WRAVAL -- WRiting Assist eVALuation
作者: Gabriel Benedict, Matthew Butler, Naved Merchant, Eetu Salama-Laine
分类: cs.CL, cs.LG
发布日期: 2025-12-19
🔗 代码/项目: GITHUB
💡 一句话要点
WRAVAL:针对小型语言模型写作辅助能力的评估框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 小型语言模型 写作辅助 评估框架 提示调优 大型语言模型 边缘计算 私有计算 数据生成
📋 核心要点
- 现有LLM评估侧重推理任务,忽略了SLM在语气修改等工业应用中的潜力。
- WRAVAL框架通过数据生成、提示调优和LLM评估,针对性评估SLM的写作辅助能力。
- 实验表明,WRAVAL能有效评估SLM在特定任务微调后的性能,适用于边缘计算等场景。
📝 摘要(中文)
大型语言模型(LLM)的出现已将语言模型评估转向推理和问题解决任务,以此作为衡量通用智能的标准。小型语言模型(SLM),本文定义为参数量小于100亿的模型,在这些指标上的得分通常比LLM低3-4倍。然而,我们证明这些评估未能捕捉到SLM在常见工业应用中的有效性,例如语气修改任务(如幽默、严肃、专业)。我们提出了一个评估框架,专门用于突出SLM在非推理任务中的能力,这些任务缺乏预定义的评估数据集。我们的框架结合了数据生成、提示调优和基于LLM的评估等新方法,以展示特定任务微调的潜力。这项工作为从业者提供了有效基准测试SLM和LLM的工具,尤其是在边缘和私有计算场景中。我们的实现可在https://github.com/amazon-science/wraval获得。
🔬 方法详解
问题定义:论文旨在解决现有语言模型评估体系对小型语言模型(SLM)在特定写作辅助任务(如语气修改)能力评估不足的问题。现有评估方法主要集中在推理和问题解决能力上,忽略了SLM在实际工业应用中的潜力,并且缺乏针对这些特定任务的预定义数据集。
核心思路:论文的核心思路是构建一个专门针对SLM写作辅助能力的评估框架,该框架能够生成适用于特定任务的数据集,并通过提示调优和基于LLM的评估方法,更准确地衡量SLM在这些任务上的表现。通过这种方式,可以更好地了解SLM在实际应用中的优势和局限性。
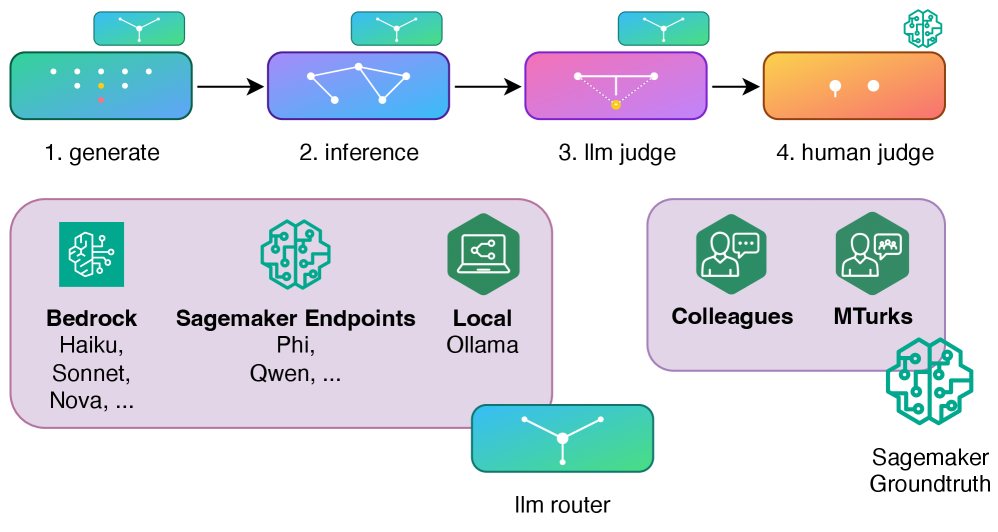
技术框架:WRAVAL框架包含以下主要模块:1) 数据生成:针对特定写作辅助任务(如语气修改)生成训练和评估数据。2) 提示调优:通过优化提示语,提高SLM在特定任务上的性能。3) LLM评估:使用大型语言模型作为评估器,对SLM生成的文本进行评估,判断其是否符合任务要求。整体流程是先生成数据,然后使用这些数据对SLM进行微调和提示调优,最后使用LLM评估器评估SLM的性能。
关键创新:该框架的关键创新在于其针对性地评估SLM在非推理任务中的能力,并结合了数据生成、提示调优和LLM评估等多种技术。与现有评估方法相比,WRAVAL更关注SLM在实际应用中的表现,并提供了一种更全面、更准确的评估方式。
关键设计:在数据生成方面,论文可能采用了某种策略来确保生成的数据具有多样性和代表性。在提示调优方面,可能使用了某种优化算法来搜索最佳提示语。在LLM评估方面,可能使用了某种指标来衡量SLM生成的文本的质量,例如流畅度、相关性和准确性。具体的参数设置、损失函数和网络结构等技术细节在论文中可能有所描述,但摘要中未提及。
🖼️ 关键图片
📊 实验亮点
论文提出了一个新颖的评估框架,能够有效评估SLM在写作辅助任务中的性能。通过结合数据生成、提示调优和LLM评估等技术,WRAVAL能够更准确地衡量SLM在实际应用中的表现。具体的性能数据、对比基线和提升幅度等信息需要在论文中查找,摘要中未提供。
🎯 应用场景
WRAVAL框架可应用于各种需要写作辅助的场景,例如自动生成邮件、撰写社交媒体帖子、修改文档语气等。该研究的实际价值在于帮助开发者更好地选择和优化SLM,以满足特定应用的需求,尤其是在资源受限的边缘计算和私有计算环境中。未来,该框架可以扩展到更多写作辅助任务,并与其他评估方法相结合,形成更全面的语言模型评估体系。
📄 摘要(原文)
The emergence of Large Language Models (LLMs) has shifted language model evaluation toward reasoning and problem-solving tasks as measures of general intelligence. Small Language Models (SLMs) -- defined here as models under 10B parameters -- typically score 3-4 times lower than LLMs on these metrics. However, we demonstrate that these evaluations fail to capture SLMs' effectiveness in common industrial applications, such as tone modification tasks (e.g., funny, serious, professional). We propose an evaluation framework specifically designed to highlight SLMs' capabilities in non-reasoning tasks where predefined evaluation datasets don't exist. Our framework combines novel approaches in data generation, prompt-tuning, and LLM-based evaluation to demonstrate the potential of task-specific finetuning. This work provides practitioners with tools to effectively benchmark both SLMs and LLMs for practical applications, particularly in edge and private computing scenarios. Our implementation is available at: https://github.com/amazon-science/wraval.