Consistency-Aware Editing for Entity-level Unlearning in Language Models
作者: Xiaoqi Han, Víctor Gutiérrez-Basulto, Ru Li, Xiaoli Li, Jiye Liang, Jeff Z. Pan
分类: cs.CL, cs.AI
发布日期: 2025-12-19
💡 一句话要点
提出一致性感知编辑框架CAE,用于语言模型中实体级别知识的有效擦除。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识擦除 语言模型编辑 一致性学习 低秩更新 实体级别知识 模型安全 鲁棒性 提示工程
📋 核心要点
- 现有实体级别知识擦除方法(如微调和提示工程)计算成本高或对释义敏感,难以高效且鲁棒地移除LLM中的特定实体知识。
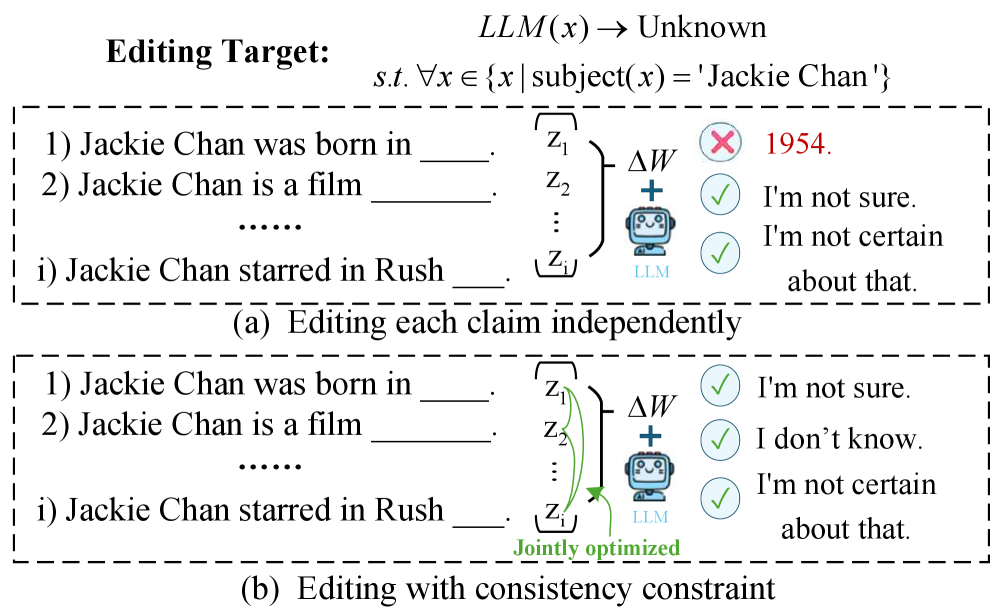
- 论文提出一致性感知编辑(CAE)框架,通过聚合多样化提示并施加一致性正则化,引导模型学习低秩更新,实现对目标实体知识的全面擦除。
- 实验表明,CAE在RWKU和ToFU基准上显著提升了遗忘准确性和鲁棒性,且仅需少量提示即可实现可扩展的实体移除。
📝 摘要(中文)
大型语言模型(LLMs)存在保留训练数据中敏感、受版权保护或有害信息的风险。实体级别知识擦除旨在解决此问题,即移除关于特定实体的所有知识,同时保留模型整体能力。现有方法通常依赖于全模型微调或基于提示的干预,这在处理释义查询时计算成本高昂或脆弱。最近,模型编辑作为一种高效的LLM知识更新替代方案出现,为知识擦除提供了一个有希望的方向。然而,现有的编辑技术通常是为实例级别的更新而设计的,修改对实体特定属性的响应,而不是消除与该实体相关的所有知识。本文研究了如何调整编辑技术,以实现有效和高效的实体级别知识擦除。为此,我们引入了一种新颖的一致性感知编辑(CAE)框架。CAE聚合与目标实体相关的各种提示,包括其属性、关系和对抗性释义。然后,它在一致性正则化的指导下,联合学习一个低秩更新,该正则化器对齐跨提示的编辑方向。这促进了鲁棒和全面的遗忘,同时最大限度地减少了对不相关知识的干扰。我们进一步研究了不同的实体存储在模型中的位置,以及成功擦除所需的各种提示的数量。我们在两个具有挑战性的基准RWKU和ToFU上评估CAE,并证明它(i)提供了关于实体级别知识如何在LLM内部表示和删除的见解,(ii)显著提高了遗忘的准确性和鲁棒性,优于传统的知识擦除和编辑基线,以及(iii)仅使用数十个精心选择的提示即可实现可扩展的实体移除。
🔬 方法详解
问题定义:论文旨在解决大型语言模型中实体级别知识擦除的问题。现有方法,如全模型微调和基于提示的干预,存在计算成本高昂、对释义敏感等问题,难以高效且鲁棒地移除模型中关于特定实体的所有知识。这些方法通常针对实例级别的更新,而非实体级别的彻底遗忘。
核心思路:论文的核心思路是利用模型编辑技术,并引入一致性感知机制,以实现高效且鲁棒的实体级别知识擦除。通过聚合与目标实体相关的多样化提示,并施加一致性正则化,引导模型学习一个低秩更新,从而在多个角度和表达方式上消除对该实体的知识。
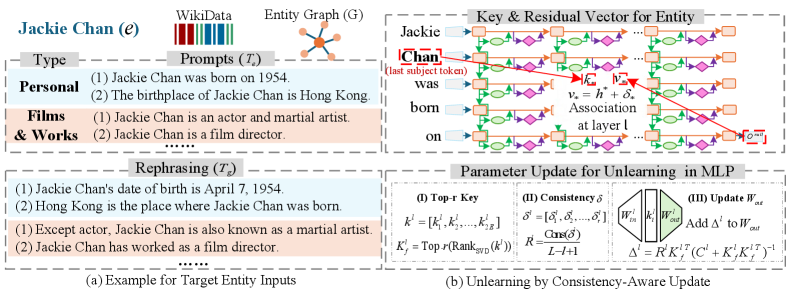
技术框架:CAE框架主要包含以下几个步骤:1) 提示聚合:收集与目标实体相关的多样化提示,包括属性、关系和对抗性释义。2) 编辑方向学习:利用收集到的提示,学习一个低秩更新,该更新旨在修改模型参数,以消除对目标实体的知识。3) 一致性正则化:引入一致性正则化项,以确保在不同提示下,编辑方向保持一致,从而提高擦除的鲁棒性。4) 模型更新:将学习到的低秩更新应用到模型参数中,完成实体级别知识的擦除。
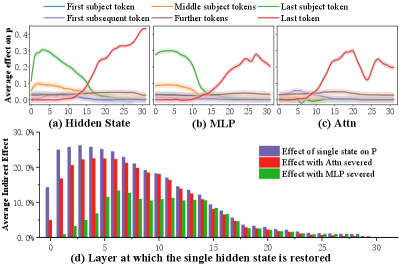
关键创新:论文的关键创新在于提出了一致性感知编辑(CAE)框架,该框架通过聚合多样化提示和施加一致性正则化,实现了对实体级别知识的全面且鲁棒的擦除。与现有方法相比,CAE能够更有效地处理释义查询,并减少对不相关知识的干扰。此外,论文还探讨了实体知识在模型中的存储方式,以及成功擦除所需的提示数量。
关键设计:CAE的关键设计包括:1) 低秩更新:使用低秩更新来限制模型参数的修改范围,从而减少对不相关知识的干扰。2) 一致性正则化:通过最小化不同提示下编辑方向的差异,来提高擦除的鲁棒性。具体而言,可以使用余弦相似度等指标来衡量编辑方向的一致性。3) 提示选择策略:论文可能探讨了如何选择最具代表性和信息量的提示,以提高擦除的效率。
🖼️ 关键图片
📊 实验亮点
实验结果表明,CAE在RWKU和ToFU基准上显著优于传统的知识擦除和编辑基线。具体而言,CAE在遗忘准确性和鲁棒性方面均取得了显著提升,并且仅需数十个精心选择的提示即可实现可扩展的实体移除。这些结果验证了CAE框架的有效性和高效性。
