HARMON-E: Hierarchical Agentic Reasoning for Multimodal Oncology Notes to Extract Structured Data
作者: Shashi Kant Gupta, Arijeet Pramanik, Jerrin John Thomas, Regina Schwind, Lauren Wiener, Avi Raju, Jeremy Kornbluth, Yanshan Wang, Zhaohui Su, Hrituraj Singh
分类: cs.CL, cs.AI
发布日期: 2025-12-22 (更新: 2025-12-26)
备注: 39 Pages, Supplementary Included
💡 一句话要点
提出HARMON-E,利用层级Agentic推理从多模态肿瘤病历中抽取结构化数据
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 肿瘤数据提取 Agentic框架 大型语言模型 电子病历 结构化数据
📋 核心要点
- 现有肿瘤数据抽取方法难以处理病历的复杂性和矛盾信息,限制了其在实际临床场景中的应用。
- HARMON-E采用层级Agentic推理框架,利用LLM的推理能力,将复杂任务分解为模块化的自适应子任务。
- 实验表明,HARMON-E在大型真实数据集上实现了高精度的数据抽取,显著降低了人工标注成本。
📝 摘要(中文)
电子病历(EHR)中的非结构化病历包含丰富的临床信息,对癌症治疗决策和研究至关重要。然而,由于其广泛的变异性、专业术语和不一致的文档格式,可靠地提取结构化肿瘤数据仍然具有挑战性。手动提取虽然准确,但成本高昂且难以扩展。现有的自动化方法通常只关注狭窄的场景,例如使用合成数据集、限制于文档级别的提取或隔离特定的临床变量(如分期、生物标志物、组织学),并且不能充分处理包含矛盾信息的多个临床文档中的患者级别综合。本研究提出了一种Agentic框架,该框架系统地将复杂的肿瘤数据提取分解为模块化、自适应的任务。具体来说,我们使用大型语言模型(LLM)作为推理Agent,配备上下文敏感的检索和迭代综合能力,以详尽和全面地从真实世界的肿瘤病历中提取结构化临床变量。