Emergent World Beliefs: Exploring Transformers in Stochastic Games
作者: Adam Kamel, Tanish Rastogi, Michael Ma, Kailash Ranganathan, Kevin Zhu
分类: cs.CL
发布日期: 2025-12-18
备注: Accepted at NeurIPS 2025 Mechanistic Interpretability Workshop
💡 一句话要点
探索Transformer在随机博弈中的涌现世界信念:以扑克为例
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 Transformer 不完全信息博弈 扑克 世界模型
📋 核心要点
- 现有研究表明LLM在完全信息博弈中能学习世界模型,但其在不完全信息博弈中的能力尚待探索。
- 本文利用GPT模型在扑克手牌历史数据上进行预训练,旨在研究LLM是否能学习扑克中的世界信念。
- 实验结果表明,LLM能够学习手牌等级和胜率等信息,并形成与理论信念状态相关的内部表征。
📝 摘要(中文)
基于Transformer的大型语言模型(LLM)在各个领域都表现出了强大的推理能力,从解决编程挑战到参与国际象棋等策略密集型游戏。先前的工作表明,LLM可以在完全信息博弈中发展出涌现世界模型,其中内部表征对应于环境的潜在状态。本文将这一研究扩展到不完全信息领域,重点关注扑克这一典型的部分可观察马尔可夫决策过程(POMDP)。我们在扑克手牌历史(PHH)数据上预训练了一个GPT风格的模型,并探测其内部激活。结果表明,该模型在没有明确指令的情况下,学习了确定性结构(如手牌等级)和随机特征(如胜率)。此外,通过主要使用非线性探针,我们证明了这些表征是可解码的,并且与理论信念状态相关,这表明LLM正在学习它们自己对德州扑克随机环境的表征。
🔬 方法详解
问题定义:本文旨在研究大型语言模型(LLM)在不完全信息博弈中是否能够学习并形成对环境的信念模型。现有方法主要集中在完全信息博弈中,对于像扑克这样的部分可观察马尔可夫决策过程(POMDP)的理解还不够深入。因此,本文旨在探索LLM在扑克游戏中学习世界信念的能力。
