轨迹的几何分析表明,缓存检索在嵌入空间中引入了方向性偏差,导致了一致的修复(提高基线准确性)和破坏(降低基线准确性)吸引子。研究结果突出了基于相似性的记忆对自我改进LLM推理的益处和局限性。
🔬 方法详解
问题定义:现有基于迭代摘要的推理框架,如InftyThink,在解决复杂推理问题时,虽然能够控制上下文增长,但存在重复生成相似推理策略的问题。这种重复不仅效率低下,而且可能限制模型探索更优解的能力。现有方法缺乏对历史推理经验的有效利用,导致推理过程缺乏方向性指导。
核心思路:本文的核心思路是利用语义缓存来存储和检索先前成功的推理模式,从而在后续推理过程中提供方向性指导。通过将历史推理步骤(引理)嵌入到语义空间中,并根据语义相似性进行检索,模型可以借鉴先前成功的经验,避免重复探索,并加速收敛到更优解。
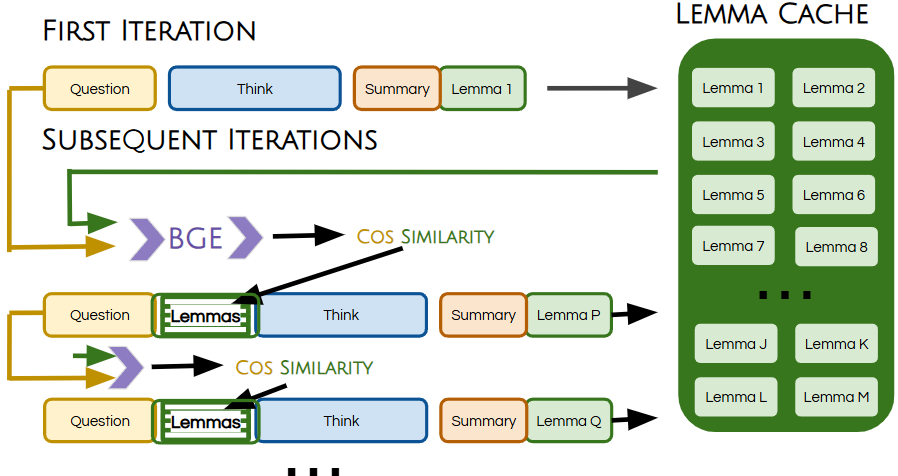
技术框架:InftyThink with Cross-Chain Memory在InftyThink的基础上增加了跨链记忆模块。整体流程如下:1) 在每个推理步骤中,模型生成候选引理;2) 将候选引理嵌入到语义空间中;3) 从语义缓存中检索最相似的引理;4) 将检索到的引理作为上下文信息,指导模型生成下一个推理步骤。语义缓存会不断更新,存储新的成功推理模式。
关键创新:最重要的技术创新点在于引入了基于嵌入的语义缓存,用于存储和检索先前成功的推理模式。与传统的上下文窗口方法相比,语义缓存能够更有效地利用历史信息,避免盲目扩展上下文,并提供方向性指导。此外,通过分析推理轨迹的几何特性,揭示了缓存检索在嵌入空间中引入的方向性偏差,为理解和改进LLM推理提供了新的视角。
关键设计:论文的关键设计包括:1) 使用预训练语言模型(如LLM)生成引理嵌入;2) 使用余弦相似度等度量方法计算引理之间的语义相似性;3) 设置缓存大小和检索数量等参数,控制记忆的容量和利用程度;4) 分析推理轨迹在嵌入空间中的几何特性,例如吸引子的存在和性质。
🖼️ 关键图片
📊 实验亮点
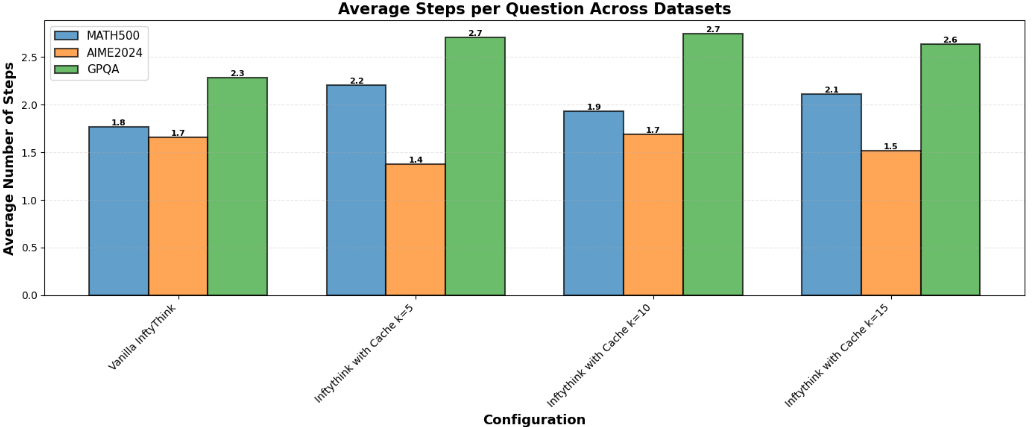
实验结果表明,InftyThink with Cross-Chain Memory在MATH500、AIME2024和GPQA-Diamond等数据集上取得了显著的性能提升。具体而言,在结构化领域,该方法提高了推理准确性。研究还发现,语义缓存检索会在嵌入空间中引入方向性偏差,形成“修复”和“破坏”吸引子,揭示了基于相似性的记忆对LLM推理的复杂影响。
🎯 应用场景
该研究成果可应用于需要长程推理能力的各种场景,例如数学问题求解、代码生成、知识图谱推理等。通过利用语义缓存,可以提升LLM在复杂任务中的推理效率和准确性,并为开发更智能的AI系统提供新的思路。此外,该研究对于理解LLM的推理过程和内部机制也具有重要意义。
📄 摘要(原文)
Iterative summarization based reasoning frameworks such as InftyThink enable long-horizon reasoning in large language models (LLMs) by controlling context growth, but they repeatedly regenerate similar reasoning strategies across tasks. We introduce InftyThink with Cross-Chain Memory, an extension that augments iterative reasoning with an embedding-based semantic cache of previously successful reasoning patterns. At each reasoning step, the model retrieves and conditions on the most semantically similar stored lemmas, guiding inference without expanding the context window indiscriminately. Experiments on MATH500, AIME2024, and GPQA-Diamond demonstrate that semantic lemma retrieval improves accuracy in structured domains while exposing failure modes in tests that include heterogeneous domains. Geometric analyses of reasoning trajectories reveal that cache retrieval induces directional biases in embedding space, leading to consistent fix (improve baseline accuracy) and break (degradation in baseline accuracy) attractors. Our results highlight both the benefits and limits of similarity-based memory for self-improving LLM reasoning.