DACE For Railway Acronym Disambiguation
作者: El Mokhtar Hribach, Oussama Mechhour, Mohammed Elmonstaser, Yassine El Boudouri, Othmane Kabal
分类: cs.CL
发布日期: 2025-12-20
💡 一句话要点
DACE框架通过动态提示和知识注入解决铁路领域缩略语歧义问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 缩略语歧义消解 大型语言模型 动态提示 检索增强生成 领域知识注入 低资源场景 铁路文档
📋 核心要点
- 现有缩略语歧义消解方法在专业领域,尤其是在低资源场景下,面临高歧义性和数据稀缺的挑战。
- DACE框架的核心思想是利用动态提示和外部知识注入,增强大型语言模型在特定领域的缩略语理解能力。
- DACE框架在TextMine'26竞赛中取得了显著成果,F1值达到0.9069,验证了其有效性。
📝 摘要(中文)
本文针对技术文本处理中缩略语歧义消解这一难题,特别是在专业领域中歧义性高导致自动分析复杂化的问题,提出了DACE框架。该框架应用于TextMine'26法语铁路文档竞赛,通过动态提示、检索增强生成、上下文选择和集成聚合,增强大型语言模型的能力,实现自适应的上下文学习和外部领域知识注入。DACE通过动态调整提示以适应缩略语歧义,并聚合集成预测结果,从而减轻幻觉问题,有效处理低资源场景。该方法在比赛中获得第一名,F1得分为0.9069。
🔬 方法详解
问题定义:论文旨在解决铁路领域法语文档中缩略语歧义消解问题。现有方法在处理专业性强、数据量小的场景时,容易出现幻觉问题,且难以有效利用领域知识。
