AWPO: Enhancing Tool-Use of Large Language Models through Adaptive Integration of Reasoning Rewards
作者: Zihan Lin, Xiaohan Wang, Hexiong Yang, Jiajun Chai, Jie Cao, Guojun Yin, Wei Lin, Ran He
分类: cs.CL
发布日期: 2025-12-22 (更新: 2026-01-15)
💡 一句话要点
提出AWPO,通过自适应融合推理奖励提升大语言模型工具使用能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 工具使用 强化学习 推理奖励 策略优化
📋 核心要点
- 现有方法在训练工具使用的大语言模型时,未能充分利用基于思维链质量的推理奖励。
- AWPO通过自适应地将推理奖励融入优势估计,并结合方差感知门控和难度感知加权来解决该问题。
- 实验结果表明,AWPO在多个工具使用基准测试中取得了领先性能,并在多轮场景中超越了闭源模型。
📝 摘要(中文)
本文提出了一种名为优势加权策略优化(AWPO)的强化学习框架,旨在通过自适应地将推理奖励融入优势估计中,从而提升大语言模型(LLM)的工具使用性能。现有方法主要依赖可验证的结果奖励来训练工具使用的LLM,但忽略了基于思维链质量的推理奖励的潜力。简单地结合推理奖励和结果奖励可能导致次优性能或与主要优化目标冲突。AWPO通过方差感知门控和难度感知加权,基于群体相对统计量自适应地调节来自推理信号的优势,并采用定制的裁剪机制以实现稳定的优化。大量实验表明,AWPO在标准工具使用基准测试中取得了最先进的性能,显著优于强大的基线模型,并在具有挑战性的多轮场景中领先于闭源模型。值得注意的是,凭借卓越的参数效率,我们的4B模型在多轮准确率方面超越Grok-4达16.0%,同时保持了对分布外MMLU-Pro基准的泛化能力。
🔬 方法详解
问题定义:现有强化学习方法在训练大语言模型使用工具时,主要依赖于可验证的结果奖励,而忽略了思维链质量带来的推理奖励。简单地将结果奖励和推理奖励结合,可能导致性能下降,甚至与优化目标冲突。因此,如何有效地利用推理奖励来提升工具使用能力是一个关键问题。
核心思路:AWPO的核心思路是自适应地将推理奖励融入到优势函数估计中。通过这种方式,模型可以学习到哪些推理步骤对于最终结果是有益的,从而更好地利用工具。自适应性体现在对不同质量的推理过程给予不同的权重,避免低质量的推理过程干扰模型的学习。
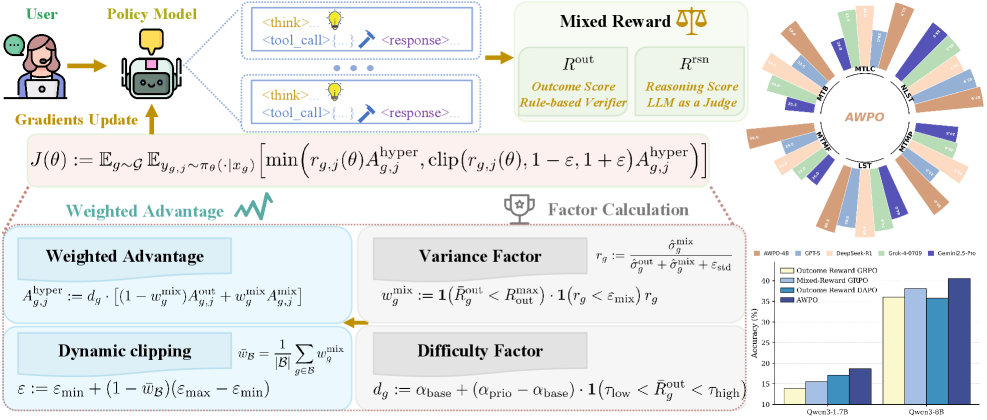
技术框架:AWPO框架主要包含以下几个模块:1) 大语言模型作为策略网络,负责生成工具使用策略;2) 环境模拟器,用于模拟工具的使用过程并提供反馈;3) 奖励函数,包括结果奖励和推理奖励;4) 优势函数估计器,用于估计每个动作的优势;5) 策略优化器,使用优势加权策略优化算法更新策略网络。整个流程是,模型根据当前状态生成动作,环境模拟器执行动作并返回新的状态和奖励,优势函数估计器根据奖励估计优势,策略优化器根据优势更新策略。
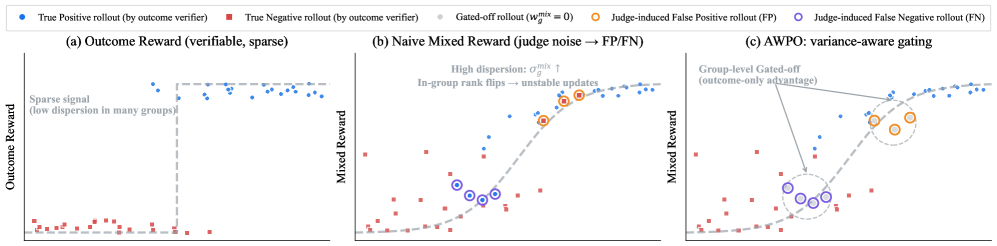
关键创新:AWPO的关键创新在于自适应地融合推理奖励。具体来说,它引入了方差感知门控和难度感知加权机制。方差感知门控根据群体相对统计量来调节推理信号的优势,避免了方差过大的推理信号对模型产生负面影响。难度感知加权则根据任务的难度来调整推理奖励的权重,使得模型能够更好地学习到困难任务的推理过程。
关键设计:AWPO的关键设计包括:1) 方差感知门控:使用sigmoid函数对推理奖励进行门控,门控系数由推理奖励的方差决定;2) 难度感知加权:根据任务的难度系数调整推理奖励的权重;3) 定制的裁剪机制:为了保证训练的稳定性,AWPO采用了一种定制的裁剪机制,限制策略更新的幅度。
