Reinforcement Learning for Chain of Thought Compression with One-Domain-to-All Generalization
作者: Hanyu Li, Jiangshan Duo, Bofei Gao, Hailin Zhang, Sujian Li, Xiaotie Deng, Liang Zhao
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-12-19 (更新: 2026-01-21)
💡 一句话要点
提出基于强化学习的思维链压缩方法,实现跨领域泛化和效率提升。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 思维链推理 强化学习 模型压缩 跨领域泛化 语言模型 智能代理
📋 核心要点
- 现有思维链推理方法存在过度思考问题,导致成本增加但收益不稳定。
- 提出基于强化学习的思维链压缩,根据模型掌握程度动态调整推理长度。
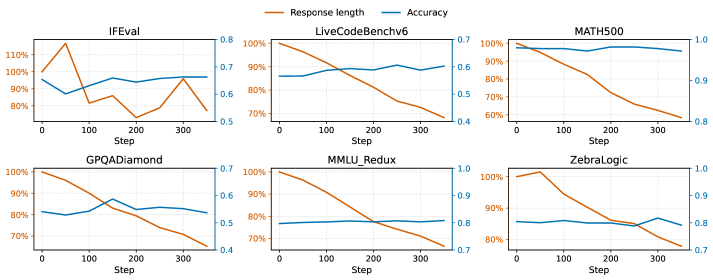
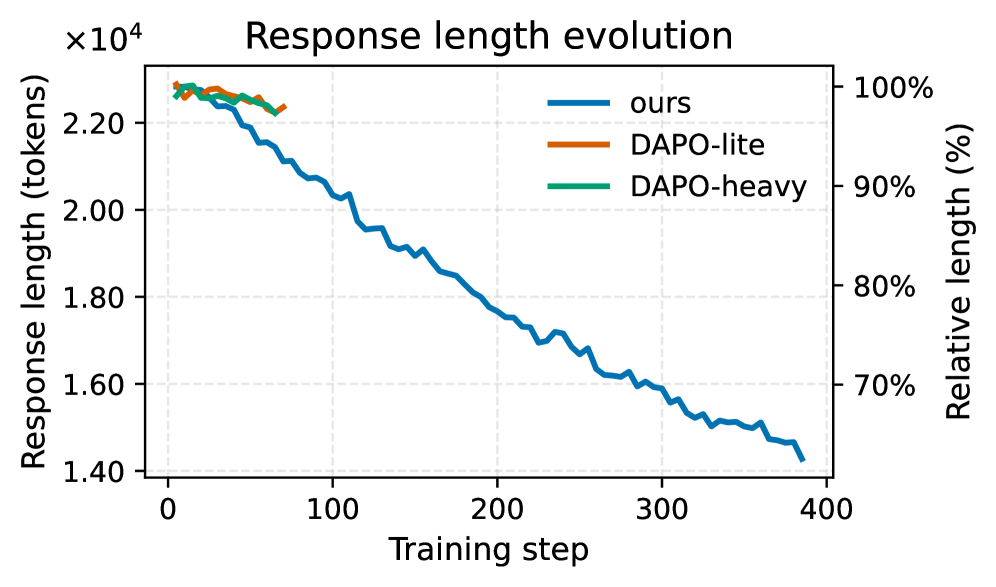
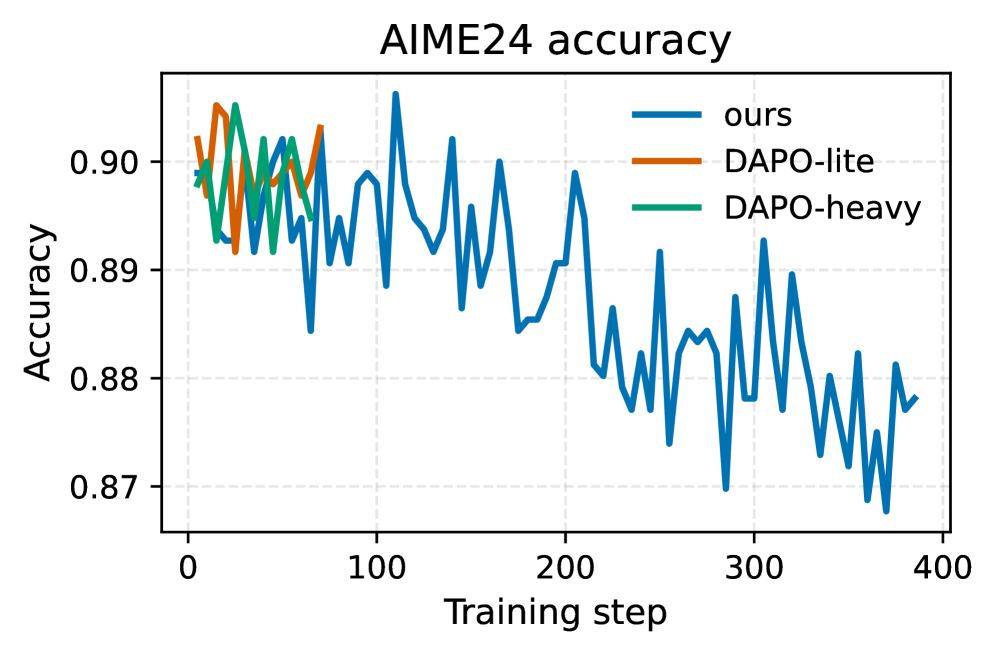
- 实验表明,该方法能有效缩短推理链,提升效率,并具备跨领域泛化能力。
📝 摘要(中文)
大型语言模型中的思维链推理可能导致“过度思考陷阱”:更长的推理过程增加了成本和延迟,但通常无法获得可靠的准确性提升。现有方法使用全局、静态的控制,这可能会抑制必要的推理。我们提出了一种基于掌握程度门控的、样本级别的、软强化学习压缩方法,该方法仅在模型已经解决问题并产生了较短的推理过程时,才会惩罚较长的推理过程。在多个基准测试中,该方法在保持或提高准确性的同时,将响应长度缩短了20-40%,并且可以跨领域泛化:在数学领域训练的模型可以自发地缩短未见过的任务(代码、指令遵循、通用知识问答),而不会损害准确性。我们进一步展示了非代理CoT和工具使用代理之间的双向迁移:非代理训练将SWE-Bench Verified的回合数减少了13%,而压缩一个思考代理将SWE轨迹减少了67%的token和52%的回合数,并将非代理输出缩短了高达44%。因此,压缩不仅仅是表面上的简洁,而是一种固有的计算策略——保留什么,以及忘记什么。
🔬 方法详解
问题定义:论文旨在解决大型语言模型中思维链(Chain-of-Thought, CoT)推理的“过度思考陷阱”问题。现有方法采用全局静态控制,无法根据具体问题和模型状态灵活调整推理长度,导致不必要的计算开销和延迟,同时可能抑制模型进行有效推理。
核心思路:论文的核心思路是利用强化学习,训练一个能够根据模型对问题的掌握程度动态压缩思维链的策略。当模型已经能够通过较短的推理链解决问题时,就惩罚更长的推理链,鼓励模型学习更高效的推理路径。这种基于样本级别的软压缩,允许模型在需要时进行更深入的思考,避免一刀切的全局控制。
技术框架:整体框架包含一个大型语言模型作为推理器,以及一个强化学习智能体作为压缩器。推理器负责生成思维链,压缩器根据推理器的输出和问题难度,决定是否需要继续推理。具体流程如下:1. 给定问题,推理器生成初始思维链;2. 压缩器评估当前思维链的质量(例如,是否已经解决问题);3. 如果压缩器认为可以停止推理,则输出结果;否则,推理器继续生成思维链;4. 使用强化学习算法(例如,策略梯度)训练压缩器,目标是最小化推理成本(例如,推理步数),同时最大化准确率。
关键创新:最重要的技术创新点在于“掌握程度门控”的强化学习压缩策略。该策略不是简单地限制推理长度,而是根据模型对问题的掌握程度动态调整。只有当模型已经能够解决问题时,才会惩罚更长的推理链。这种方法能够更好地平衡推理成本和准确率,避免抑制必要的推理。此外,该方法还展现出良好的跨领域泛化能力,无需针对特定领域进行训练。
