SiamGPT: Quality-First Fine-Tuning for Stable Thai Text Generation
作者: Thittipat Pairatsuppawat, Abhibhu Tachaapornchai, Paweekorn Kusolsomboon, Chutikan Chaiwong, Thodsaporn Chay-intr, Kobkrit Viriyayudhakorn, Nongnuch Ketui, Aslan B. Wong
分类: cs.CL
发布日期: 2025-12-22 (更新: 2026-01-08)
💡 一句话要点
SiamGPT:面向稳定泰语文本生成的质量优先微调方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 泰语自然语言处理 大型语言模型 指令微调 质量优先 多轮对话
📋 核心要点
- 尽管在英语方面表现出色,但开源大型语言模型在复杂指令下生成不稳定,难以部署于泰语环境。
- SiamGPT采用质量优先的微调策略,结合高质量英语指令数据和泰语适配的AutoIF框架,提升模型性能。
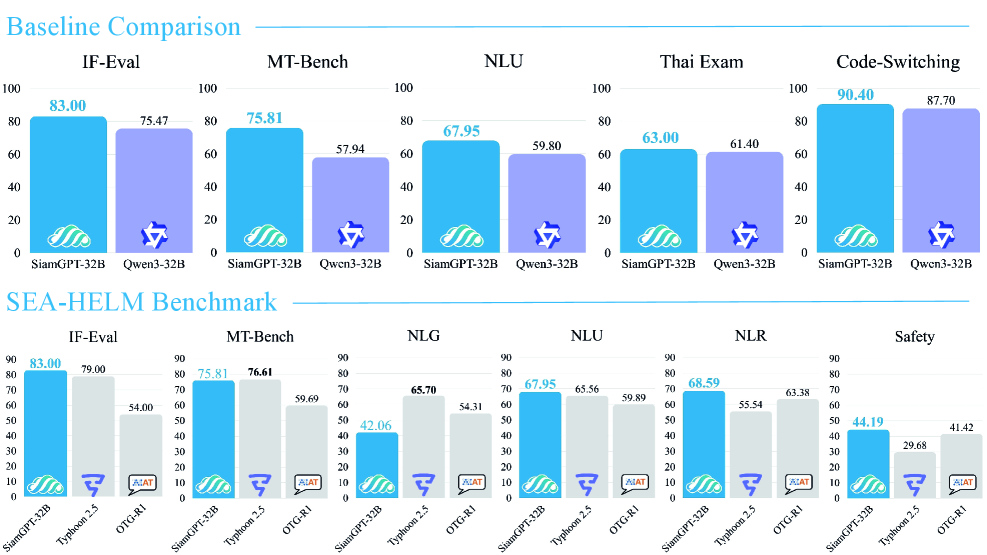
- 实验表明,SiamGPT在指令遵循、多轮对话和语言稳定性方面均有显著提升,并在SEA-HELM基准测试中表现出色。
📝 摘要(中文)
本文提出了SiamGPT-32B,一个基于Qwen3-32B的开源模型,通过“质量优先”策略进行微调,该策略强调精心策划的监督数据而非数据规模。该微调流程结合了高复杂度的英语指令数据和一个泰语适配的AutoIF框架,用于指令和语言约束。仅使用监督微调,无需持续预训练或语料库扩展,SiamGPT-32B提高了指令遵循、多轮对话鲁棒性和语言稳定性。在SEA-HELM基准测试中的评估表明,SiamGPT-32B在同等规模的开源泰语模型中实现了最强的整体性能,并在指令遵循、多轮对话和自然语言理解方面取得了持续的提升。
🔬 方法详解
问题定义:现有开源大型语言模型在泰语环境下的部署面临挑战,主要原因是模型在处理复杂指令时生成文本不稳定,指令遵循能力不足,多轮对话鲁棒性较差,且语言表达不够自然流畅。现有方法通常依赖于大规模数据进行训练,但忽略了数据质量的重要性。
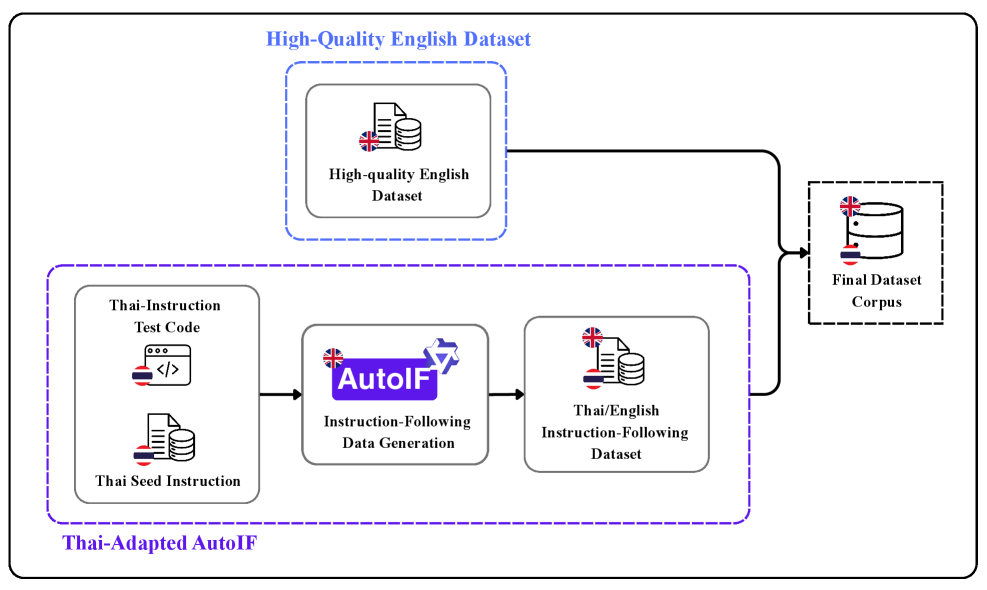
核心思路:SiamGPT的核心思路是采用“质量优先”的微调策略,即更加注重训练数据的质量而非数量。通过精心筛选和构建高质量的指令数据,并结合泰语适配的AutoIF框架,从而提高模型在泰语环境下的指令遵循能力、多轮对话鲁棒性和语言稳定性。
技术框架:SiamGPT的整体框架包括以下几个主要步骤:1) 基于Qwen3-32B构建初始模型;2) 收集和筛选高质量的英语指令数据;3) 将英语指令数据翻译并适配到泰语环境;4) 利用泰语适配的AutoIF框架进行指令和语言约束;5) 使用监督微调方法对模型进行训练。
关键创新:SiamGPT的关键创新在于其“质量优先”的微调策略。与传统方法不同,SiamGPT更加注重训练数据的质量,通过精心策划和筛选高质量的指令数据,从而在不增加数据规模的情况下,显著提升模型在泰语环境下的性能。此外,泰语适配的AutoIF框架也为模型提供了更强的指令和语言约束能力。
