GuardEval: A Multi-Perspective Benchmark for Evaluating Safety, Fairness, and Robustness in LLM Moderators
作者: Naseem Machlovi, Maryam Saleki, Ruhul Amin, Mohamed Rahouti, Shawqi Al-Maliki, Junaid Qadir, Mohamed M. Abdallah, Ala Al-Fuqaha
分类: cs.CL, cs.AI, cs.HC, cs.LG
发布日期: 2025-12-22
💡 一句话要点
提出GuardEval基准评测与GemmaGuard模型,提升LLM内容审核的安全性、公平性和鲁棒性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM内容审核 安全性 公平性 鲁棒性 基准评测 多视角学习 GemmaGuard QLoRA微调
📋 核心要点
- 现有LLM内容审核模型在处理隐式冒犯、微妙偏见和越狱提示等复杂场景时表现不足,且易受训练数据中的社会偏见影响。
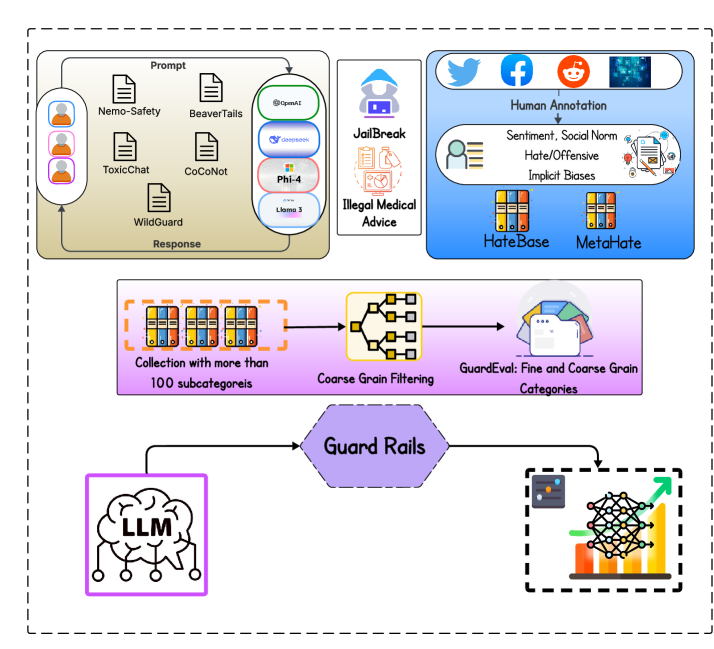
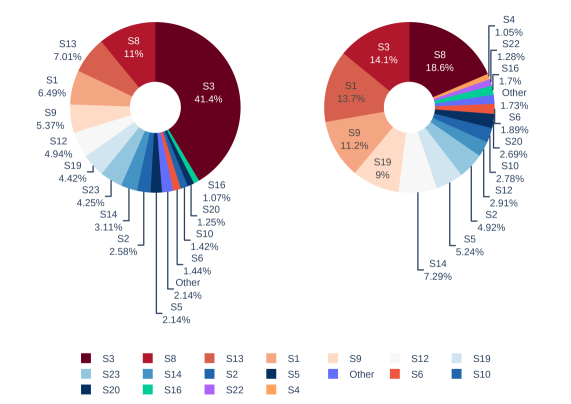
- 论文提出GuardEval,一个包含106个细粒度类别的多视角基准数据集,用于训练和评估LLM内容审核的安全性、公平性和鲁棒性。
- 论文提出GemmaGuard,一个基于Gemma3-12B并在GuardEval上微调的模型,实验表明其性能显著优于现有领先的审核模型。
📝 摘要(中文)
随着大型语言模型(LLMs)日益融入日常生活,对更安全的内容审核系统的需求变得空前迫切,该系统既能区分无害请求与有害请求,又能维持适当的审查界限。现有的LLM虽然可以检测有害或不安全内容,但由于这些问题的主观性和上下文依赖性,它们在细微的案例中表现不佳,例如隐式冒犯、微妙的性别和种族偏见以及越狱提示。此外,它们对训练数据的严重依赖会强化社会偏见,导致不一致且在伦理上有问题的结果。为了应对这些挑战,我们引入了GuardEval,这是一个统一的多视角基准数据集,专为训练和评估而设计,包含106个细粒度类别,涵盖人类情感、冒犯性和仇恨性语言、性别和种族偏见以及更广泛的安全问题。我们还提出了GemmaGuard(GGuard),一个在GuardEval上进行QLoRA微调的Gemma3-12B版本,用于评估具有细粒度标签的内容审核。我们的评估表明,GGuard实现了0.832的宏F1分数,大大优于领先的审核模型,包括OpenAI Moderator(0.64)和Llama Guard(0.61)。我们表明,以人为本的多视角安全基准对于减少有偏见和不一致的审核决策至关重要。GuardEval和GGuard共同证明,多样化的、具有代表性的数据可以显著提高复杂、边缘案例的安全性、公平性和鲁棒性。
🔬 方法详解
问题定义:现有LLM内容审核模型在处理复杂、细微的有害内容时存在困难,例如隐式冒犯、性别和种族偏见,以及对抗性攻击(越狱提示)。这些模型往往依赖于有偏见的训练数据,导致审核结果不一致,并且可能加剧社会偏见。现有基准测试集缺乏足够的多样性和细粒度,无法充分评估模型的安全性和公平性。
核心思路:论文的核心思路是构建一个更全面、更细粒度的基准数据集GuardEval,该数据集涵盖了广泛的安全、公平性和鲁棒性维度,包括人类情感、冒犯性和仇恨性语言、性别和种族偏见等。通过在该数据集上训练和评估LLM,可以提高模型在复杂场景下的内容审核能力,并减少偏见。
技术框架:论文的技术框架主要包括两个部分:GuardEval基准数据集的构建和GemmaGuard模型的训练与评估。GuardEval数据集包含106个细粒度类别,涵盖了多个安全和公平性维度。GemmaGuard模型是基于Gemma3-12B进行QLoRA微调的模型,使用GuardEval数据集进行训练。评估过程包括在GuardEval数据集上测试GemmaGuard模型以及其他领先的审核模型,并比较它们的性能指标,如宏F1分数。
关键创新:GuardEval数据集的多视角和细粒度是关键创新。与现有数据集相比,GuardEval提供了更全面的安全和公平性评估,能够更好地反映真实世界中复杂的内容审核场景。GemmaGuard模型通过在GuardEval上进行微调,显著提高了内容审核的性能,尤其是在处理复杂和细微的案例时。
关键设计:GuardEval数据集的设计考虑了多个维度,包括人类情感、冒犯性和仇恨性语言、性别和种族偏见等。数据集中的每个样本都带有细粒度的标签,以便进行更精确的评估。GemmaGuard模型使用QLoRA进行微调,这是一种高效的参数微调方法,可以在有限的计算资源下实现较好的性能。评估指标采用宏F1分数,以综合考虑模型的精确率和召回率。