关键设计:关键设计包括:1. 奖励函数的设计,需要平衡推理成本和准确率。论文采用了一种软奖励函数,根据模型输出的置信度和推理长度进行加权;2. 强化学习算法的选择,论文采用了策略梯度算法,能够直接优化推理策略;3. 模型架构的设计,压缩器可以是一个小型神经网络,输入是推理器的输出和问题表示,输出是停止推理的概率。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在多个基准测试中,能够在保持或提高准确性的同时,将响应长度缩短20-40%。更重要的是,该方法展现出良好的跨领域泛化能力,在数学领域训练的模型可以自发地缩短未见过的任务(代码、指令遵循、通用知识问答),而不会损害准确性。此外,该方法还实现了非代理CoT和工具使用代理之间的双向迁移,进一步验证了其有效性和通用性。
🎯 应用场景
该研究成果可应用于各种需要高效推理的场景,例如智能客服、自动问答系统、代码生成等。通过压缩思维链,可以显著降低计算成本和延迟,提高系统的响应速度和用户体验。此外,该方法还具有跨领域泛化能力,可以应用于不同的任务和领域,具有广泛的应用前景。
📄 摘要(原文)
Chain-of-thought reasoning in large language models can trigger an "overthinking trap": longer rollouts raise cost and latency yet often yield unreliable accuracy gains. Existing methods use global, static controls that may suppress needed reasoning. We propose mastery-gated, sample-level, soft reinforcement learning compression that penalizes long rollouts only when the model already solves the problem and has produced a shorter rollout. Across benchmarks, it cuts response length by 20-40% with comparable or higher accuracy and generalizes across domains: a model trained on math spontaneously shortens unseen tasks (code, instruction following, general-knowledge QA) without hurting accuracy. We further show two-way transfer between non-agent CoT and tool-use agents: non-agent training reduces SWE-Bench Verified rounds by 13%, while compressing a thinking agent cuts SWE trajectories by 67% tokens and 52% rounds and shortens non-agent outputs by up to 44%. Compression is thus not cosmetic brevity, but an inherent computation policy -- what to keep, and what to forget.