🖼️ 关键图片
📊 实验亮点
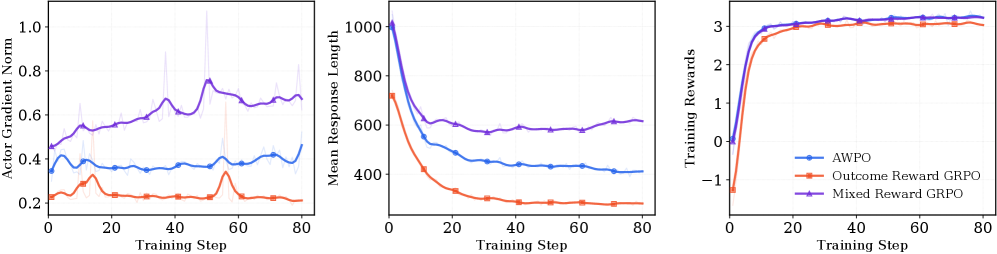
AWPO在标准工具使用基准测试中取得了state-of-the-art的性能,显著优于强基线模型。特别是在多轮场景中,AWPO的4B模型超越了Grok-4达16.0%的多轮准确率。此外,AWPO还保持了良好的泛化能力,在分布外的MMLU-Pro基准测试中表现出色。这些结果表明,AWPO能够有效地提升大语言模型的工具使用能力。
🎯 应用场景
AWPO具有广泛的应用前景,可以应用于各种需要大语言模型进行工具使用的场景,例如智能客服、自动化报告生成、代码生成等。通过提升大语言模型的工具使用能力,可以显著提高工作效率和质量,降低人工成本。未来,AWPO还可以扩展到其他类型的任务,例如多模态任务和机器人控制。
📄 摘要(原文)
While Reinforcement Learning (RL) shows promise in training tool-use Large Language Models (LLMs) using verifiable outcome rewards, existing methods largely overlook the potential of reasoning rewards based on chain-of-thought quality for better tool utilization. Furthermore, naïvely combining reasoning and outcome rewards may yield suboptimal performance or conflict with the primary optimization objective. To address this, we propose Advantage-Weighted Policy Optimization (AWPO), a principled RL framework that adaptively integrates reasoning rewards into advantage estimation to improve tool-use performance. AWPO incorporates variance-aware gating and difficulty-aware weighting to adaptively modulate advantages from reasoning signals based on group-relative statistics, alongside a tailored clipping mechanism for stable optimization. Extensive experiments demonstrate that AWPO achieves state-of-the-art performance across standard tool-use benchmarks, significantly outperforming strong baselines and leading closed-source models in challenging multi-turn scenarios. Notably, with exceptional parameter efficiency, our 4B model surpasses Grok-4 by $16.0\%$ in multi-turn accuracy while preserving generalization capability on the out-of-distribution MMLU-Pro benchmark.