GenEnv: Difficulty-Aligned Co-Evolution Between LLM Agents and Environment Simulators
作者: Jiacheng Guo, Ling Yang, Peter Chen, Qixin Xiao, Yinjie Wang, Xinzhe Juan, Jiahao Qiu, Ke Shen, Mengdi Wang
分类: cs.CL
发布日期: 2025-12-22 (更新: 2025-12-23)
备注: Our codes are available at https://github.com/Gen-Verse/GenEnv
💡 一句话要点
GenEnv:通过LLM智能体与环境模拟器的难度对齐协同进化,提升智能体性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM智能体 协同进化 环境模拟器 课程学习 难度对齐
📋 核心要点
- 现有LLM智能体训练受限于真实世界交互数据的高成本和静态性,难以有效提升智能体能力。
- GenEnv通过构建智能体与环境模拟器的协同进化机制,动态生成难度与智能体能力相匹配的任务。
- 实验表明,GenEnv在多个基准测试中显著提升了智能体性能,且数据效率优于离线数据增强方法。
📝 摘要(中文)
本文提出GenEnv框架,旨在解决训练高性能大语言模型(LLM)智能体时,真实世界交互数据成本高昂且静态的瓶颈问题。GenEnv建立了一个智能体与可扩展的生成式环境模拟器之间难度对齐的协同进化博弈。与在静态数据集上进化模型的传统方法不同,GenEnv实例化了一种数据进化过程:模拟器充当动态课程策略,持续生成专门为智能体的“近端发展区”量身定制的任务。这一过程由一个简单但有效的α-课程奖励引导,该奖励将任务难度与智能体当前的能力对齐。在API-Bank、ALFWorld、BFCL、Bamboogle和TravelPlanner五个基准测试中,GenEnv将智能体性能提高了高达+40.3%,超过了7B基线模型,并达到或超过了更大模型的平均性能。与基于Gemini 2.5 Pro的离线数据增强相比,GenEnv在数据使用量减少3.3倍的情况下实现了更好的性能。通过从静态监督转向自适应模拟,GenEnv为扩展智能体能力提供了一条数据高效的途径。
🔬 方法详解
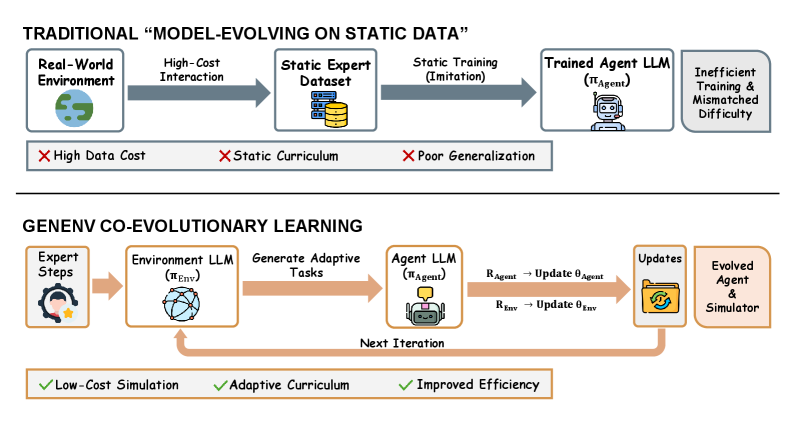
问题定义:现有的大语言模型智能体训练方法依赖于静态的、成本高昂的真实世界交互数据。这种静态性限制了智能体学习的范围和适应性,难以有效提升智能体的泛化能力和解决复杂问题的能力。因此,如何以更低的成本和更高的效率生成多样化的、具有挑战性的训练数据,是当前LLM智能体训练面临的关键问题。
核心思路:GenEnv的核心思路是建立一个智能体与环境模拟器之间的协同进化博弈。智能体负责解决环境模拟器生成的任务,而环境模拟器则根据智能体的表现动态调整任务的难度,从而形成一个难度对齐的课程学习过程。这种协同进化机制使得智能体能够持续学习新的知识和技能,并逐步提升解决问题的能力。
技术框架:GenEnv框架主要包含两个核心模块:智能体和环境模拟器。智能体负责接收环境模拟器生成的任务,并根据任务的要求采取相应的行动。环境模拟器则负责生成任务,并根据智能体的表现调整任务的难度。框架使用α-课程奖励来引导环境模拟器生成难度与智能体能力相匹配的任务。整个过程是一个迭代循环,智能体不断学习新的知识和技能,环境模拟器不断生成更具挑战性的任务。
关键创新:GenEnv的关键创新在于其协同进化的框架设计和难度对齐的课程学习机制。与传统的静态数据集训练方法不同,GenEnv能够动态生成训练数据,并根据智能体的表现调整任务的难度,从而实现更高效的训练。此外,α-课程奖励的设计使得环境模拟器能够更好地理解智能体的能力,并生成更具针对性的任务。
关键设计:α-课程奖励是GenEnv中的一个关键设计。它通过一个简单的公式来计算任务的难度,并根据智能体在任务上的表现来调整任务的难度。具体来说,如果智能体成功解决了任务,则降低任务的难度;如果智能体未能解决任务,则提高任务的难度。这种动态调整机制使得环境模拟器能够生成难度与智能体能力相匹配的任务,从而实现更高效的训练。
🖼️ 关键图片


📊 实验亮点
GenEnv在五个基准测试中表现出色,相较于7B参数的基线模型,性能提升高达40.3%。在数据效率方面,GenEnv优于基于Gemini 2.5 Pro的离线数据增强方法,在仅使用其1/3.3数据量的情况下,取得了更好的性能。这些结果表明,GenEnv是一种有效且数据高效的LLM智能体训练方法。
🎯 应用场景
GenEnv框架具有广泛的应用前景,可应用于各种需要智能体与环境交互的场景,例如游戏AI、机器人控制、自动驾驶等。通过GenEnv,可以更高效地训练出具有更强泛化能力和解决复杂问题能力的智能体,从而推动人工智能技术的发展和应用。
📄 摘要(原文)
Training capable Large Language Model (LLM) agents is critically bottlenecked by the high cost and static nature of real-world interaction data. We address this by introducing GenEnv, a framework that establishes a difficulty-aligned co-evolutionary game between an agent and a scalable, generative environment simulator. Unlike traditional methods that evolve models on static datasets, GenEnv instantiates a dataevolving: the simulator acts as a dynamic curriculum policy, continuously generating tasks specifically tailored to the agent's ``zone of proximal development''. This process is guided by a simple but effective $α$-Curriculum Reward, which aligns task difficulty with the agent's current capabilities. We evaluate GenEnv on five benchmarks, including API-Bank, ALFWorld, BFCL, Bamboogle, and TravelPlanner. Across these tasks, GenEnv improves agent performance by up to \textbf{+40.3\%} over 7B baselines and matches or exceeds the average performance of larger models. Compared to Gemini 2.5 Pro-based offline data augmentation, GenEnv achieves better performance while using 3.3$\times$ less data. By shifting from static supervision to adaptive simulation, GenEnv provides a data-efficient pathway for scaling agent capabilities.