核心思路:DACE框架的核心思路是通过动态提示(Dynamic Prompting)和检索增强生成(Retrieval Augmented Generation)来增强大型语言模型(LLM)的性能。动态提示根据缩略语的歧义程度自适应地调整提示信息,而检索增强生成则从外部知识库中检索相关信息,注入到LLM中,从而提高其准确性和可靠性。
技术框架:DACE框架包含四个主要模块:1) 动态提示模块:根据缩略语的上下文和歧义程度,生成不同的提示信息。2) 检索增强生成模块:从外部知识库中检索与缩略语相关的知识,并将其融入到LLM的输入中。3) 上下文选择模块:选择最相关的上下文信息,以减少噪声和提高准确性。4) 集成聚合模块:将多个LLM的预测结果进行集成,以提高鲁棒性和准确性。
关键创新:DACE框架的关键创新在于其动态提示和检索增强生成的结合。传统的缩略语歧义消解方法通常依赖于固定的提示或规则,而DACE框架可以根据不同的情况自适应地调整提示信息,从而更好地利用LLM的能力。此外,DACE框架还通过检索增强生成,将外部知识注入到LLM中,从而提高其在低资源场景下的性能。
关键设计:动态提示模块的设计包括歧义度量方法和提示模板选择策略。检索增强生成模块的关键在于知识库的构建和检索算法的选择。上下文选择模块使用基于相似度的排序算法。集成聚合模块采用加权平均或投票等方法。
🖼️ 关键图片
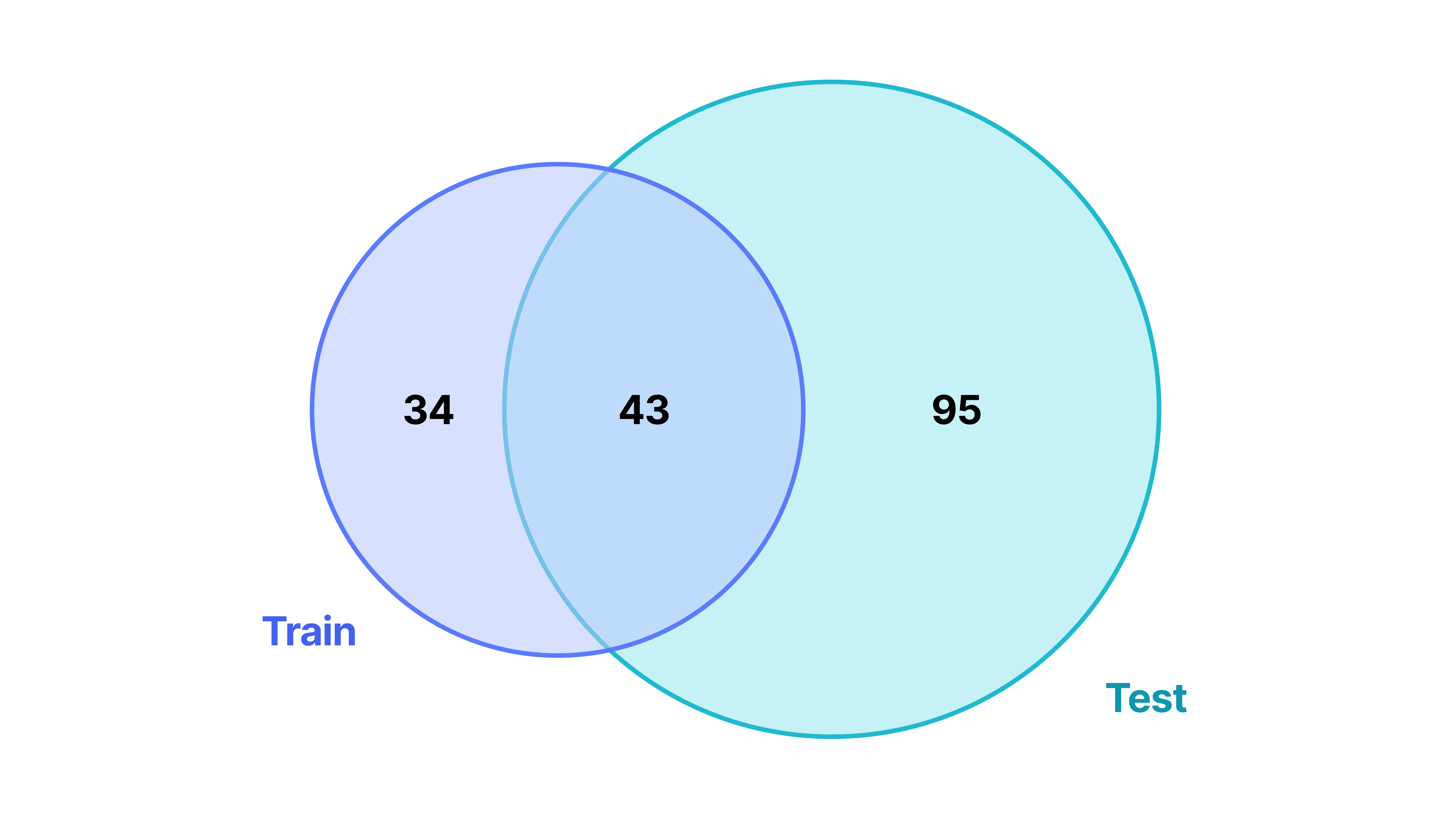
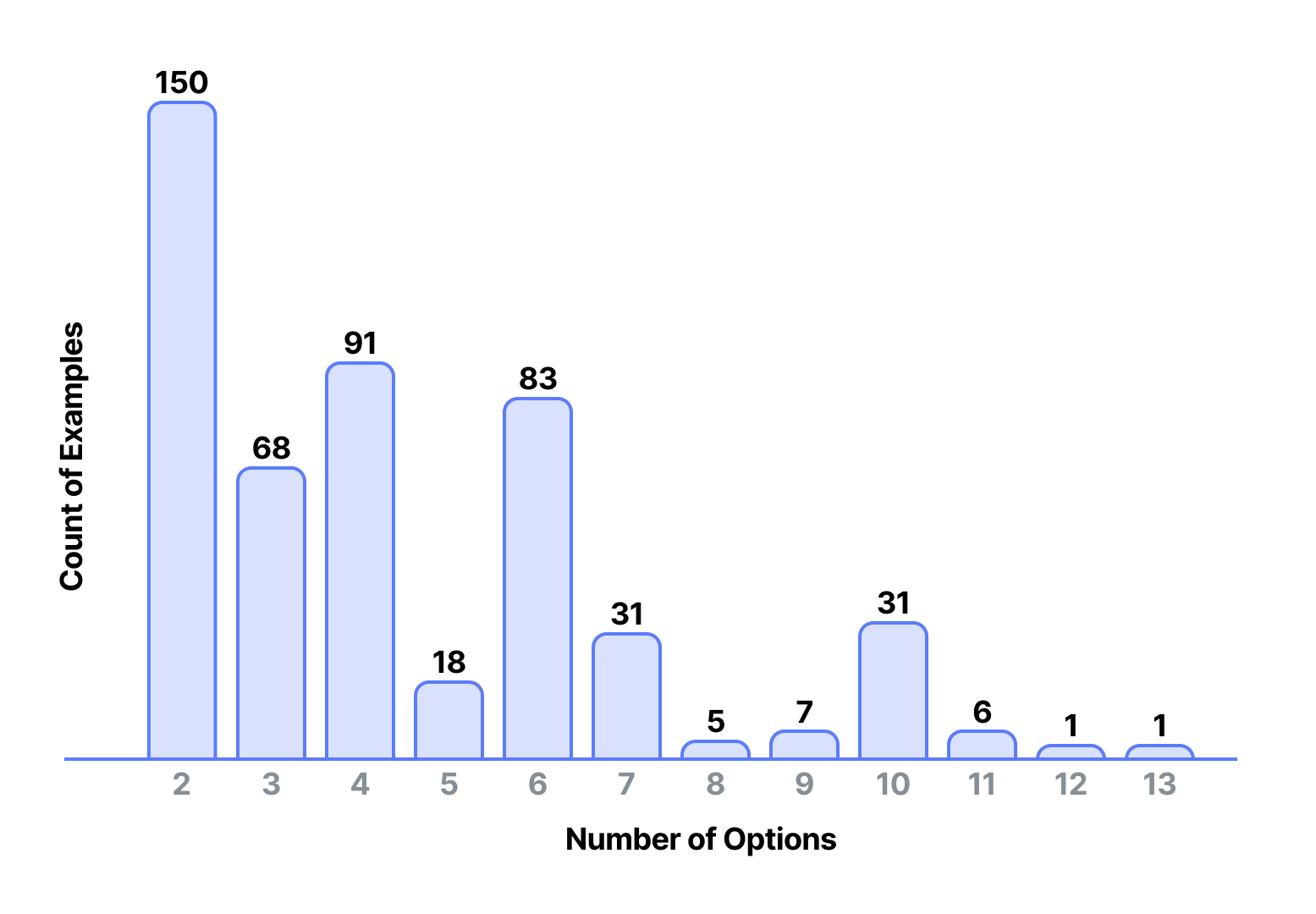
📊 实验亮点
DACE框架在TextMine'26法语铁路文档竞赛中取得了第一名的成绩,F1得分为0.9069。该结果表明,DACE框架能够有效地解决铁路领域的缩略语歧义问题,并在低资源场景下表现出色。相较于其他参赛方案,DACE框架在准确性和鲁棒性方面均有显著提升。
🎯 应用场景
DACE框架可应用于各种专业领域的文本处理,例如医学、法律和金融等。通过解决缩略语歧义问题,可以提高信息检索、文本摘要和机器翻译等任务的准确性和效率。该研究有助于构建更智能、更可靠的自然语言处理系统,促进知识的传播和利用。
📄 摘要(原文)
Acronym Disambiguation (AD) is a fundamental challenge in technical text processing, particularly in specialized sectors where high ambiguity complicates automated analysis. This paper addresses AD within the context of the TextMine'26 competition on French railway documentation. We present DACE (Dynamic Prompting, Retrieval Augmented Generation, Contextual Selection, and Ensemble Aggregation), a framework that enhances Large Language Models through adaptive in-context learning and external domain knowledge injection. By dynamically tailoring prompts to acronym ambiguity and aggregating ensemble predictions, DACE mitigates hallucination and effectively handles low-resource scenarios. Our approach secured the top rank in the competition with an F1 score of 0.9069.