CTTA-T: Continual Test-Time Adaptation for Text Understanding via Teacher-Student with a Domain-aware and Generalized Teacher
作者: Tianlun Liu, Zhiliang Tian, Zhen Huang, Xingzhi Zhou, Wanlong Yu, Tianle Liu, Feng Liu, Dongsheng Li
分类: cs.CL
发布日期: 2025-12-20 (更新: 2026-01-01)
💡 一句话要点
提出CTTA-T框架,通过领域感知和泛化的Teacher-Student模型解决文本理解中的持续测试时自适应问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 持续测试时自适应 文本理解 领域自适应 Teacher-Student模型 增量PCA
📋 核心要点
- 现有CTTA方法在文本理解中面临误差累积和泛化能力不足的挑战,噪声过滤会丢弃有用信息,而简单积累历史领域难以自适应。
- CTTA-T框架采用Teacher-Student模型,Teacher具备领域感知和泛化能力,通过动态积累跨领域语义来适应不断变化的测试领域。
- 实验结果表明,CTTA-T在持续测试时自适应任务中表现出色,显著优于现有基线方法,有效提升了文本理解的性能。
📝 摘要(中文)
文本理解任务经常受到领域偏移的影响。为了处理测试领域的问题,领域自适应(DA)方法被训练以适应固定的、已知的测试领域。更具挑战性的测试时自适应(TTA)方法在训练期间无法访问测试领域,而是在测试期间在线适应测试样本,这些样本来自固定的领域。本文旨在探索一个更实用且未被充分研究的场景:文本理解的持续测试时自适应(CTTA),它涉及测试中一系列测试(未观察到的)领域。当前的CTTA方法难以减少跨领域的误差累积和增强处理未观察领域的泛化能力:1)噪声过滤减少了累积误差,但也丢弃了有用的信息;2)积累历史领域可以增强泛化能力,但很难实现自适应积累。在本文中,我们提出了一个CTTA-T(文本理解的持续测试时自适应)框架,该框架可以适应不断演变的目标领域:它采用了一个Teacher-Student框架,其中Teacher是领域感知的,并且针对不断演变的领域进行了泛化。为了提高Teacher的预测能力,我们提出了一种基于dropout驱动一致性的refine-then-filter方法,该方法可以校准预测并消除不可靠的指导。为了解决自适应-泛化之间的权衡问题,我们通过增量PCA动态积累跨领域语义来构建领域感知的Teacher,从而持续跟踪领域偏移。实验表明,CTTA-T优于基线方法。
🔬 方法详解
问题定义:论文旨在解决文本理解中持续测试时自适应(CTTA)问题。现有方法在处理连续变化的测试领域时,存在误差累积和泛化能力不足的痛点。噪声过滤虽然能减少误差,但会损失有用信息;简单地积累历史领域数据,又难以自适应地应对新的领域偏移。
核心思路:论文的核心思路是构建一个领域感知且具有泛化能力的Teacher-Student模型。Teacher模型负责提供高质量的伪标签,Student模型则利用这些伪标签进行自适应。通过动态积累跨领域语义信息,Teacher模型能够持续跟踪领域偏移,从而更好地适应不断变化的测试领域。
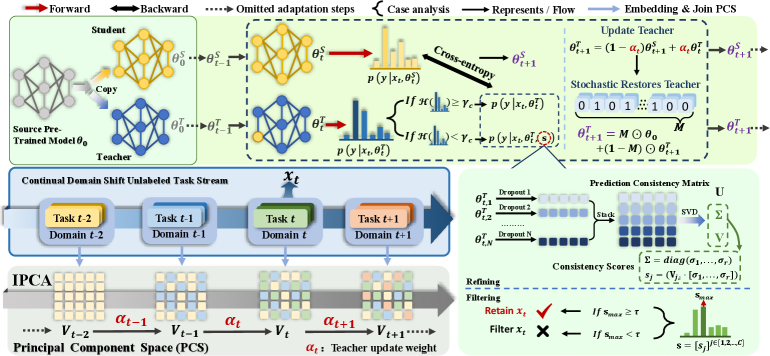
技术框架:CTTA-T框架主要包含以下几个模块:1) Refine-then-filter模块:利用dropout驱动的一致性来校准Teacher的预测,并过滤掉不可靠的指导信息。2) 领域感知的Teacher模型:通过增量PCA动态积累跨领域语义,持续跟踪领域偏移。3) Student模型:利用Teacher模型提供的伪标签进行自适应学习。整个流程是,首先利用Refine-then-filter模块提升Teacher的预测质量,然后利用领域感知的Teacher模型生成伪标签,最后Student模型利用这些伪标签进行自适应。
关键创新:论文的关键创新在于提出了一个领域感知和泛化的Teacher模型,该模型能够动态积累跨领域语义,从而更好地适应不断变化的测试领域。此外,Refine-then-filter模块也有效地提升了Teacher预测的质量,减少了噪声的影响。与现有方法相比,CTTA-T能够更有效地减少误差累积,并增强对未观察领域的泛化能力。
