Rubric-Conditioned LLM Grading: Alignment, Uncertainty, and Robustness
作者: Haotian Deng, Chris Farber, Jiyoon Lee, David Tang
分类: cs.CL, cs.LG
发布日期: 2025-12-21
💡 一句话要点
提出基于规则条件的大语言模型评分框架,评估其对简答题的评分能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动简答题评分 大型语言模型 评分细则 不确定性估计 鲁棒性测试 Qwen SciEntsBank
📋 核心要点
- 自动简答题评分面临学生答案多样性和评分细则对齐的挑战,现有方法难以兼顾。
- 利用大语言模型(LLM)作为评分员,通过规则条件约束,实现自动评分。
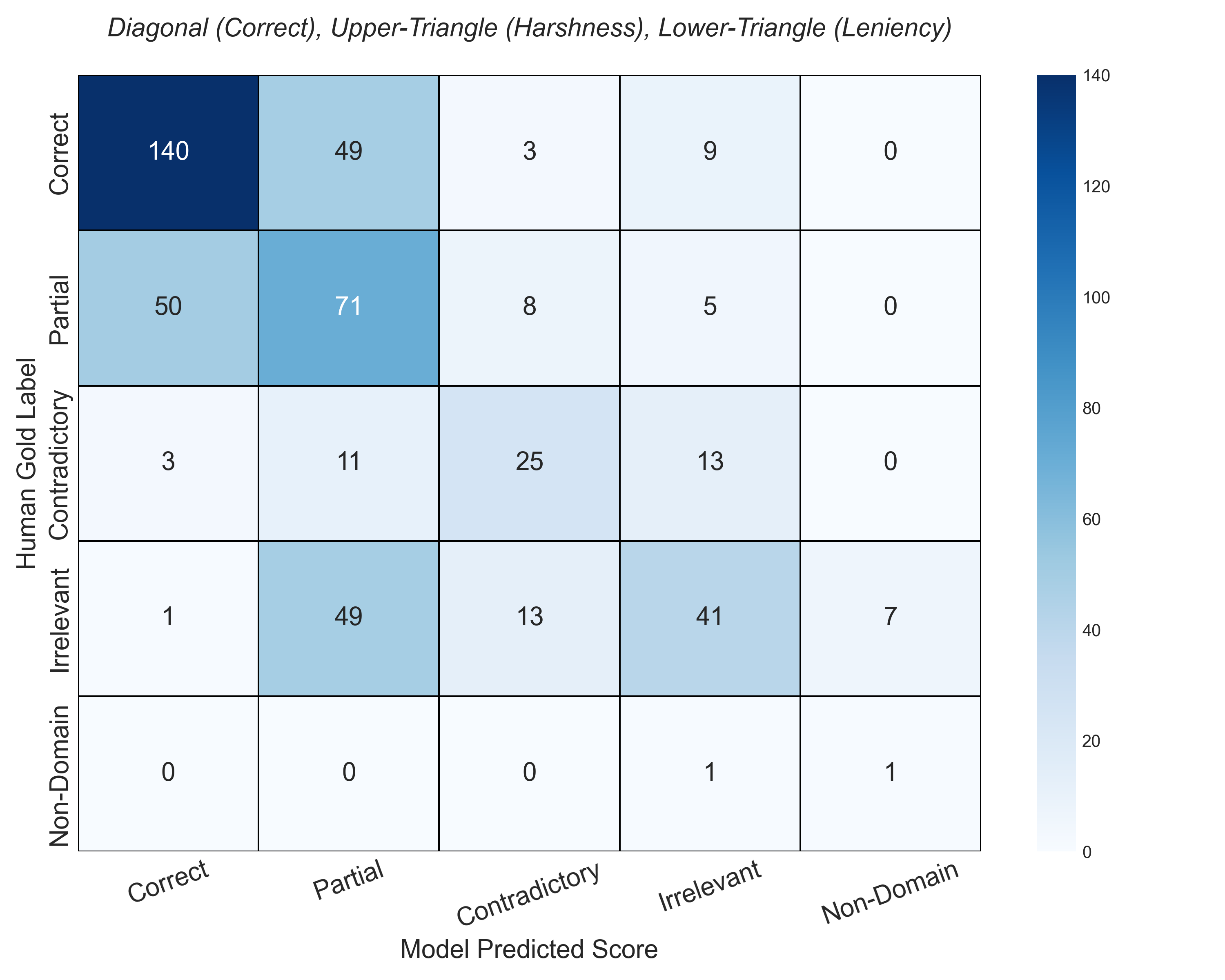
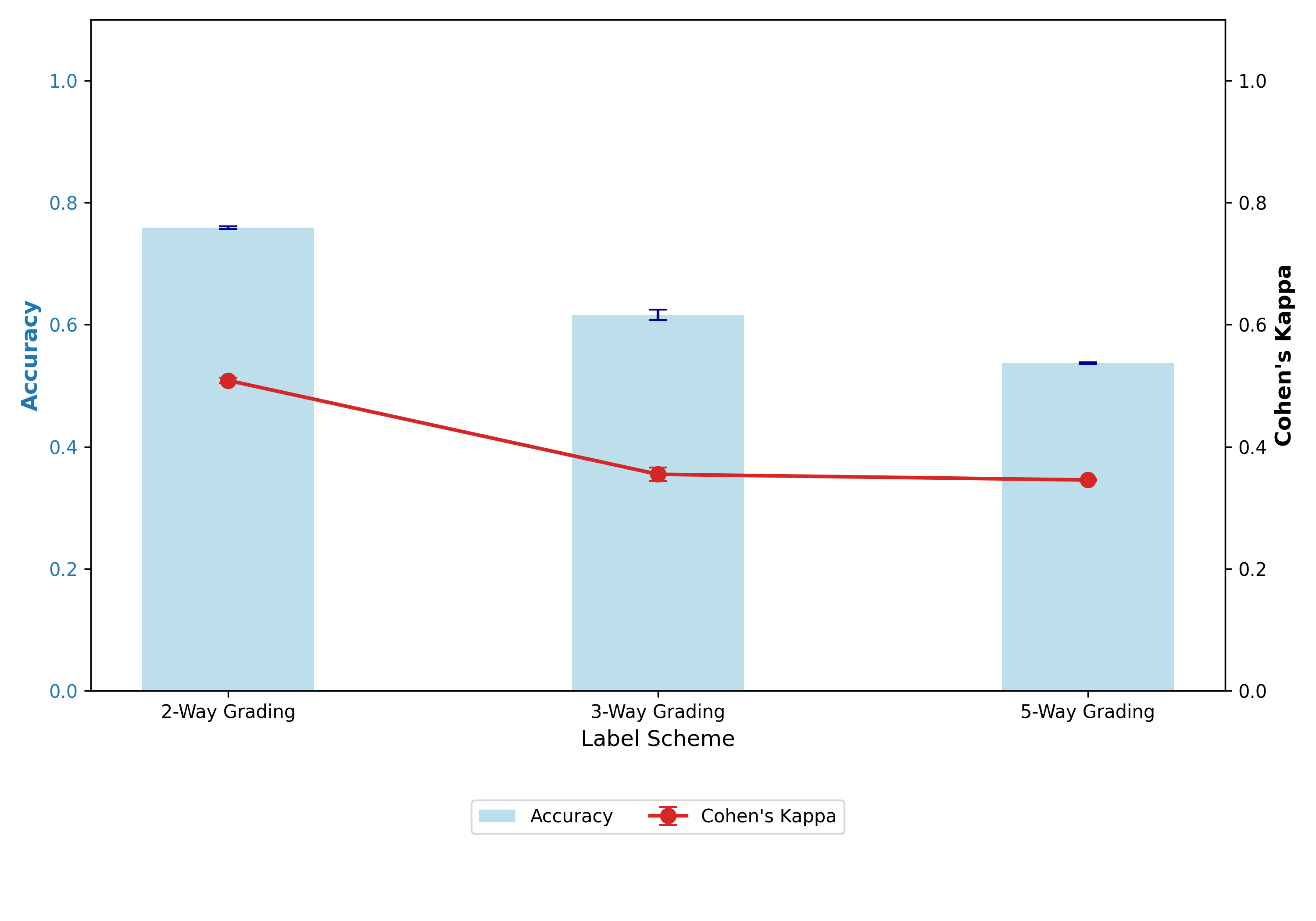
- 实验表明,LLM在二元任务中对齐性好,但规则粒度增加时下降,且对同义词替换敏感。
📝 摘要(中文)
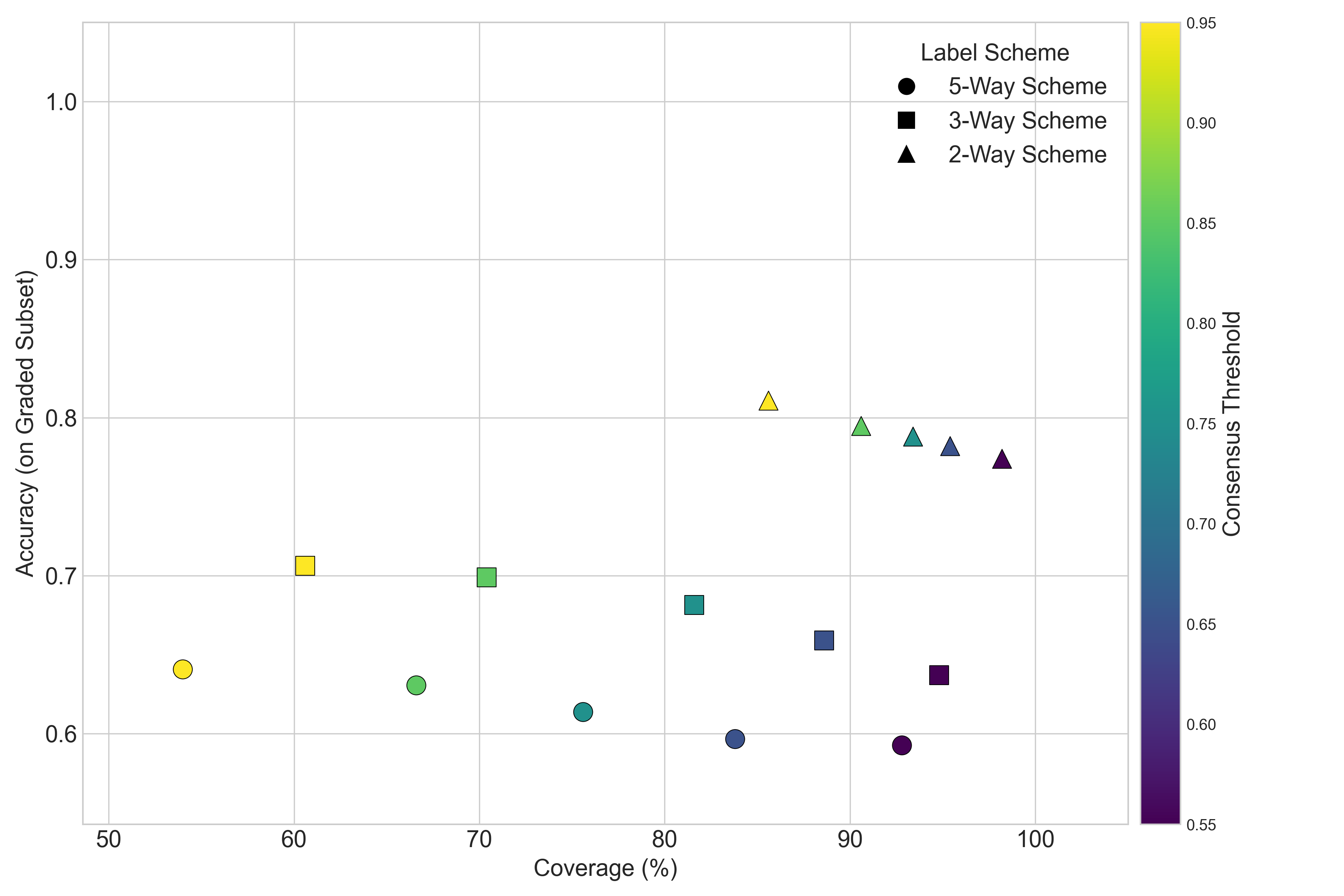
自动简答题评分(ASAG)仍然是一项具有挑战性的任务,因为它涉及到学生答案的语言多样性以及对齐评分细则的细致部分评分需求。虽然大型语言模型(LLM)提供了一个有希望的解决方案,但它们作为基于规则的自动评分员的可靠性需要严格评估。本文系统地评估了LLM评分员在基于规则的简答题评分中的表现。我们研究了三个关键方面:LLM评分与专家判断在不同规则复杂度下的对齐程度,基于共识的延迟机制所促进的不确定性与准确性之间的权衡,以及模型在随机输入扰动和对抗攻击下的鲁棒性。使用SciEntsBank基准和Qwen 2.5-72B,我们发现对于二元任务,对齐性很强,但随着规则粒度的增加而降低。