The Instruction Gap: LLMs get lost in Following Instruction
作者: Vishesh Tripathi, Uday Allu, Biddwan Ahmed
分类: cs.CL, cs.AI
发布日期: 2025-12-19
💡 一句话要点
揭示大语言模型指令遵循差距,评估企业级RAG场景性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 指令遵循 检索增强生成 RAG 企业应用
📋 核心要点
- 现有大语言模型在通用任务上表现出色,但在企业级应用中,精确遵循自定义指令的能力不足,存在“指令差距”。
- 该研究系统评估了13个主流LLM在真实RAG场景下的指令依从性、响应准确性和性能,旨在发现并量化这一差距。
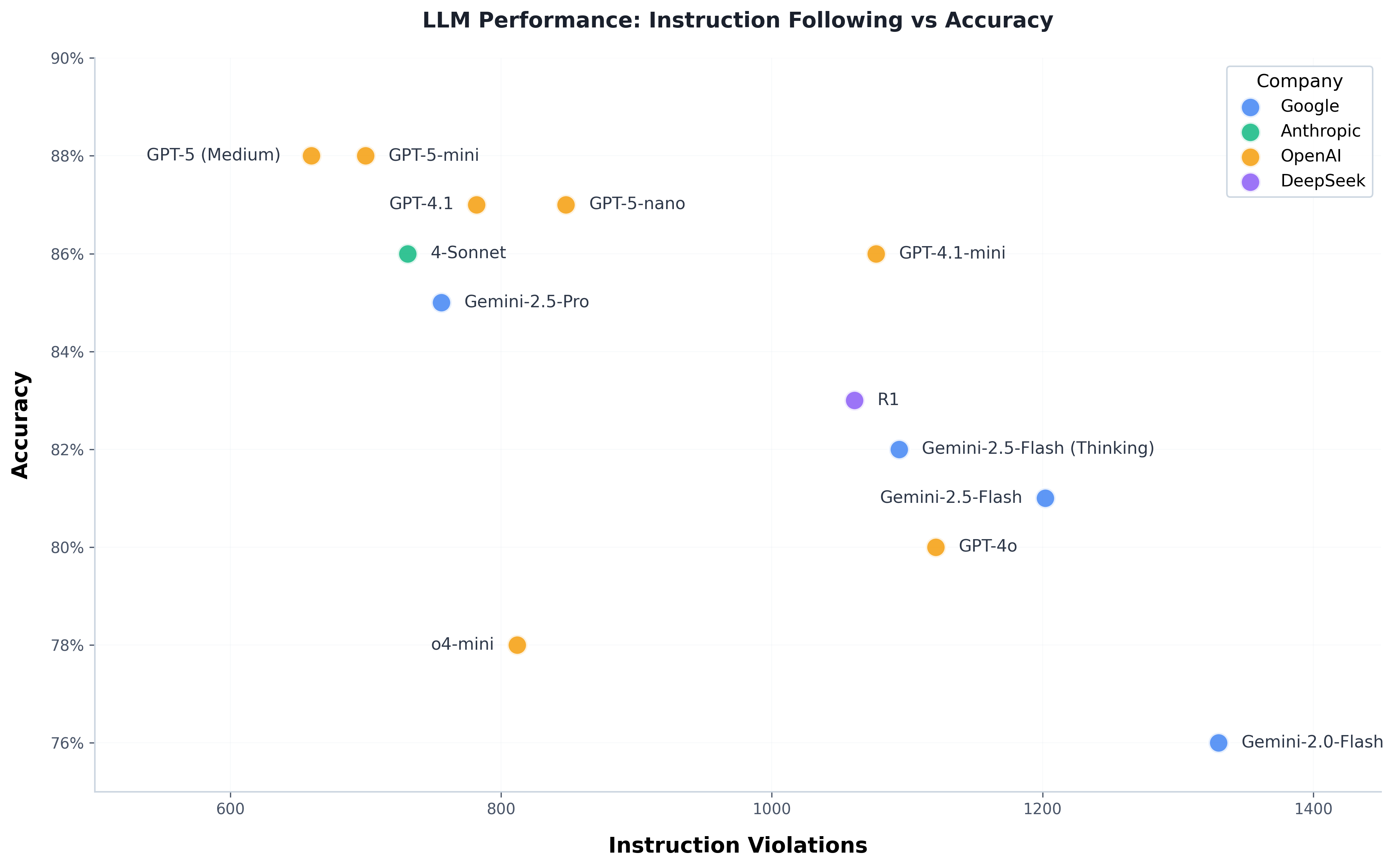
- 实验结果表明,不同模型在指令遵循方面存在显著差异,Claude-Sonnet-4和GPT-5表现最佳,为企业应用选型提供参考。
📝 摘要(中文)
大型语言模型(LLM)在自然语言理解和生成方面表现出卓越的能力,但它们在企业环境中的部署揭示了一个关键的局限性:对自定义指令的不一致遵循。本研究对13个领先的LLM在真实RAG(检索增强生成)场景中的指令依从性、响应准确性和性能指标进行了全面评估。通过使用样本和企业级评估协议进行系统测试,我们证明了不同模型之间的指令遵循差异很大,其中Claude-Sonnet-4和GPT-5取得了最好的结果。我们的发现揭示了“指令差距”——一个根本性的挑战,即模型擅长通用任务,但在企业部署所需的精确指令遵循方面表现不佳。这项工作为部署LLM驱动解决方案的组织提供了实践见解,并为主要模型系列的指令遵循能力建立了基准。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在企业级RAG(检索增强生成)场景中,无法精确遵循自定义指令的问题。现有方法虽然在通用任务上表现良好,但在需要高度定制化和精确指令遵循的实际应用中,存在显著的性能瓶颈,导致“指令差距”。
核心思路:论文的核心思路是通过系统性的评估和基准测试,量化不同LLM在指令遵循方面的能力差异,从而帮助企业选择最适合其特定需求的模型。通过构建包含多种指令类型和复杂度的测试用例,深入分析模型在不同场景下的表现。
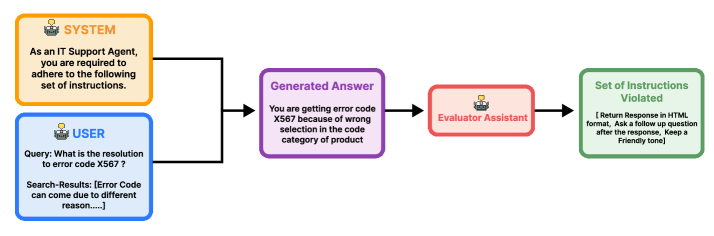
技术框架:论文采用的评估框架主要包括以下几个阶段:1) 构建包含多种指令类型和复杂度的测试数据集;2) 选择13个主流LLM进行测试,包括GPT系列、Claude系列等;3) 使用企业级评估协议,对模型的指令依从性、响应准确性和性能指标进行量化评估;4) 分析评估结果,揭示不同模型之间的“指令差距”,并给出实际部署建议。
关键创新:论文的关键创新在于:1) 首次系统性地提出了并量化了LLM在企业级RAG场景中的“指令差距”;2) 构建了包含多种指令类型和复杂度的测试数据集,更贴近实际应用场景;3) 采用了企业级评估协议,更全面地评估了模型的性能。
