Linear Personality Probing and Steering in LLMs: A Big Five Study
作者: Michel Frising, Daniel Balcells
分类: cs.CL
发布日期: 2025-12-19 (更新: 2026-01-15)
备注: 29 pages, 6 figures
💡 一句话要点
利用线性探针和引导实现LLM性格控制:基于五大人格特质的研究
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 性格控制 线性探针 线性引导 五大人格特质 提示工程 模型可解释性
📋 核心要点
- 现有方法在控制LLM性格方面存在不足,后训练成本高昂,提示工程方法脆弱。
- 该论文探索利用与五大人格特质对齐的线性方向,实现对LLM性格的探针和引导。
- 实验表明,线性方向是性格检测的有效探针,但引导能力受上下文影响较大。
📝 摘要(中文)
大型语言模型(LLMs)表现出独特且一致的性格,这极大地影响了信任度和互动性。性格框架是表征和控制LLMs行为的宝贵工具,但目前的方法要么成本高昂(后训练),要么脆弱(提示工程)。通过线性方向进行探针和引导最近成为一种廉价而有效的替代方案。本文研究了与五大人格特质对齐的线性方向是否可用于探针和引导模型行为。使用Llama 3.3 70B,我们生成了406个虚构角色的描述及其五大人格特质得分。然后,我们使用这些描述和Alpaca问卷中的问题来提示模型,从而能够以已知、可量化的方式对沿人格特质变化的隐藏激活进行采样。使用线性回归,我们学习了一组每层激活空间中的方向,并测试了它们在探针和引导模型行为方面的有效性。结果表明,与特质得分对齐的线性方向是性格检测的有效探针,而它们的引导能力在很大程度上取决于上下文,在强制选择任务中产生可靠的效果,但在开放式生成或提示中存在额外上下文时影响有限。
🔬 方法详解
问题定义:目前控制大型语言模型(LLMs)性格的方法存在局限性。后训练方法需要大量的计算资源和时间,成本高昂。提示工程虽然简单,但对提示的微小变化非常敏感,缺乏鲁棒性。因此,需要一种更有效、更可靠的方法来表征和控制LLMs的性格。
核心思路:该论文的核心思路是利用线性探针和引导技术,通过学习与五大人格特质(Big Five personality traits)对齐的线性方向,来探查和控制LLMs的性格。这种方法基于一个假设:LLMs的内部激活空间中存在与特定性格特质相关的方向,通过沿着这些方向进行调整,可以改变模型的行为。
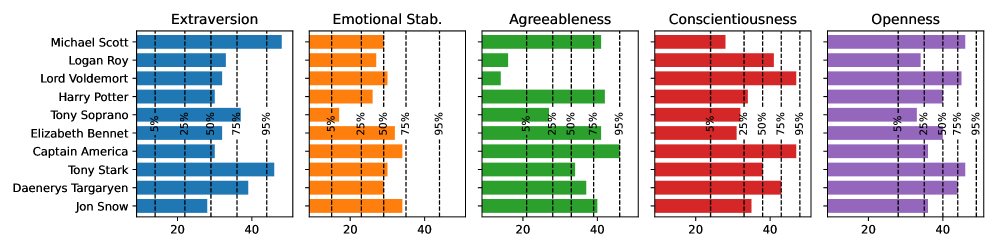
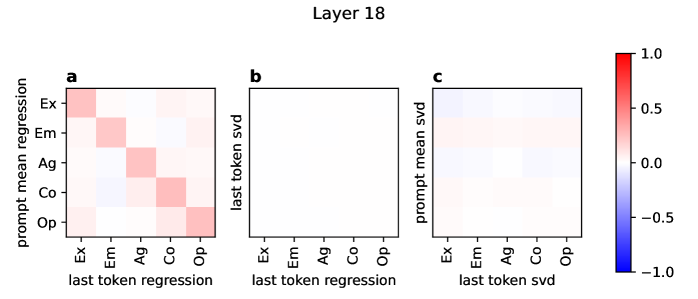
技术框架:该研究的技术框架主要包括以下几个步骤:1) 使用Llama 3.3 70B模型生成406个虚构角色的描述,并为每个角色分配五大人格特质得分。2) 使用这些角色描述和Alpaca问卷中的问题来提示模型,从而获得与不同性格特质相关的隐藏层激活。3) 使用线性回归方法,基于这些激活数据学习每层激活空间中的线性方向,这些方向与五大人格特质对齐。4) 通过沿着这些线性方向调整模型的激活,测试其在性格检测和性格引导方面的效果。
关键创新:该论文的关键创新在于将线性探针和引导技术应用于LLMs的性格控制。与传统的后训练和提示工程方法相比,线性探针和引导方法更加高效和灵活,可以在不改变模型参数的情况下,实现对模型行为的细粒度控制。此外,该研究还探索了线性方向在不同上下文下的引导能力,发现其效果受到上下文的显著影响。
关键设计:该研究的关键设计包括:1) 使用Llama 3.3 70B作为基础模型。2) 使用包含406个角色的数据集,每个角色都有明确的五大人格特质得分。3) 使用Alpaca问卷来生成提示,以获取与不同性格特质相关的激活。4) 使用线性回归学习每层激活空间中的线性方向。5) 通过强制选择任务和开放式生成任务来评估线性方向的引导能力。