我们的“信任曲线”分析表明,过滤低置信度预测可以提高剩余子集的准确性。此外,鲁棒性实验表明,虽然该模型对提示注入具有弹性,但对同义词替换很敏感。我们的工作为基于规则条件的大语言模型评分员的能力和局限性提供了重要的见解,突出了不确定性估计和鲁棒性测试对于可靠部署的重要性。
🔬 方法详解
问题定义:论文旨在解决自动简答题评分(ASAG)中,如何利用大型语言模型(LLM)实现更准确、更可靠的评分,尤其是在需要遵循详细评分细则(rubric)的情况下。现有方法难以处理学生答案的语言多样性,并且难以保证评分与评分细则的高度一致性。此外,现有方法缺乏对评分不确定性的有效评估,以及对输入扰动的鲁棒性分析。
核心思路:论文的核心思路是利用LLM作为评分员,并以评分细则作为条件输入,引导LLM进行评分。通过分析LLM评分的不确定性,并结合共识机制,提高评分的准确性。同时,通过对抗攻击等手段,评估LLM评分的鲁棒性。这种方法旨在提升LLM在复杂评分场景下的可靠性和实用性。
技术框架:整体框架包括以下几个主要阶段:1) 数据准备:使用SciEntsBank基准数据集,包含简答题和对应的评分细则。2) 模型构建:使用Qwen 2.5-72B作为基础LLM。3) 评分过程:将问题、学生答案和评分细则作为输入,输入到LLM中,得到评分结果。4) 不确定性评估:通过多次采样,评估LLM评分的不确定性。5) 鲁棒性测试:通过随机输入扰动和对抗攻击,评估LLM评分的鲁棒性。
关键创新:论文的关键创新在于:1) 系统性地评估了LLM作为评分员在不同评分细则复杂度下的表现。2) 提出了基于共识的延迟机制,通过过滤低置信度预测,提高评分准确性。3) 深入分析了LLM评分的鲁棒性,揭示了其对同义词替换的敏感性。
