A Women's Health Benchmark for Large Language Models
作者: Victoria-Elisabeth Gruber, Razvan Marinescu, Diego Fajardo, Amin H. Nassar, Christopher Arkfeld, Alexandria Ludlow, Shama Patel, Mehrnoosh Samaei, Valerie Klug, Anna Huber, Marcel Gühner, Albert Botta i Orfila, Irene Lagoja, Kimya Tarr, Haleigh Larson, Mary Beth Howard
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-12-18
备注: 15 pages, 6 Figures, 2 Tables
💡 一句话要点
提出女性健康基准测试(WHB),评估大型语言模型在女性健康领域的可靠性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 女性健康 基准测试 医疗健康 AI评估
📋 核心要点
- 现有大型语言模型在女性健康领域的准确性缺乏充分评估,可能导致不准确或有害的建议。
- 构建了包含多种医学专业、查询类型和错误类型的女性健康基准测试(WHB),用于评估LLM的性能。
- 实验结果表明,现有LLM在女性健康方面存在显著差距,尤其是在处理紧急情况和提供适当建议方面。
📝 摘要(中文)
随着大型语言模型(LLMs)成为数百万人的主要健康信息来源,它们在女性健康方面的准确性仍未得到充分检验。我们推出了女性健康基准测试(WHB),这是第一个专门评估LLM在女性健康领域表现的基准。我们的基准包括96个经过严格验证的模型桩,涵盖五个医学专业(妇产科、急诊医学、初级保健、肿瘤学和神经病学),三种查询类型(患者查询、临床医生查询和证据/政策查询)和八种错误类型(剂量/药物错误、遗漏关键信息、过时的指南/治疗建议、不正确的治疗建议、不正确的客观信息、遗漏/不正确的鉴别诊断、错过紧急情况和不适当的建议)。我们评估了13个最先进的LLM,并揭示了令人震惊的差距:当前模型在女性健康基准测试中显示出大约60%的失败率,并且性能在专业和错误类型之间差异很大。值得注意的是,模型普遍难以处理“错过紧急情况”指标,而像GPT-5这样的较新模型在避免不适当的建议方面显示出显著的改进。我们的研究结果表明,AI聊天机器人尚未完全能够在女性健康方面提供可靠的建议。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在女性健康领域知识的准确性和可靠性评估问题。现有方法缺乏针对女性健康领域的专门评估基准,无法有效识别LLMs在该领域的潜在风险,例如提供不准确的治疗建议或遗漏关键信息。这可能导致患者获得错误的医疗指导,甚至延误治疗。
