How well do Large Language Models Recognize Instructional Moves? Establishing Baselines for Foundation Models in Educational Discourse
作者: Kirk Vanacore, Rene F. Kizilcec
分类: cs.CL
发布日期: 2025-12-22
💡 一句话要点
评估大型语言模型在教育场景中识别教学行为的能力,并建立基线。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 教育应用 教学行为识别 prompt工程 零样本学习
📋 核心要点
- 现有研究缺乏对LLM在未经定制情况下理解真实教育场景能力的评估,这限制了其在教育领域的可靠应用。
- 该研究通过评估LLM在分类课堂教学行为任务中的表现,探索了不同prompting方法对模型性能的影响。
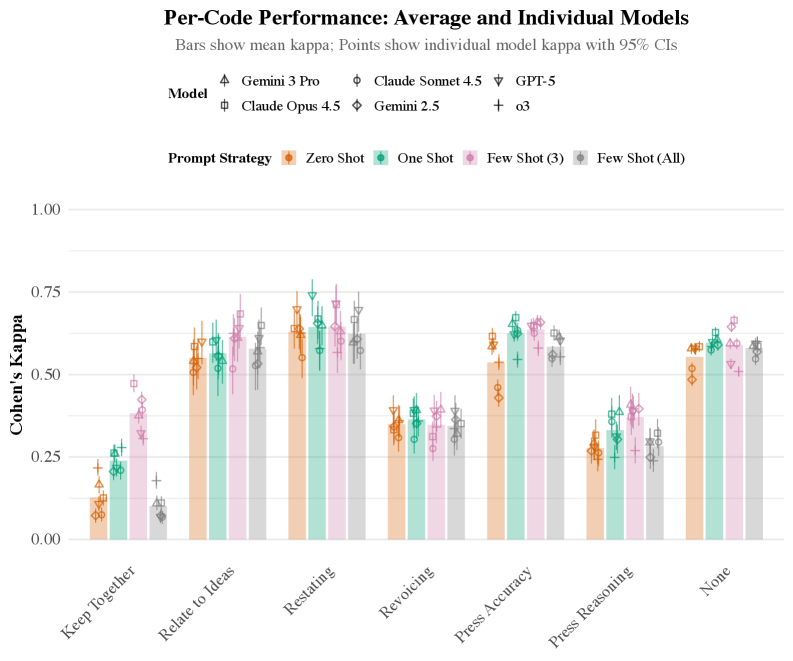
- 实验结果表明,少样本prompting能显著提升模型性能,但不同教学行为的识别效果差异大,且存在假阳性问题。
📝 摘要(中文)
大型语言模型(LLMs)越来越多地被应用于教育技术中,执行各种任务,从生成教学材料、辅助评估设计到辅导。虽然之前的工作已经研究了如何调整或优化模型以适应特定任务,但对于LLMs在没有显著定制的情况下解释真实教育场景的表现知之甚少。随着基于LLM的系统被学习者和教育者广泛应用于日常学术环境中,了解它们的开箱即用能力对于设定期望和建立基准变得越来越重要。本文比较了六个LLMs,以评估它们在一个简单但重要的任务上的基线性能:对真实课堂记录中的教学行为进行分类。我们评估了典型的提示方法:零样本、单样本和少样本提示。我们发现,虽然零样本性能一般,但提供全面的示例(少样本提示)显著提高了最先进模型的性能,最强的配置达到了Cohen's Kappa = 0.58,与专家编码的注释相比。与此同时,改进既不统一也不完整:性能因教学行为而异,较高的召回率通常以增加假阳性为代价。总的来说,这些发现表明,基础模型展示了有意义但有限的解释教学话语的能力,提示设计有助于揭示能力,但不能消除根本的可靠性限制。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLMs)在教育领域中识别教学行为的能力。现有方法主要集中在针对特定任务对LLMs进行定制或优化,而忽略了LLMs在未经显著定制的情况下,直接应用于真实教育场景时的表现。因此,如何评估LLMs的“开箱即用”能力,并建立相应的基准,成为一个亟待解决的问题。
核心思路:论文的核心思路是通过对比不同LLMs在分类课堂教学行为任务中的表现,来评估它们在教育场景中的理解能力。通过采用不同的prompting方法(零样本、单样本、少样本),研究人员旨在探究prompt设计对模型性能的影响,并分析模型在不同教学行为识别上的差异。这种方法能够帮助了解LLMs在教育领域的潜在应用价值和局限性。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 收集真实的课堂教学记录;2) 定义需要识别的教学行为类别;3) 选择多个具有代表性的大型语言模型进行评估;4) 采用不同的prompting方法(零样本、单样本、少样本)对模型进行测试;5) 将模型的预测结果与专家标注的结果进行比较,计算Cohen's Kappa等指标来评估模型性能;6) 分析模型在不同教学行为识别上的差异,以及假阳性等问题。
关键创新:该研究的关键创新在于:1) 首次系统地评估了多个LLMs在未经显著定制的情况下,直接应用于教育场景时的表现;2) 提出了通过分类课堂教学行为来评估LLMs教育领域理解能力的方法;3) 深入分析了不同prompting方法对模型性能的影响,以及模型在不同教学行为识别上的差异。
关键设计:在prompting方法上,研究采用了零样本、单样本和少样本三种策略。少样本prompting的关键在于选择具有代表性的示例,以帮助模型更好地理解任务。研究人员需要精心设计prompt的格式和内容,以确保模型能够正确地理解任务要求。此外,研究还关注了模型在不同教学行为识别上的差异,以及假阳性等问题,这有助于深入了解模型的局限性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,少样本prompting显著提升了LLM在分类课堂教学行为任务中的性能,最佳配置下Cohen's Kappa值达到0.58,与专家标注结果相比。然而,不同教学行为的识别效果差异较大,且提高召回率往往伴随着假阳性的增加。这表明LLM在教育领域的应用仍存在局限性,需要进一步优化。
🎯 应用场景
该研究成果可应用于开发智能教育系统,例如自动分析课堂教学质量、为教师提供个性化反馈、辅助学生进行自主学习等。通过提升LLM对教学行为的识别能力,可以有效提高教育资源的利用率和教学效率,并为个性化教育提供技术支持。未来的研究可以进一步探索如何利用LLM生成更有效的教学材料和评估方法。
📄 摘要(原文)
Large language models (LLMs) are increasingly adopted in educational technologies for a variety of tasks, from generating instructional materials and assisting with assessment design to tutoring. While prior work has investigated how models can be adapted or optimized for specific tasks, far less is known about how well LLMs perform at interpreting authentic educational scenarios without significant customization. As LLM-based systems become widely adopted by learners and educators in everyday academic contexts, understanding their out-of-the-box capabilities is increasingly important for setting expectations and benchmarking. We compared six LLMs to estimate their baseline performance on a simple but important task: classifying instructional moves in authentic classroom transcripts. We evaluated typical prompting methods: zero-shot, one-shot, and few-shot prompting. We found that while zero-shot performance was moderate, providing comprehensive examples (few-shot prompting) significantly improved performance for state-of-the-art models, with the strongest configuration reaching Cohen's Kappa = 0.58 against expert-coded annotations. At the same time, improvements were neither uniform nor complete: performance varied considerably by instructional move, and higher recall frequently came at the cost of increased false positives. Overall, these findings indicate that foundation models demonstrate meaningful yet limited capacity to interpret instructional discourse, with prompt design helping to surface capability but not eliminating fundamental reliability constraints.