关键设计:论文的关键设计包括:1) 使用Qwen 2.5-72B作为基础LLM,该模型具有较强的语言理解和生成能力。2) 设计了“信任曲线”分析方法,用于评估不确定性与准确性之间的权衡。3) 采用了随机输入扰动和对抗攻击等多种鲁棒性测试方法。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Qwen 2.5-72B在二元评分任务中表现出较强的对齐性,但随着评分细则粒度的增加,对齐性下降。通过“信任曲线”分析,发现过滤低置信度预测可以显著提高剩余子集的准确性。鲁棒性测试表明,模型对提示注入具有弹性,但对同义词替换敏感。
🎯 应用场景
该研究成果可应用于在线教育平台、自动阅卷系统等领域,减轻教师的阅卷负担,提高评分效率和一致性。通过对LLM评分的鲁棒性分析,可以指导LLM评分系统的安全部署,避免恶意攻击和误判。未来,该技术可扩展到其他需要细则评估的场景,如代码评审、论文评审等。
📄 摘要(原文)
Automated short-answer grading (ASAG) remains a challenging task due to the linguistic variability of student responses and the need for nuanced, rubric-aligned partial credit. While Large Language Models (LLMs) offer a promising solution, their reliability as automated judges in rubric-based settings requires rigorous assessment. In this paper, we systematically evaluate the performance of LLM-judges for rubric-based short-answer grading. We investigate three key aspects: the alignment of LLM grading with expert judgment across varying rubric complexities, the trade-off between uncertainty and accuracy facilitated by a consensus-based deferral mechanism, and the model's robustness under random input perturbations and adversarial attacks. Using the SciEntsBank benchmark and Qwen 2.5-72B, we find that alignment is strong for binary tasks but degrades with increased rubric granularity. Our "Trust Curve" analysis demonstrates a clear trade-off where filtering low-confidence predictions improves accuracy on the remaining subset. Additionally, robustness experiments reveal that while the model is resilient to prompt injection, it is sensitive to synonym substitutions. Our work provides critical insights into the capabilities and limitations of rubric-conditioned LLM judges, highlighting the importance of uncertainty estimation and robustness testing for reliable deployment.