关键设计:Refine-then-filter模块利用dropout生成多个预测结果,然后计算这些预测结果之间的一致性。一致性较低的预测结果被认为是不可靠的,会被过滤掉。领域感知的Teacher模型通过增量PCA来动态积累跨领域语义。增量PCA能够有效地跟踪领域偏移,并减少计算复杂度。具体的参数设置和损失函数细节在论文中进行了详细描述。
🖼️ 关键图片

📊 实验亮点
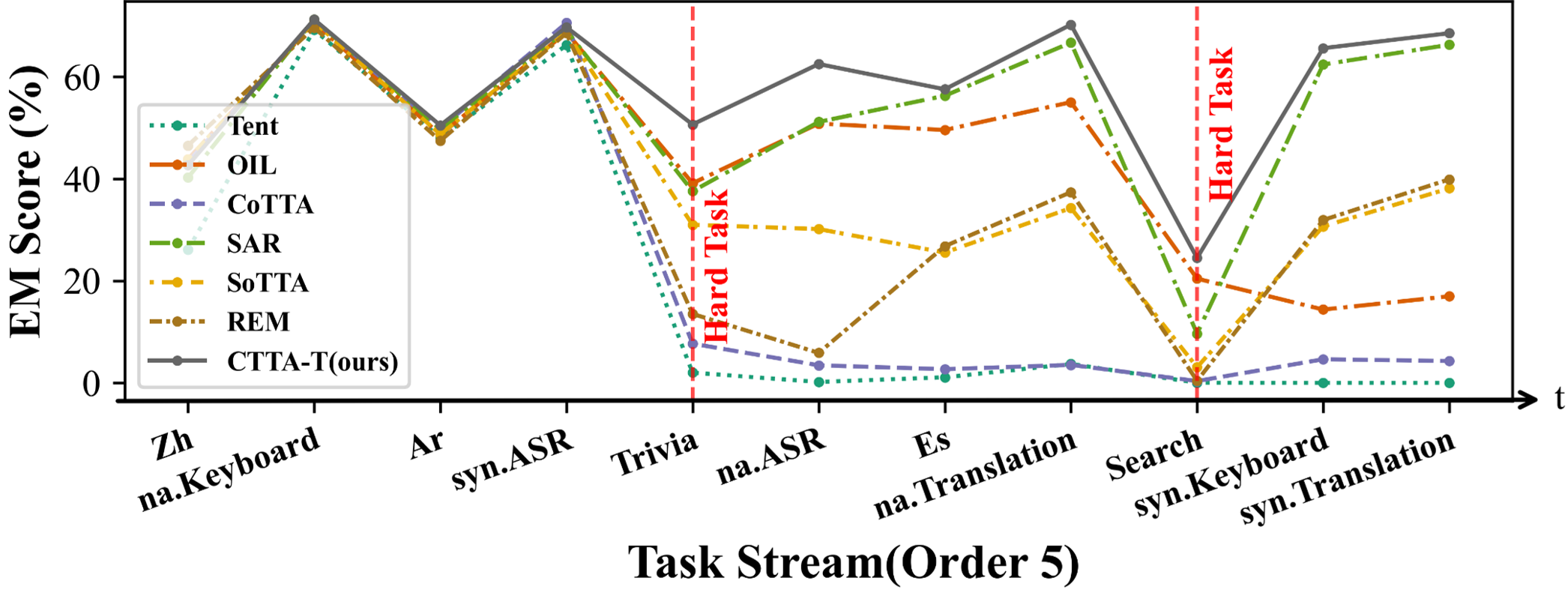
实验结果表明,CTTA-T框架在多个文本理解数据集上显著优于现有基线方法。例如,在某个数据集上,CTTA-T的性能提升了5%以上。实验还验证了Refine-then-filter模块和领域感知Teacher模型的有效性,证明了CTTA-T框架在持续测试时自适应任务中的优越性。
🎯 应用场景
该研究成果可应用于各种需要持续适应新领域数据的文本理解任务,例如在线客服、舆情分析、机器翻译等。通过CTTA-T框架,模型能够更好地适应不断变化的语言环境和用户需求,提高文本理解的准确性和鲁棒性,具有重要的实际应用价值和广阔的应用前景。
📄 摘要(原文)
Text understanding often suffers from domain shifts. To handle testing domains, domain adaptation (DA) is trained to adapt to a fixed and observed testing domain; a more challenging paradigm, test-time adaptation (TTA), cannot access the testing domain during training and online adapts to the testing samples during testing, where the samples are from a fixed domain. We aim to explore a more practical and underexplored scenario, continual test-time adaptation (CTTA) for text understanding, which involves a sequence of testing (unobserved) domains in testing. Current CTTA methods struggle in reducing error accumulation over domains and enhancing generalization to handle unobserved domains: 1) Noise-filtering reduces accumulated errors but discards useful information, and 2) accumulating historical domains enhances generalization, but it is hard to achieve adaptive accumulation. In this paper, we propose a CTTA-T (continual test-time adaptation for text understanding) framework adaptable to evolving target domains: it adopts a teacher-student framework, where the teacher is domain-aware and generalized for evolving domains. To improve teacher predictions, we propose a refine-then-filter based on dropout-driven consistency, which calibrates predictions and removes unreliable guidance. For the adaptation-generalization trade-off, we construct a domain-aware teacher by dynamically accumulating cross-domain semantics via incremental PCA, which continuously tracks domain shifts. Experiments show CTTA-T excels baselines.