在一个包含超过40万份非结构化临床病历和2250名癌症患者的扫描PDF报告的大规模数据集上进行评估,我们的方法实现了0.93的平均F1分数,其中103个肿瘤特异性临床变量中的100个超过0.85,关键变量(如生物标志物和药物)超过0.95。此外,将Agentic系统集成到数据管理工作流程中,直接手动批准率达到0.94,显著降低了注释成本。据我们所知,这是基于LLM的Agent首次大规模地进行结构化肿瘤数据提取的全面端到端应用。
🔬 方法详解
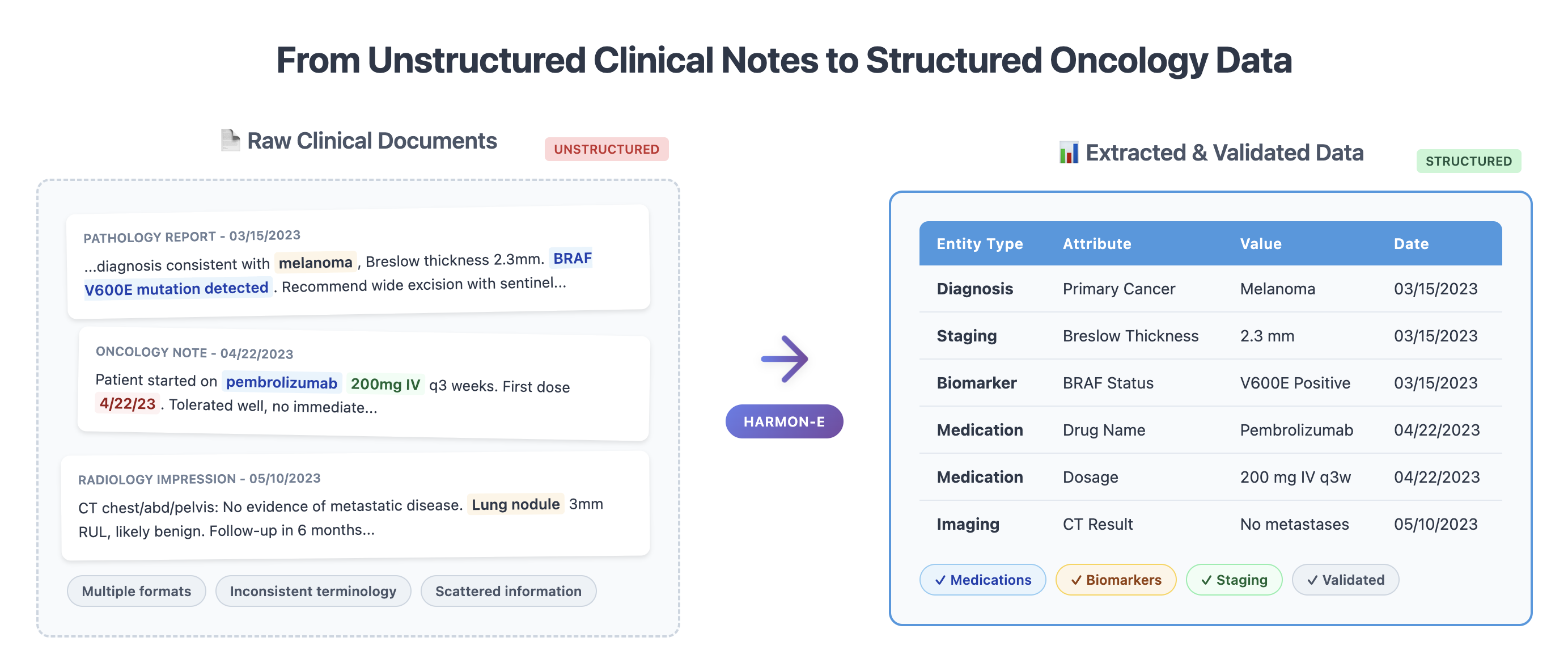
问题定义:论文旨在解决从大量非结构化肿瘤病历中自动、准确、全面地提取结构化临床数据的难题。现有方法通常只能处理特定类型的文档或临床变量,无法有效整合来自多个文档的矛盾信息,且依赖人工标注,成本高昂。
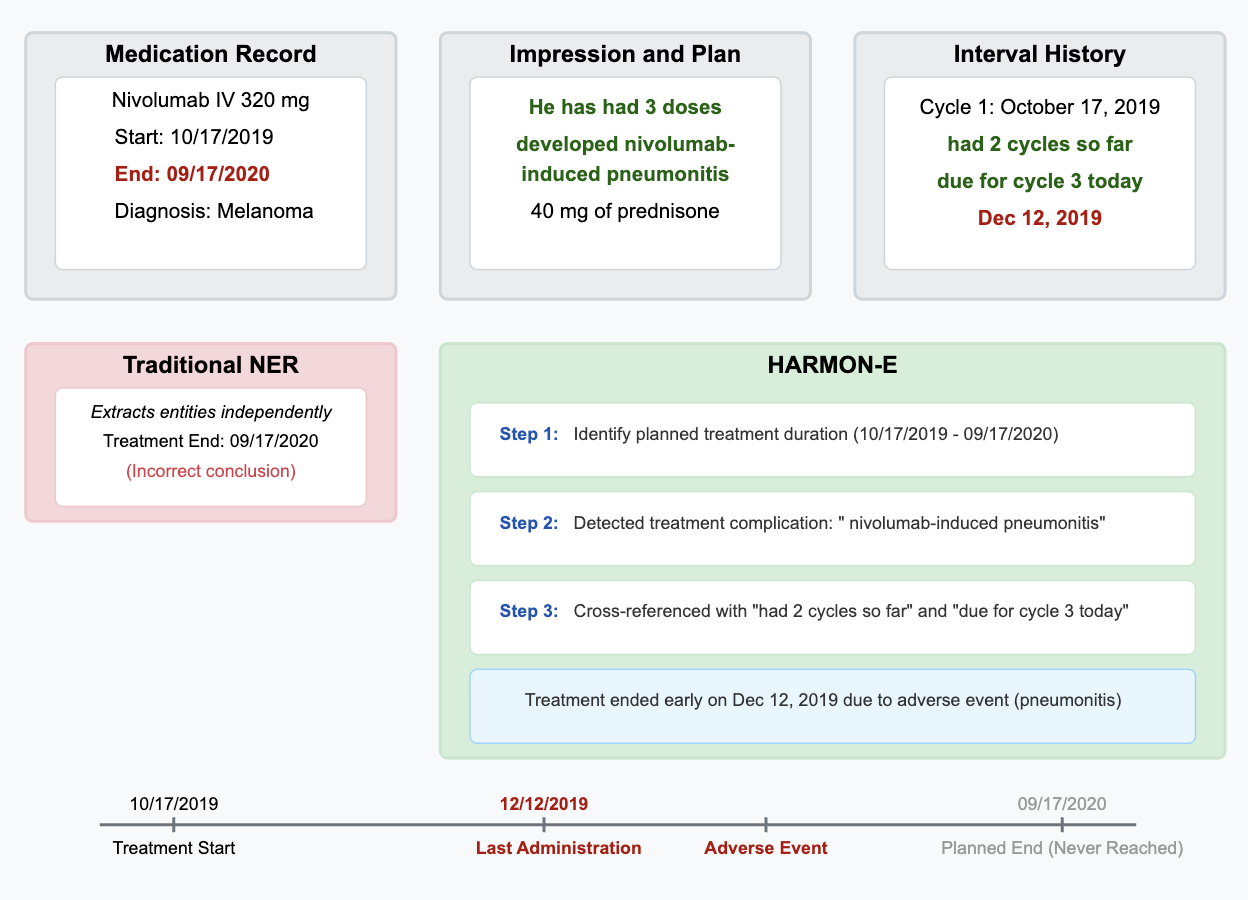
核心思路:论文的核心思路是将复杂的肿瘤数据提取任务分解为多个由LLM驱动的Agent负责的模块化子任务。每个Agent专注于特定的临床变量或文档类型,并通过上下文感知的检索和迭代综合来提高提取的准确性和完整性。这种层级结构允许系统处理文档间的矛盾信息,并最终生成患者级别的综合数据。
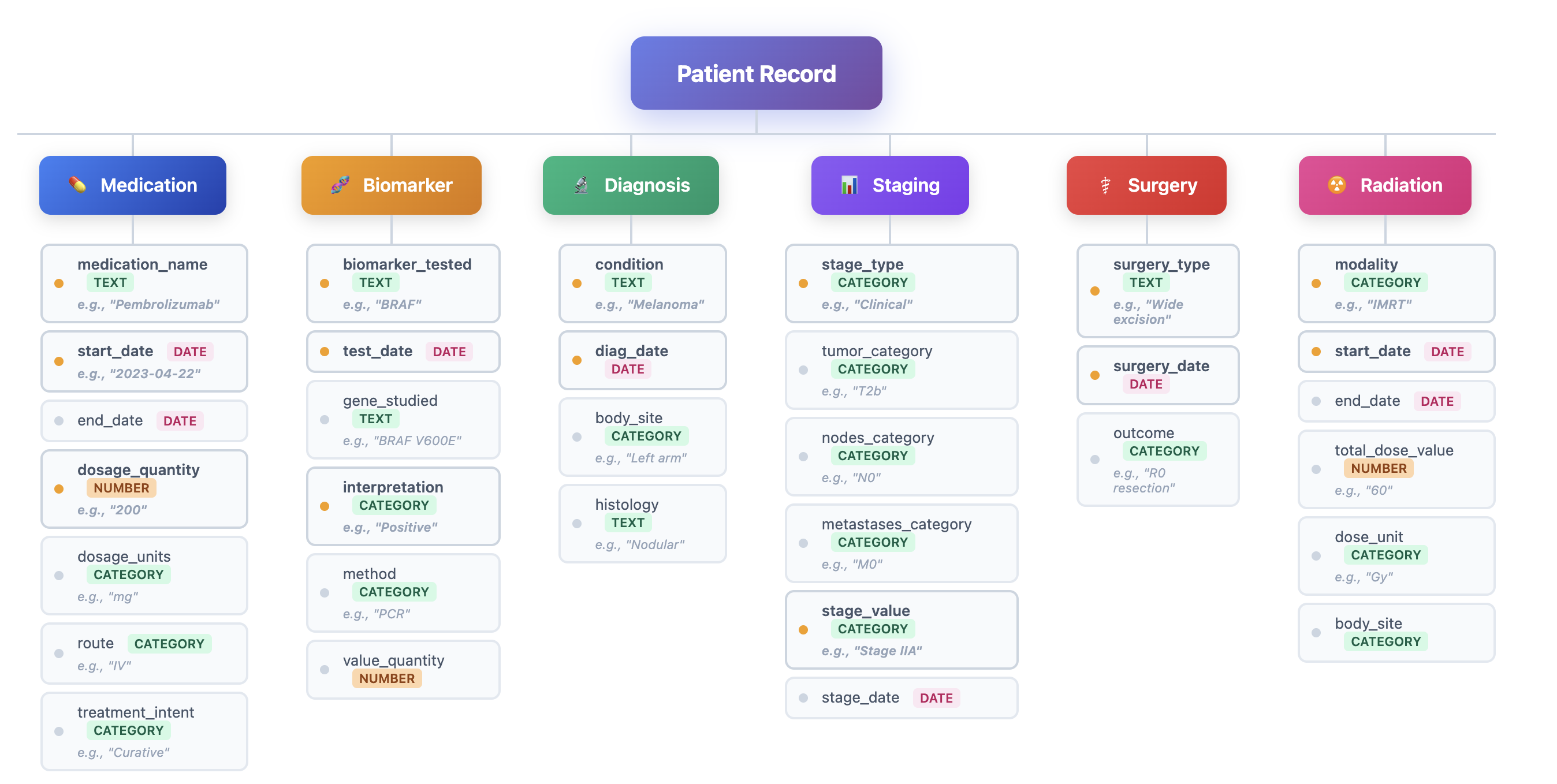
技术框架:HARMON-E框架包含以下主要模块:1) 文档检索模块,根据上下文信息检索相关的病历文档;2) Agent池,包含多个LLM驱动的Agent,每个Agent负责提取特定的临床变量;3) 知识库,存储已提取的临床信息和相关知识;4) 综合模块,整合来自不同Agent和文档的信息,解决矛盾,生成最终的结构化数据。整个流程是迭代的,Agent之间可以相互协作,不断完善提取结果。
关键创新:该论文的关键创新在于将Agentic框架应用于肿瘤数据提取,并利用LLM的推理能力来处理复杂和不一致的临床信息。与传统的基于规则或机器学习的方法相比,HARMON-E能够更好地理解自然语言文本,并进行上下文推理,从而提高提取的准确性和鲁棒性。
关键设计:论文中使用了预训练的LLM作为Agent的核心,并针对肿瘤数据提取任务进行了微调。Agent的设计考虑了上下文信息,例如病人的病史和治疗方案。此外,论文还设计了一种迭代综合算法,用于解决文档间的矛盾信息,并生成患者级别的综合数据。具体的参数设置、损失函数和网络结构等技术细节在论文中没有详细描述,属于未知信息。
🖼️ 关键图片
📊 实验亮点