关键设计:SiamGPT的关键设计包括:1) 精心设计的指令数据集,涵盖各种复杂场景和任务;2) 泰语适配的AutoIF框架,用于指令和语言约束;3) 监督微调方法,用于优化模型参数。具体的参数设置、损失函数和网络结构等细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
SiamGPT-32B在SEA-HELM基准测试中表现出色,在同等规模的开源泰语模型中取得了最强的整体性能。具体而言,SiamGPT在指令遵循、多轮对话和自然语言理解方面均取得了显著的提升。这些实验结果表明,SiamGPT的“质量优先”微调策略是有效的,能够显著提高模型在泰语环境下的性能。
🎯 应用场景
SiamGPT可应用于各种泰语自然语言处理任务,例如智能客服、聊天机器人、文本摘要、机器翻译等。该研究成果有助于推动泰语自然语言处理技术的发展,并为泰语用户提供更智能、更便捷的服务。未来,SiamGPT有望在教育、医疗、金融等领域发挥重要作用。
📄 摘要(原文)
Open-weights large language models remain difficult to deploy for Thai due to unstable generation under complex instructions, despite strong English performance. To mitigate these limitations, We present SiamGPT-32B, an open-weights model based on Qwen3-32B, fine-tuned with a Quality-First strategy emphasizing curated supervision over data scale. The fine-tuning pipeline combines high-complexity English instruction data with a Thai-adapted AutoIF framework for instruction and linguistic constraints. Using supervised fine-tuning only, without continual pretraining or corpus expansion, SiamGPT-32B improves instruction adherence, multi-turn robustness, and linguistic stability. Evaluations on the SEA-HELM benchmark show that SiamGPT-32B achieves the strongest overall performance among similar-scale open-weights Thai models, with consistent gains in instruction following, multi-turn dialogue, and natural language understanding.