🎯 应用场景
该研究成果可应用于保护大型语言模型中的敏感信息、版权信息和有害信息,例如在模型发布前移除个人隐私数据或不当内容。此外,该技术还可用于模型定制,根据用户需求移除特定领域的知识,从而提高模型在特定任务上的性能。未来,该技术有望应用于更广泛的知识管理和模型安全领域。
📄 摘要(原文)
Large language models (LLMs) risk retaining sensitive, copyrighted, or harmful information from their training data. Entity-level unlearning addresses this issue by removing all knowledge of a specific entity while preserving the model's overall capabilities. Existing approaches typically rely on full-model fine-tuning or prompt-based interventions, which can be computationally expensive or brittle when handling paraphrased queries. Recently, model editing has emerged as an efficient alternative for updating knowledge in LLMs, offering a promising direction for unlearning. However, existing editing techniques are typically designed for instance-level updates, modifying responses to specific attributes of an entity rather than eliminating all knowledge associated with the entity. In this paper, we investigate how editing techniques can be adapted for effective and efficient entity-level unlearning. To this end, we introduce a novel consistency-aware editing (CAE) framework. CAE aggregates a diverse set of prompts related to a target entity, including its attributes, relations, and adversarial paraphrases. It then jointly learns a low-rank update guided by a consistency regularizer that aligns the editing directions across prompts. This promotes robust and comprehensive forgetting while minimizing interference with unrelated knowledge. We further examine where different entities are stored within the model and how many diverse prompts are needed for successful unlearning. We evaluate CAE on two challenging benchmarks, RWKU and ToFU, and demonstrate that it (i) provides insights into how entity-level knowledge is internally represented and deleted in LLMs, (ii) significantly improves forgetting accuracy and robustness over traditional unlearning and editing baselines, and (iii) enables scalable entity removal using only tens of carefully selected prompts.