HARMON-E在包含超过40万份非结构化临床病历的大规模数据集上进行了评估,实现了0.93的平均F1分数。其中,103个肿瘤特异性临床变量中的100个超过0.85,关键变量(如生物标志物和药物)超过0.95。与人工标注相比,HARMON-E显著降低了标注成本,直接手动批准率达到0.94。
🎯 应用场景
该研究成果可应用于临床决策支持、癌症研究和药物开发等领域。通过自动提取和整合肿瘤病历中的结构化数据,可以帮助医生更好地了解患者的病情,制定个性化的治疗方案,并加速新药的研发过程。此外,该方法还可以用于构建大规模的肿瘤数据库,为癌症流行病学研究提供数据支持。
📄 摘要(原文)
Unstructured notes within the electronic health record (EHR) contain rich clinical information vital for cancer treatment decision making and research, yet reliably extracting structured oncology data remains challenging due to extensive variability, specialized terminology, and inconsistent document formats. Manual abstraction, although accurate, is prohibitively costly and unscalable. Existing automated approaches typically address narrow scenarios - either using synthetic datasets, restricting focus to document-level extraction, or isolating specific clinical variables (e.g., staging, biomarkers, histology) - and do not adequately handle patient-level synthesis across the large number of clinical documents containing contradictory information. In this study, we propose an agentic framework that systematically decomposes complex oncology data extraction into modular, adaptive tasks. Specifically, we use large language models (LLMs) as reasoning agents, equipped with context-sensitive retrieval and iterative synthesis capabilities, to exhaustively and comprehensively extract structured clinical variables from real-world oncology notes. Evaluated on a large-scale dataset of over 400,000 unstructured clinical notes and scanned PDF reports spanning 2,250 cancer patients, our method achieves an average F1-score of 0.93, with 100 out of 103 oncology-specific clinical variables exceeding 0.85, and critical variables (e.g., biomarkers and medications) surpassing 0.95. Moreover, integration of the agentic system into a data curation workflow resulted in 0.94 direct manual approval rate, significantly reducing annotation costs. To our knowledge, this constitutes the first exhaustive, end-to-end application of LLM-based agents for structured oncology data extraction at scale