Jailbreak-Zero: A Path to Pareto Optimal Red Teaming for Large Language Models
作者: Kai Hu, Abhinav Aggarwal, Mehran Khodabandeh, David Zhang, Eric Hsin, Li Chen, Ankit Jain, Matt Fredrikson, Akash Bharadwaj
分类: cs.CL, cs.CR, cs.LG
发布日期: 2025-12-18
备注: Socially Responsible and Trustworthy Foundation Models at NeurIPS 2025
💡 一句话要点
Jailbreak-Zero:一种面向大语言模型红队测试的帕累托最优方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 红队测试 对抗攻击 安全评估 偏好学习 漏洞挖掘 帕累托最优
📋 核心要点
- 现有LLM安全评估方法依赖于有限的示例,难以全面覆盖潜在的攻击策略和漏洞。
- Jailbreak-Zero利用攻击LLM生成大量多样化的对抗性提示,并通过偏好学习进行微调,实现帕累托最优。
- 实验表明,Jailbreak-Zero在攻击成功率上显著优于现有方法,且生成的提示更易读,人工干预更少。
📝 摘要(中文)
本文提出了一种名为Jailbreak-Zero的新型红队测试方法,它将大型语言模型(LLM)的安全评估范式从受约束的基于示例的方法转变为更具扩展性和有效性的基于策略的框架。通过利用攻击LLM生成大量多样化的对抗性提示,然后使用偏好数据集对该攻击模型进行微调,Jailbreak-Zero在策略覆盖率、攻击策略多样性和提示对真实用户输入的保真度等关键目标上实现了帕累托最优。经验证据表明了该方法的优越性,与现有的最先进技术相比,它对开源和专有模型(如GPT-40和Claude 3.5)的攻击成功率显著提高。重要的是,Jailbreak-Zero在最大限度地减少人工干预的同时,生成了人类可读且有效的对抗性提示,从而为识别和缓解LLM的安全漏洞提供了一种更具可扩展性和更全面的解决方案。
🔬 方法详解
问题定义:现有的大语言模型红队测试方法主要依赖于人工构造的少量对抗样本,无法充分覆盖各种可能的攻击场景和策略。这种方法效率低,且难以泛化到新的模型或攻击类型。因此,如何高效、全面地评估LLM的安全性,并发现潜在的漏洞,是一个亟待解决的问题。
核心思路:Jailbreak-Zero的核心思路是利用一个专门训练的攻击LLM,自动生成大量多样化的对抗性提示。通过对这些提示进行筛选和优化,使其既能成功攻击目标LLM,又能保持与真实用户输入的相似性。这种方法旨在实现策略覆盖率、攻击策略多样性和提示保真度之间的帕累托最优。
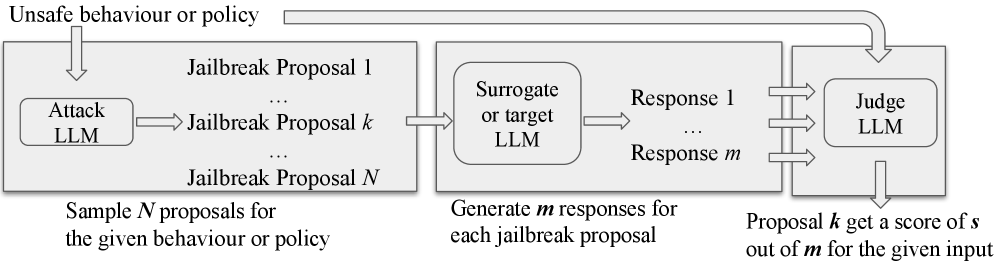
技术框架:Jailbreak-Zero的整体框架包含以下几个主要阶段:1) 使用攻击LLM生成初始的对抗性提示集合;2) 利用目标LLM评估这些提示的攻击成功率;3) 基于攻击成功率和提示保真度,构建偏好数据集;4) 使用偏好数据集对攻击LLM进行微调,使其能够生成更有效的对抗性提示。这个过程可以迭代进行,不断提升攻击LLM的性能。
关键创新:Jailbreak-Zero最重要的创新在于其基于策略的红队测试方法。与传统的基于示例的方法不同,Jailbreak-Zero通过训练一个攻击LLM,使其能够自动生成各种各样的对抗性提示,从而更全面地覆盖潜在的攻击空间。此外,Jailbreak-Zero还引入了偏好学习机制,以优化攻击LLM的性能,使其能够生成更有效、更自然的对抗性提示。
