Benchmarking and Adapting On-Device Large Language Models for Clinical Decision Support
作者: Alif Munim, Jun Ma, Omar Ibrahim, Alhusain Abdalla, Shuolin Yin, Leo Chen, Bo Wang
分类: cs.CL, cs.AI
发布日期: 2025-12-18
💡 一句话要点
针对临床决策支持,评估并优化端侧大语言模型,实现隐私保护和高效部署。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 端侧大语言模型 临床决策支持 模型微调 隐私保护 医疗应用
📋 核心要点
- 现有临床决策支持系统依赖云端LLM,存在隐私泄露风险,且对网络环境有较高要求。
- 论文提出在端侧部署和优化LLM,通过模型压缩和微调,在保证性能的同时降低资源消耗。
- 实验表明,微调后的gpt-oss-20b在诊断准确性上接近GPT-5,验证了端侧LLM的潜力。
📝 摘要(中文)
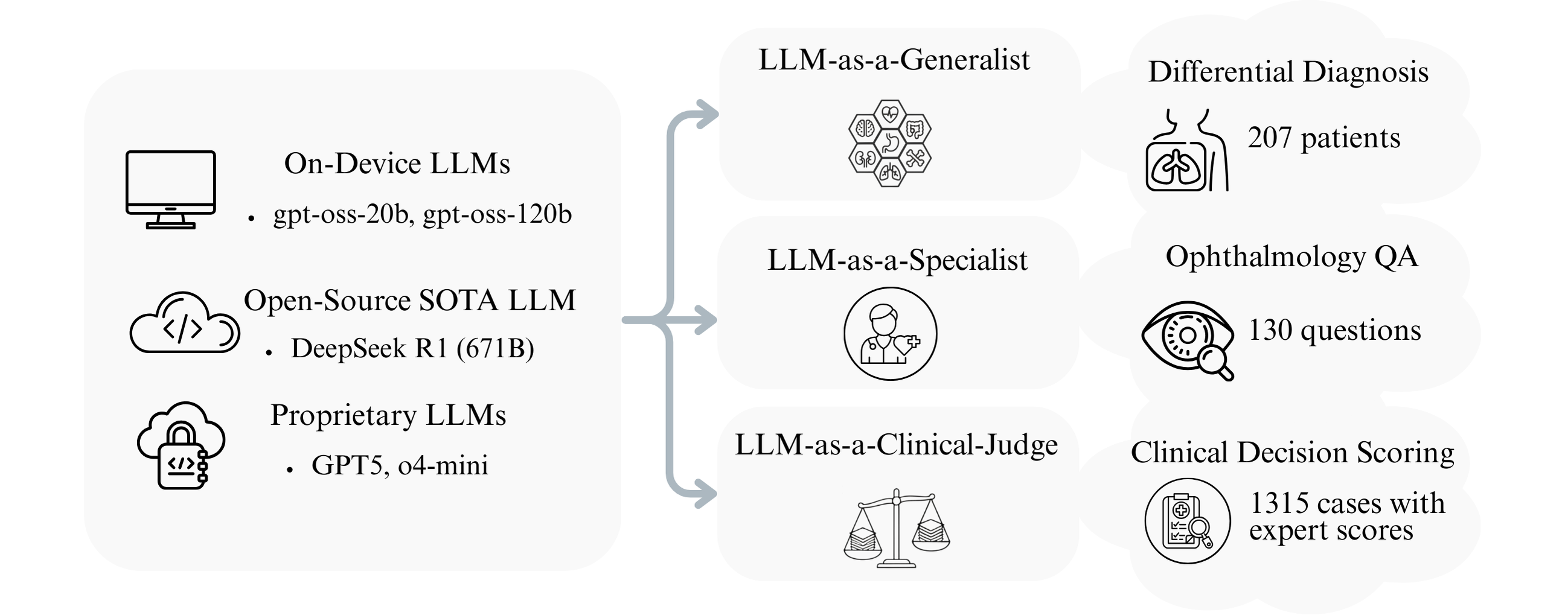
大型语言模型(LLM)在临床决策制定方面取得了快速进展,但专有系统的部署受到隐私问题和对云基础设施的依赖的阻碍。开源替代方案允许本地推理,但通常需要较大的模型尺寸,这限制了它们在资源受限的临床环境中的使用。本文对两个端侧LLM,gpt-oss-20b和gpt-oss-120b,在三个代表性的临床任务中进行了基准测试:一般疾病诊断、专科(眼科)诊断和管理,以及模拟人类专家评分和评估。我们将它们的性能与最先进的专有模型(GPT-5和o4-mini)和一个领先的开源模型(DeepSeek-R1)进行了比较,并进一步评估了端侧系统的适应性,通过在一般诊断数据上微调gpt-oss-20b。在各项任务中,gpt-oss模型的性能与DeepSeek-R1和o4-mini相当或超过它们,尽管尺寸小得多。此外,微调显著提高了gpt-oss-20b的诊断准确性,使其接近GPT-5的性能。这些发现突出了端侧LLM在提供准确、适应性强和保护隐私的临床决策支持方面的潜力,为更广泛地将LLM集成到常规临床实践中提供了一条切实可行的途径。
🔬 方法详解
问题定义:现有临床决策支持系统依赖云端LLM,存在隐私泄露风险,且需要稳定的网络连接。开源LLM虽然允许本地部署,但模型体积通常较大,难以在资源受限的临床环境中应用。因此,需要研究如何在端侧部署高性能、低资源消耗的LLM,同时保证临床决策的准确性。
核心思路:论文的核心思路是利用开源的、相对较小的LLM(gpt-oss-20b和gpt-oss-120b),通过基准测试评估其在临床任务中的性能,并通过微调进一步提升其准确性。选择较小的模型是为了适应端侧设备的资源限制,而微调则旨在利用特定领域的知识来提高模型在临床任务中的表现。
技术框架:整体框架包括三个阶段:1) 基准测试:在三个临床任务上评估gpt-oss-20b、gpt-oss-120b、DeepSeek-R1、GPT-5和o4-mini的性能。2) 微调:使用一般诊断数据对gpt-oss-20b进行微调。3) 性能比较:比较微调前后gpt-oss-20b的性能,以及与其他模型的性能。三个临床任务包括:一般疾病诊断、专科(眼科)诊断和管理、以及模拟人类专家评分和评估。
关键创新:论文的关键创新在于探索了在端侧部署和优化LLM用于临床决策支持的可能性。通过基准测试和微调,证明了相对较小的开源LLM在经过优化后,可以达到与大型专有模型相媲美的性能。这为在资源受限的环境中应用LLM提供了新的思路。
关键设计:微调过程使用了标准的反向传播算法,损失函数选择交叉熵损失。具体参数设置(如学习率、batch size等)未在摘要中明确提及,属于未知信息。论文重点在于验证微调策略的有效性,而非提出新的微调算法。