核心思路:核心思路是利用Transformer模型,特别是GPT架构,通过在大量的扑克手牌历史数据上进行预训练,使模型能够学习到扑克游戏中的规则、策略以及对手的行为模式。通过分析模型的内部激活,可以揭示模型是否以及如何构建对扑克环境的信念表征。
技术框架:整体框架包括数据预处理、模型预训练和内部表征探测三个主要阶段。首先,收集并清洗大量的扑克手牌历史数据。然后,使用GPT风格的模型在这些数据上进行预训练,使其学习扑克游戏的语言模式。最后,通过设计非线性探针,分析模型内部的激活状态,以确定模型是否学习到了手牌等级、胜率等关键信息,并将其与理论信念状态进行比较。
关键创新:关键创新在于将LLM应用于不完全信息博弈,并探索其涌现世界信念的能力。与以往主要关注完全信息博弈的研究不同,本文关注扑克这一典型的POMDP,并证明了LLM可以在没有明确指令的情况下学习到游戏中的确定性和随机性特征。
关键设计:模型采用GPT架构,并在大量的扑克手牌历史数据上进行预训练。关键设计包括使用非线性探针来解码模型的内部表征,以及将这些表征与理论信念状态进行比较。损失函数采用标准的语言模型损失,目标是最大化给定历史手牌序列的下一个手牌的概率。网络结构采用标准的Transformer结构,包括多头自注意力机制和前馈神经网络。
🖼️ 关键图片

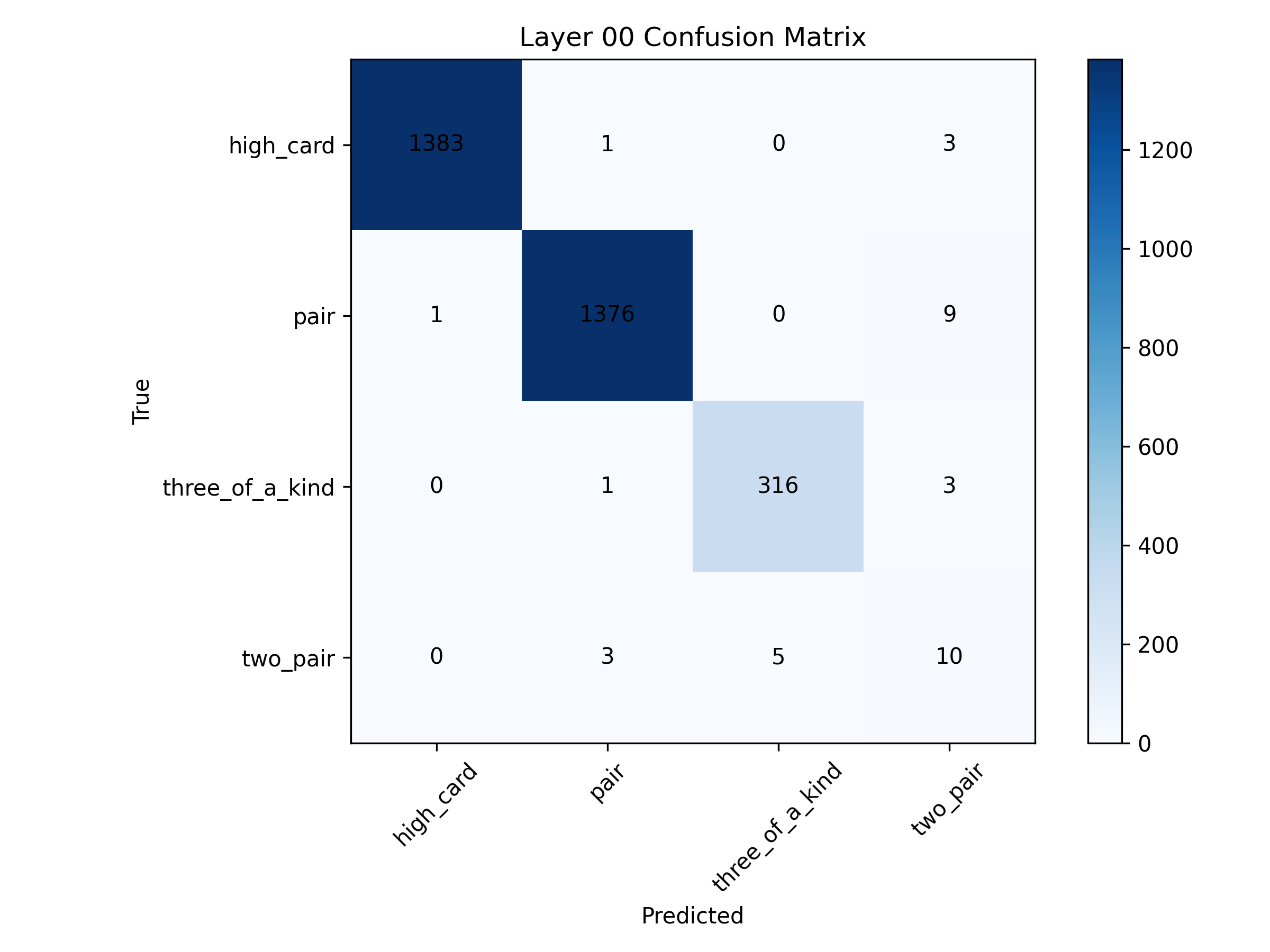
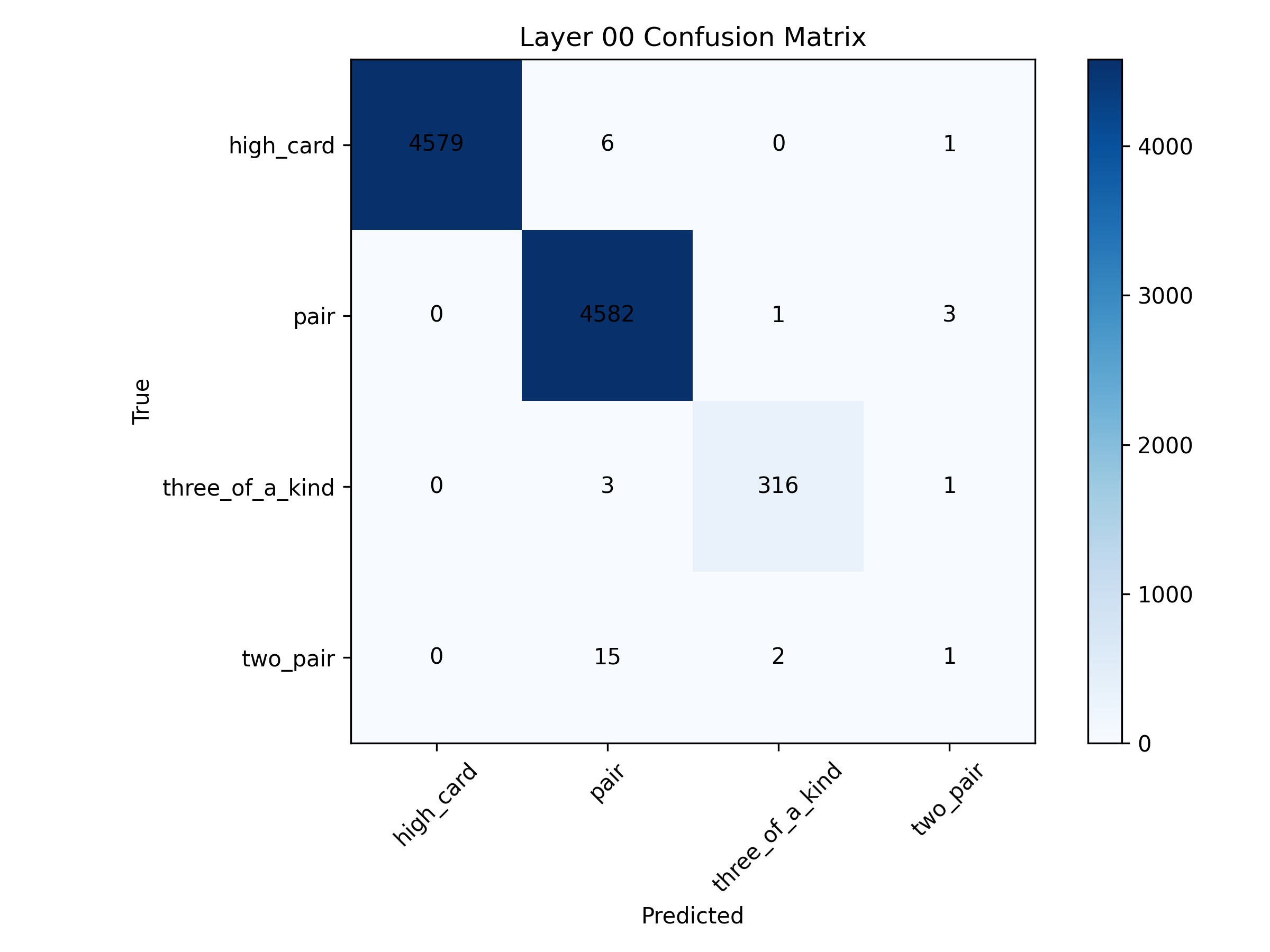
📊 实验亮点
实验结果表明,预训练的GPT模型能够学习扑克手牌的等级和胜率等关键信息,并且其内部表征与理论信念状态高度相关。这表明LLM能够在不完全信息博弈中涌现出对环境的信念模型,为LLM在复杂决策任务中的应用提供了新的可能性。
🎯 应用场景
该研究成果可应用于开发更智能的博弈AI,例如扑克机器人,以及在其他不完全信息环境下的决策系统。此外,该研究有助于理解LLM如何学习和表示世界知识,为开发更通用的人工智能系统提供理论基础。
📄 摘要(原文)
Transformer-based large language models (LLMs) have demonstrated strong reasoning abilities across diverse fields, from solving programming challenges to competing in strategy-intensive games such as chess. Prior work has shown that LLMs can develop emergent world models in games of perfect information, where internal representations correspond to latent states of the environment. In this paper, we extend this line of investigation to domains of incomplete information, focusing on poker as a canonical partially observable Markov decision process (POMDP). We pretrain a GPT-style model on Poker Hand History (PHH) data and probe its internal activations. Our results demonstrate that the model learns both deterministic structure, such as hand ranks, and stochastic features, such as equity, without explicit instruction. Furthermore, by using primarily nonlinear probes, we demonstrated that these representations are decodeable and correlate with theoretical belief states, suggesting that LLMs are learning their own representation of the stochastic environment of Texas Hold'em Poker.