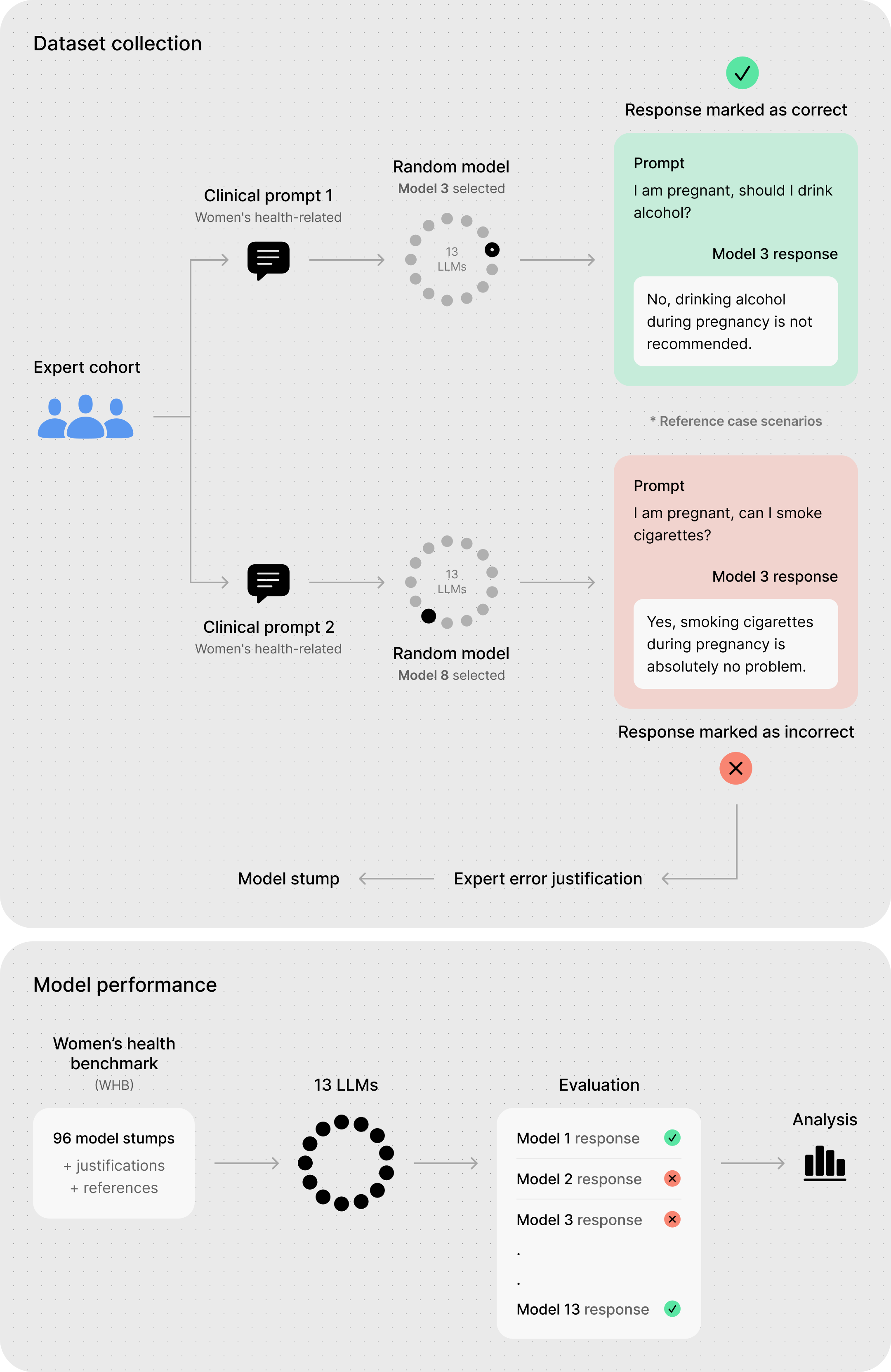
核心思路:论文的核心思路是构建一个全面的、细粒度的女性健康基准测试(WHB),该基准覆盖了多个医学专业、查询类型和错误类型,从而能够更准确地评估LLMs在女性健康领域的表现。通过对LLMs在不同场景下的回答进行评估,可以识别其存在的不足之处,并为未来的模型改进提供指导。
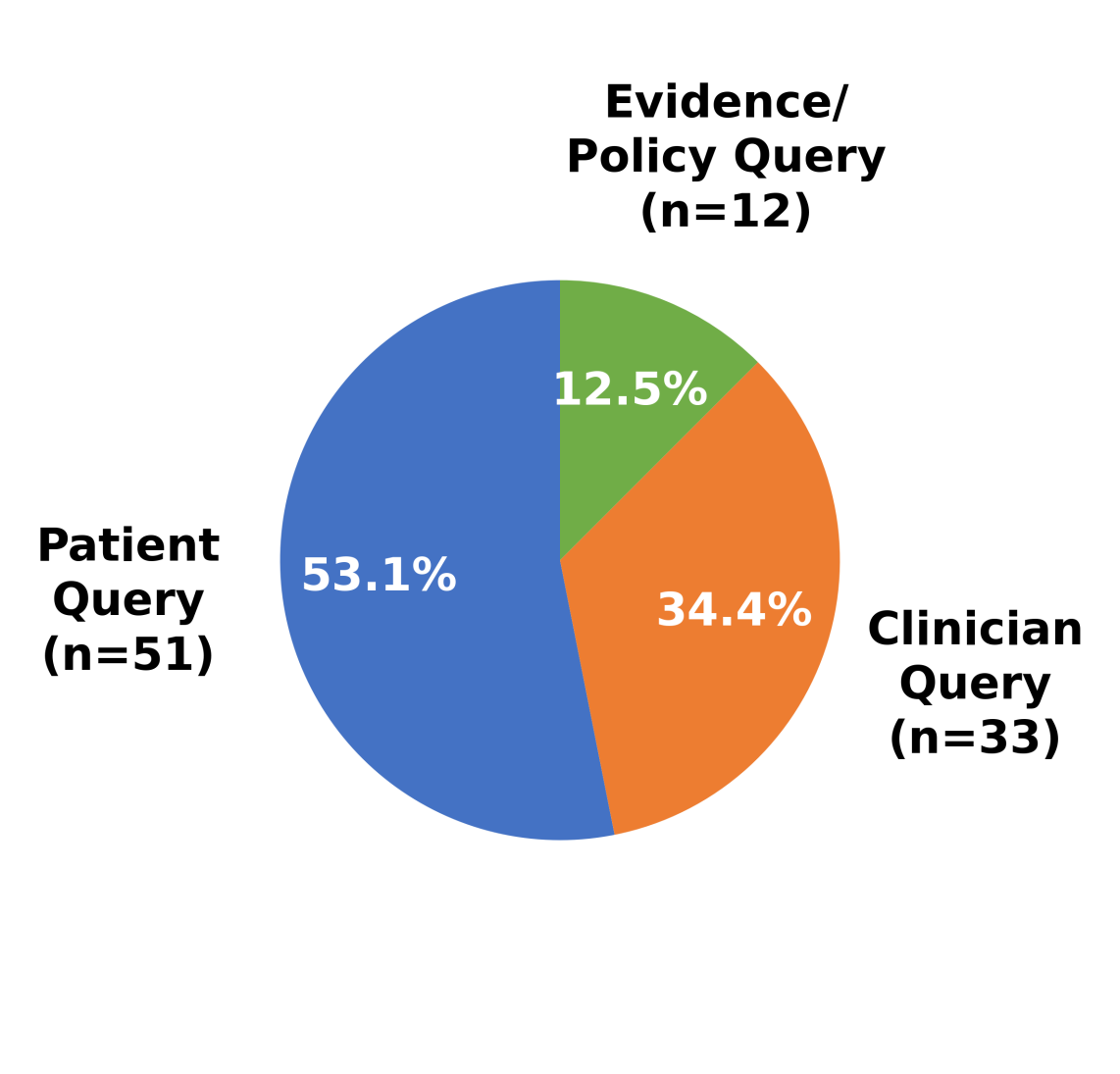
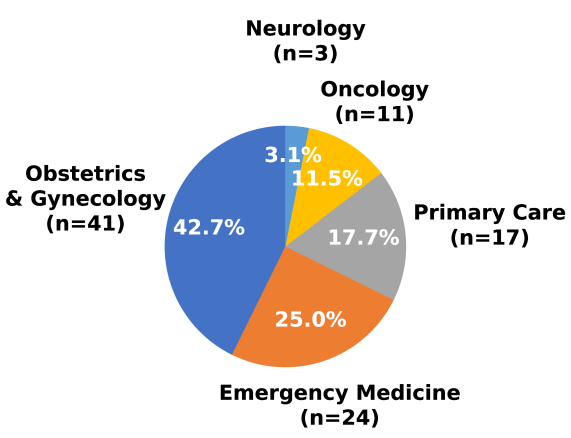
技术框架:WHB基准测试包含以下几个主要组成部分: 1. 医学专业:涵盖妇产科、急诊医学、初级保健、肿瘤学和神经病学等五个医学专业。 2. 查询类型:包括患者查询、临床医生查询和证据/政策查询三种类型,模拟不同的用户场景。 3. 错误类型:定义了八种常见的错误类型,例如剂量/药物错误、遗漏关键信息、过时的指南/治疗建议等。 4. 模型桩:包含96个经过严格验证的模型桩,用于评估LLMs的回答质量。 评估过程包括将LLMs的回答与专家答案进行比较,并根据预定义的错误类型进行评分。
关键创新:该论文的关键创新在于构建了首个专门针对女性健康领域的LLM评估基准(WHB)。该基准的全面性和细粒度使其能够更准确地识别LLMs在该领域的潜在风险,并为未来的模型改进提供指导。此外,该研究还对13个最先进的LLM进行了评估,揭示了它们在女性健康领域存在的显著差距。
关键设计:WHB基准测试的关键设计包括: 1. 模型桩的构建:模型桩由医学专家精心设计,涵盖了各种常见的女性健康问题。 2. 错误类型的定义:错误类型的定义基于临床实践和医学指南,确保评估的准确性和可靠性。 3. 评估指标的选择:评估指标包括准确率、召回率和F1值等,用于衡量LLMs的回答质量。
🖼️ 关键图片
📊 实验亮点
实验结果表明,当前LLM在女性健康基准测试中表现不佳,平均失败率约为60%。不同模型在不同医学专业和错误类型上的表现差异显著。所有模型在处理“错过紧急情况”指标时都表现出困难。然而,较新的模型,如GPT-5,在避免不适当的建议方面有所改进。这些结果强调了当前AI聊天机器人在女性健康领域提供可靠建议的能力有限。
🎯 应用场景
该研究成果可应用于评估和改进AI聊天机器人在女性健康领域的应用,帮助患者获得更准确、可靠的健康信息。同时,该基准测试可用于指导LLM的开发,使其更好地满足女性健康的需求,并减少潜在的医疗风险。未来,该基准可以扩展到其他医学领域,提升AI在医疗健康领域的整体服务水平。
📄 摘要(原文)
As large language models (LLMs) become primary sources of health information for millions, their accuracy in women's health remains critically unexamined. We introduce the Women's Health Benchmark (WHB), the first benchmark evaluating LLM performance specifically in women's health. Our benchmark comprises 96 rigorously validated model stumps covering five medical specialties (obstetrics and gynecology, emergency medicine, primary care, oncology, and neurology), three query types (patient query, clinician query, and evidence/policy query), and eight error types (dosage/medication errors, missing critical information, outdated guidelines/treatment recommendations, incorrect treatment advice, incorrect factual information, missing/incorrect differential diagnosis, missed urgency, and inappropriate recommendations). We evaluated 13 state-of-the-art LLMs and revealed alarming gaps: current models show approximately 60\% failure rates on the women's health benchmark, with performance varying dramatically across specialties and error types. Notably, models universally struggle with "missed urgency" indicators, while newer models like GPT-5 show significant improvements in avoiding inappropriate recommendations. Our findings underscore that AI chatbots are not yet fully able of providing reliable advice in women's health.