🖼️ 关键图片
📊 实验亮点
GemmaGuard模型在GuardEval数据集上实现了0.832的宏F1分数,显著优于OpenAI Moderator(0.64)和Llama Guard(0.61)等领先的审核模型。这表明GuardEval数据集和GemmaGuard模型在提高LLM内容审核的安全性、公平性和鲁棒性方面具有显著优势。实验结果强调了多视角、以人为本的安全基准对于减少有偏见和不一致的审核决策的重要性。
🎯 应用场景
该研究成果可应用于各种在线平台的内容审核系统,例如社交媒体、论坛、评论区等。通过使用GuardEval数据集和GemmaGuard模型,可以提高内容审核的准确性和公平性,减少有害信息的传播,并为用户提供更安全、更友好的在线环境。未来,该研究可以扩展到其他语言和文化背景,以构建更具普适性的内容审核系统。
📄 摘要(原文)
As large language models (LLMs) become deeply embedded in daily life, the urgent need for safer moderation systems, distinguishing between naive from harmful requests while upholding appropriate censorship boundaries, has never been greater. While existing LLMs can detect harmful or unsafe content, they often struggle with nuanced cases such as implicit offensiveness, subtle gender and racial biases, and jailbreak prompts, due to the subjective and context-dependent nature of these issues. Furthermore, their heavy reliance on training data can reinforce societal biases, resulting in inconsistent and ethically problematic outputs. To address these challenges, we introduce GuardEval, a unified multi-perspective benchmark dataset designed for both training and evaluation, containing 106 fine-grained categories spanning human emotions, offensive and hateful language, gender and racial bias, and broader safety concerns. We also present GemmaGuard (GGuard), a QLoRA fine-tuned version of Gemma3-12B trained on GuardEval, to assess content moderation with fine-grained labels. Our evaluation shows that GGuard achieves a macro F1 score of 0.832, substantially outperforming leading moderation models, including OpenAI Moderator (0.64) and Llama Guard (0.61). We show that multi-perspective, human-centered safety benchmarks are critical for reducing biased and inconsistent moderation decisions. GuardEval and GGuard together demonstrate that diverse, representative data materially improve safety, fairness, and robustness on complex, borderline cases.