关键设计:在Jailbreak-Zero中,攻击LLM通常采用与目标LLM相似的架构,但规模较小,以降低训练成本。偏好数据集的构建至关重要,需要仔细设计评估指标和筛选策略,以确保数据的质量和多样性。损失函数的设计也需要考虑攻击成功率和提示保真度之间的平衡,以实现帕累托最优。
🖼️ 关键图片
📊 实验亮点
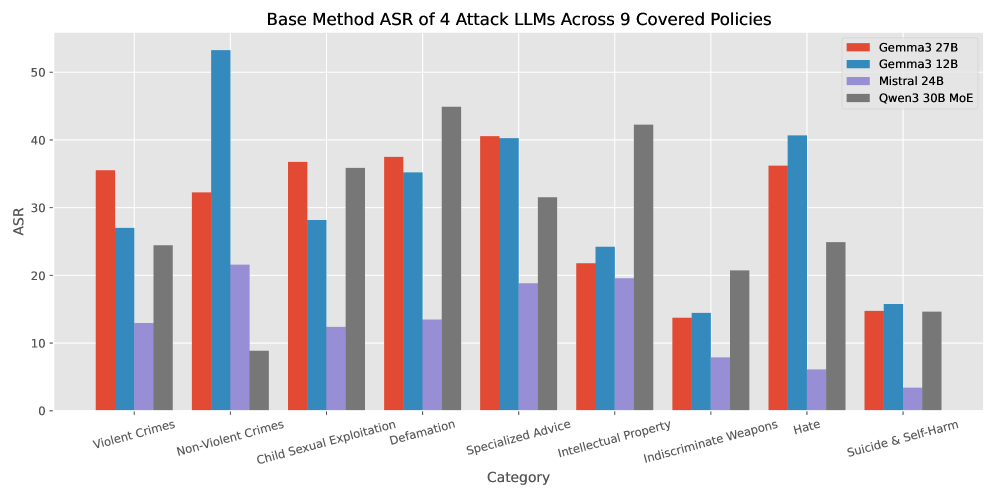
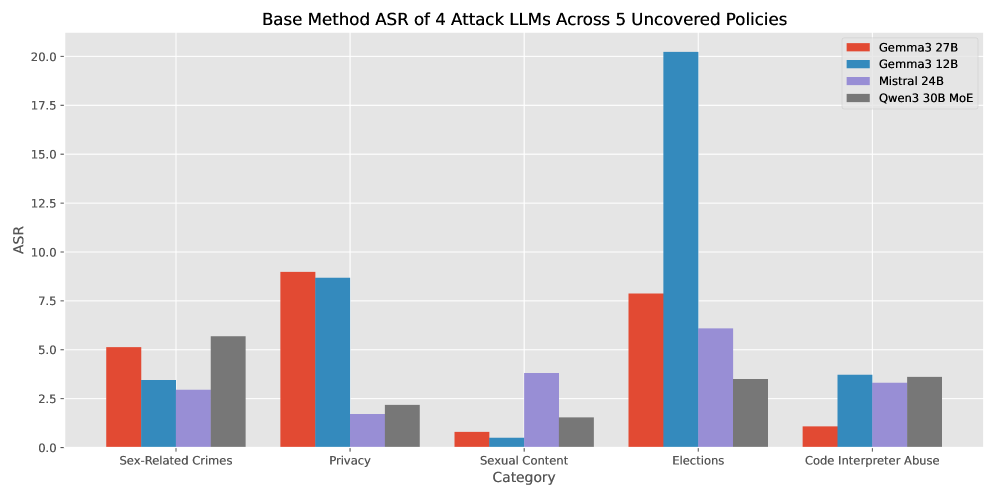
Jailbreak-Zero在对GPT-40和Claude 3.5等模型的攻击中,成功率显著高于现有方法。与现有技术相比,Jailbreak-Zero能够生成更具多样性和保真度的对抗性提示,同时最大限度地减少人工干预,实现了更高效、更全面的安全评估。
🎯 应用场景
Jailbreak-Zero可应用于大语言模型的安全评估、漏洞挖掘和防御策略开发。通过自动化生成对抗性提示,可以帮助开发者更全面地了解模型的安全风险,并及时修复漏洞。此外,该方法还可以用于评估不同防御策略的有效性,从而提升LLM的整体安全性。
📄 摘要(原文)
This paper introduces Jailbreak-Zero, a novel red teaming methodology that shifts the paradigm of Large Language Model (LLM) safety evaluation from a constrained example-based approach to a more expansive and effective policy-based framework. By leveraging an attack LLM to generate a high volume of diverse adversarial prompts and then fine-tuning this attack model with a preference dataset, Jailbreak-Zero achieves Pareto optimality across the crucial objectives of policy coverage, attack strategy diversity, and prompt fidelity to real user inputs. The empirical evidence demonstrates the superiority of this method, showcasing significantly higher attack success rates against both open-source and proprietary models like GPT-40 and Claude 3.5 when compared to existing state-of-the-art techniques. Crucially, Jailbreak-Zero accomplishes this while producing human-readable and effective adversarial prompts with minimal need for human intervention, thereby presenting a more scalable and comprehensive solution for identifying and mitigating the safety vulnerabilities of LLMs.