🖼️ 关键图片

📊 实验亮点
实验结果表明,gpt-oss模型在各项任务中表现与DeepSeek-R1和o4-mini相当甚至更好,尽管模型尺寸更小。通过微调,gpt-oss-20b的诊断准确性显著提高,接近GPT-5的水平。这表明,通过适当的优化,端侧LLM可以提供高性能的临床决策支持。
🎯 应用场景
该研究成果可应用于移动医疗设备、远程医疗平台和资源匮乏地区的诊所,为医生提供实时的、隐私保护的临床决策支持。通过端侧部署LLM,可以减少对云服务的依赖,降低数据泄露的风险,并提高医疗服务的可及性。未来,可以将该方法推广到其他医疗领域,并结合多模态数据,进一步提升临床决策的准确性和效率。
📄 摘要(原文)
Large language models (LLMs) have rapidly advanced in clinical decision-making, yet the deployment of proprietary systems is hindered by privacy concerns and reliance on cloud-based infrastructure. Open-source alternatives allow local inference but often require large model sizes that limit their use in resource-constrained clinical settings. Here, we benchmark two on-device LLMs, gpt-oss-20b and gpt-oss-120b, across three representative clinical tasks: general disease diagnosis, specialty-specific (ophthalmology) diagnosis and management, and simulation of human expert grading and evaluation. We compare their performance with state-of-the-art proprietary models (GPT-5 and o4-mini) and a leading open-source model (DeepSeek-R1), and we further evaluate the adaptability of on-device systems by fine-tuning gpt-oss-20b on general diagnostic data. Across tasks, gpt-oss models achieve performance comparable to or exceeding DeepSeek-R1 and o4-mini despite being substantially smaller. In addition, fine-tuning remarkably improves the diagnostic accuracy of gpt-oss-20b, enabling it to approach the performance of GPT-5. These findings highlight the potential of on-device LLMs to deliver accurate, adaptable, and privacy-preserving clinical decision support, offering a practical pathway for broader integration of LLMs into routine clinical practice.