关键设计:论文在测试数据集的设计上,考虑了指令的类型(如生成、翻译、总结等)、指令的复杂度(如多步指令、条件指令等)以及指令与检索内容的相关性。在评估指标的选择上,除了传统的准确率、召回率等指标外,还引入了专门用于评估指令依从性的指标,例如指令覆盖率、指令执行准确率等。
🖼️ 关键图片
📊 实验亮点
实验结果表明,不同LLM在指令遵循方面存在显著差异,Claude-Sonnet-4和GPT-5在所有测试指标上均表现最佳,显著优于其他模型。例如,在复杂指令的执行准确率方面,Claude-Sonnet-4比表现最差的模型高出30%。该研究为企业选择合适的LLM提供了重要的参考依据。
🎯 应用场景
该研究成果可应用于企业级知识库问答系统、智能客服、自动化报告生成等领域。通过选择指令遵循能力更强的LLM,可以显著提高系统的准确性和可靠性,降低人工干预成本。未来,该研究可以扩展到更多领域,例如医疗诊断、金融分析等,为各行业提供更智能化的解决方案。
📄 摘要(原文)
Large Language Models (LLMs) have shown remarkable capabilities in natural language understanding and generation, yet their deployment in enterprise environments reveals a critical limitation: inconsistent adherence to custom instructions. This study presents a comprehensive evaluation of 13 leading LLMs across instruction compliance, response accuracy, and performance metrics in realworld RAG (Retrieval-Augmented Generation) scenarios. Through systematic testing with samples and enterprise-grade evaluation protocols, we demonstrate that instruction following varies dramatically across models, with Claude-Sonnet-4 and GPT-5 achieving the highest results. Our findings reveal the "instruction gap" - a fundamental challenge where models excel at general tasks but struggle with precise instruction adherence required for enterprise deployment. This work provides practical insights for organizations deploying LLM-powered solutions and establishes benchmarks for instruction-following capabilities across major model families.