🖼️ 关键图片
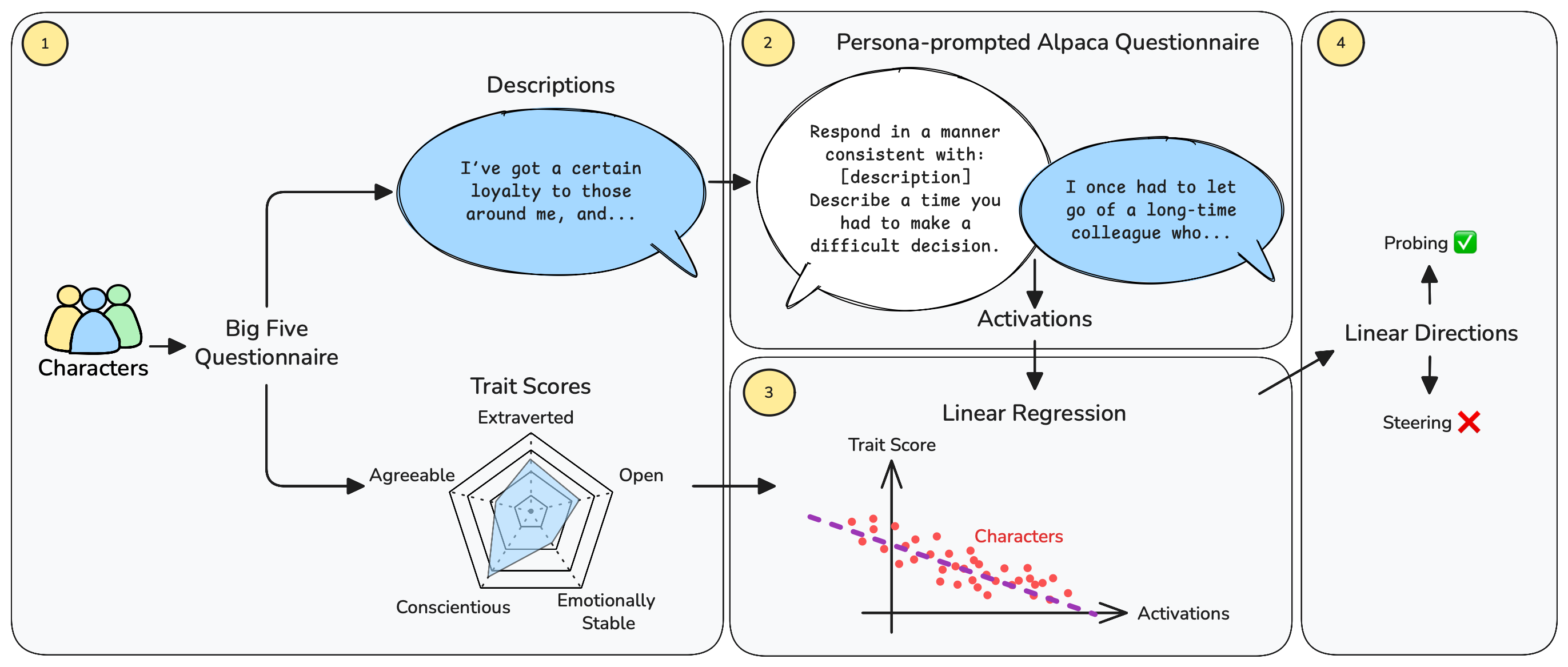
📊 实验亮点
实验结果表明,与人格特质得分对齐的线性方向是性格检测的有效探针。然而,其引导能力受到上下文的显著影响,在强制选择任务中表现良好,但在开放式生成或存在额外上下文时效果有限。这表明线性引导方法在特定场景下有效,但需要进一步研究以提高其在更复杂环境中的鲁棒性。
🎯 应用场景
该研究成果可应用于开发更具个性化和可控性的LLM应用,例如:创建具有特定性格特征的虚拟助手、在角色扮演游戏中控制NPC的行为、以及在心理健康领域提供更贴心的AI服务。此外,该方法还可以用于分析和理解LLM的内部运作机制,揭示性格特质在模型中的表征方式。
📄 摘要(原文)
Large language models (LLMs) exhibit distinct and consistent personalities that greatly impact trust and engagement. While this means that personality frameworks would be highly valuable tools to characterize and control LLMs' behavior, current approaches remain either costly (post-training) or brittle (prompt engineering). Probing and steering via linear directions has recently emerged as a cheap and efficient alternative. In this paper, we investigate whether linear directions aligned with the Big Five personality traits can be used for probing and steering model behavior. Using Llama 3.3 70B, we generate descriptions of 406 fictional characters and their Big Five trait scores. We then prompt the model with these descriptions and questions from the Alpaca questionnaire, allowing us to sample hidden activations that vary along personality traits in known, quantifiable ways. Using linear regression, we learn a set of per-layer directions in activation space, and test their effectiveness for probing and steering model behavior. Our results suggest that linear directions aligned with trait-scores are effective probes for personality detection, while their steering capabilities strongly depend on context, producing reliable effects in forced-choice tasks but limited influence in open-ended generation or when additional context is present in the prompt.