AraToken: Optimizing Arabic Tokenization with Normalization Pipeline and Language Extension for Qwen3
作者: Mark Kashirskiy, Artiom Lipinski, Ilya Makarov
分类: cs.CL, cs.AI
发布日期: 2025-12-20
备注: 8 pages, 8 figures, 5 tables
💡 一句话要点
AraToken:通过归一化和语言扩展优化Qwen3的阿拉伯语分词
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 阿拉伯语分词 自然语言处理 SentencePiece Qwen3 语言扩展 归一化 大型语言模型
📋 核心要点
- 现有通用分词器在形态丰富的阿拉伯语上表现不佳,导致token序列过长和压缩效率降低。
- AraToken通过归一化流程处理阿拉伯语正字法变体,并使用SentencePiece算法进行优化。
- 语言扩展流程(LEP)将AraToken集成到Qwen3中,显著降低了评估损失,提升了模型性能。
📝 摘要(中文)
本文提出了AraToken,一种针对阿拉伯语优化的分词器,它基于SentencePiece Unigram算法,并结合了全面的归一化流程,以处理阿拉伯语特有的正字法变体,包括Alif变体、变音符号和阿拉伯-印度数字。系统地比较了BPE、WordPiece和SentencePiece算法在多种配置下的性能,结果表明,采用归一化的SentencePiece算法相比于未归一化的基线,可以将fertility降低18%(1.199 vs 1.35 tokens/word)。此外,还引入了语言扩展流程(LEP),该方法通过词汇扩展(使用均值子词初始化)和选择性Transformer层解冻,将优化的分词器集成到Qwen3-0.6B中。实验表明,在100K阿拉伯语样本上,LEP在800个训练步骤内将评估损失从8.28降低到2.43。我们发布了分词器、训练脚本和模型检查点,以促进阿拉伯语NLP研究。
🔬 方法详解
问题定义:现有的大型语言模型(LLMs)的分词器主要针对英语和拉丁语系语言进行训练,在处理形态丰富的阿拉伯语时表现次优。这导致阿拉伯语文本被切分成更多的token,增加了计算成本,降低了模型训练和推理的效率。因此,需要一种专门为阿拉伯语优化的分词器,以提高tokenization的效率和质量。
核心思路:本文的核心思路是通过一个全面的归一化流程来处理阿拉伯语中存在的各种正字法变体,例如Alif的不同形式、变音符号以及阿拉伯-印度数字。通过消除这些变体,可以减少词汇的冗余,从而降低token序列的长度。此外,选择SentencePiece Unigram算法作为分词器的基础,因为它在处理未登录词和生成高质量的子词方面表现出色。
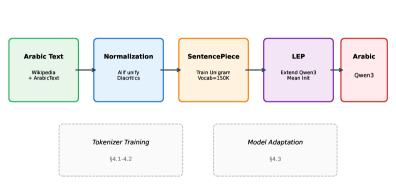
技术框架:AraToken的整体框架包括两个主要部分:一是阿拉伯语文本的归一化流程,二是基于SentencePiece Unigram算法的分词器训练。归一化流程负责将阿拉伯语文本转换为标准化的形式,包括处理Alif变体、移除变音符号以及统一数字表示。然后,使用归一化后的文本训练SentencePiece Unigram分词器,生成一个优化的阿拉伯语词汇表。最后,通过语言扩展流程(LEP)将AraToken集成到Qwen3模型中。
关键创新:该论文的关键创新在于结合了阿拉伯语特定的归一化流程和SentencePiece Unigram算法,从而创建了一个专门为阿拉伯语优化的分词器。此外,提出的语言扩展流程(LEP)提供了一种有效的方法,可以将新的分词器集成到现有的大型语言模型中,而无需从头开始训练整个模型。LEP通过均值子词初始化和选择性Transformer层解冻,实现了快速且高效的模型适应。
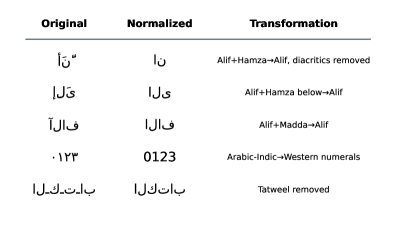
关键设计:归一化流程中,Alif变体的处理包括将所有Alif变体统一为一种标准形式。变音符号的移除旨在减少词汇的冗余,但需要谨慎处理,以避免改变词义。阿拉伯-印度数字被转换为标准阿拉伯数字。在语言扩展流程(LEP)中,新的子词向量通过现有词汇表中相关子词向量的均值进行初始化。选择性Transformer层解冻允许模型在适应新词汇表的同时,保留已有的知识。
🖼️ 关键图片

📊 实验亮点
实验结果表明,AraToken相比于未归一化的基线,可以将fertility降低18%(1.199 vs 1.35 tokens/word)。通过语言扩展流程(LEP)将AraToken集成到Qwen3-0.6B中,在100K阿拉伯语样本上,仅需800个训练步骤即可将评估损失从8.28显著降低到2.43。这些结果表明AraToken在提高阿拉伯语分词效率和模型性能方面具有显著优势。
🎯 应用场景
AraToken的应用场景广泛,包括但不限于:阿拉伯语机器翻译、阿拉伯语文本摘要、阿拉伯语情感分析、阿拉伯语信息检索等。通过提高阿拉伯语文本处理的效率和准确性,AraToken可以显著提升这些应用的性能。此外,该研究可以促进阿拉伯语NLP领域的发展,并为其他形态丰富的语言的分词器优化提供借鉴。
📄 摘要(原文)
Tokenization is a critical preprocessing step for large language models (LLMs), directly impacting training efficiency and downstream performance. General-purpose tokenizers trained predominantly on English and Latin-script languages exhibit suboptimal performance on morphologically rich languages such as Arabic, resulting in inflated token sequences and reduced compression efficiency. In this work, we present AraToken, an Arabic-optimized tokenizer built on SentencePiece Unigram algorithm with a comprehensive normalization pipeline addressing Arabic-specific orthographic variations including Alif variants, diacritics, and Arabic-Indic numerals. We systematically compare BPE, WordPiece, and SentencePiece algorithms across multiple configurations, demonstrating that SentencePiece with normalization achieves 18% lower fertility (1.199 vs 1.35 tokens/word) compared to unnormalized baselines. Furthermore, we introduce the Language Extension Pipeline (LEP), a method for integrating the optimized tokenizer into Qwen3-0.6B through vocabulary extension with mean subtoken initialization and selective transformer layer unfreezing. Our experiments show that LEP reduces evaluation loss from 8.28 to 2.43 within 800 training steps on 100K Arabic samples. We release our tokenizer, training scripts, and model checkpoints to facilitate Arabic NLP research.