Multimodal RewardBench 2: Evaluating Omni Reward Models for Interleaved Text and Image
作者: Yushi Hu, Reyhane Askari-Hemmat, Melissa Hall, Emily Dinan, Luke Zettlemoyer, Marjan Ghazvininejad
分类: cs.CL, cs.CV
发布日期: 2025-12-18 (更新: 2026-01-19)
备注: Code and data available at https://github.com/facebookresearch/MMRB2
💡 一句话要点
提出Multimodal RewardBench 2 (MMRB2),用于评估多模态奖励模型在图文交错场景下的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 奖励模型 图文交错 评估基准 大型语言模型
📋 核心要点
- 现有奖励模型在处理图文交错的多模态数据时能力不足,缺乏专门的评估基准。
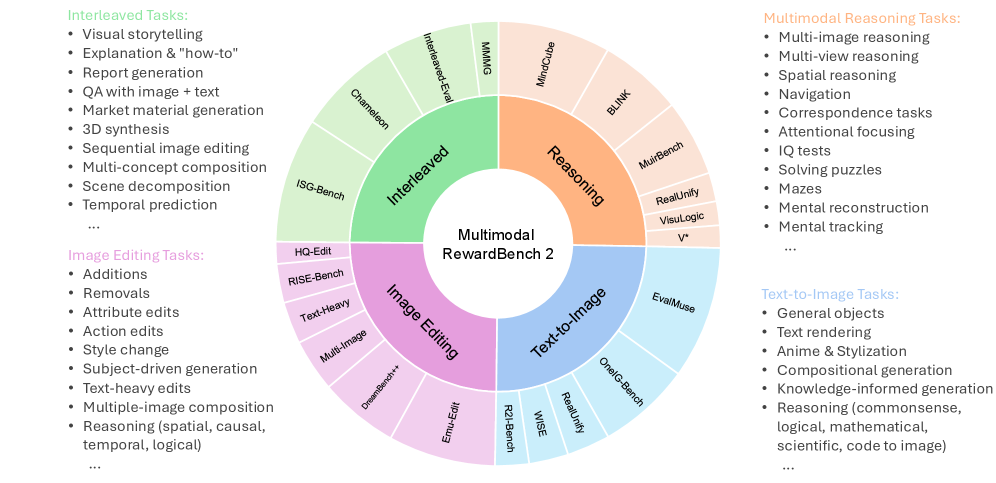
- MMRB2基准包含四个任务,利用专家标注的偏好对,全面评估多模态奖励模型的理解和生成能力。
- 实验结果表明,Gemini 3 Pro等模型在MMRB2上表现优异,开源模型Qwen3-VL-32B也具有竞争力。
📝 摘要(中文)
奖励模型(RMs)对于训练大型语言模型(LLMs)至关重要,但对于处理交错图像和文本序列的全能模型的研究仍然不足。我们推出了Multimodal RewardBench 2(MMRB2),这是第一个全面的奖励模型基准,用于多模态理解和(交错)生成。MMRB2涵盖四个任务:文本到图像、图像编辑、交错生成和多模态推理(“用图像思考”),每个任务提供1000个专家标注的偏好对,这些数据来自23个模型和代理,涵盖21个源任务。MMRB2的设计特点包括:(1)实用但具有挑战性的提示;(2)来自最先进模型和代理的响应;(3)通过集成过滤策略策划的具有强烈人类专家共识的偏好对。我们使用MMRB2研究了每个子任务的现有评判标准,包括多模态LLM-as-a-judge和使用人类偏好训练的模型。最新的Gemini 3 Pro达到了75-80%的准确率。GPT-5和Gemini 2.5 Pro达到了66-75%的准确率,而GPT-4o的准确率仅为59%,人类则超过90%。性能最佳的开源模型Qwen3-VL-32B实现了与Gemini 2.5 Flash(64%)相似的准确率。我们还表明,MMRB2的性能与使用Best-of-N抽样的下游任务成功率密切相关,并进行了深入分析,揭示了未来改进奖励模型的关键领域。
🔬 方法详解
问题定义:论文旨在解决多模态奖励模型在图文交错场景下缺乏有效评估的问题。现有的奖励模型和评估方法主要集中在文本领域,难以直接应用于多模态任务,尤其是在处理图像和文本交错生成时,评估的准确性和可靠性面临挑战。
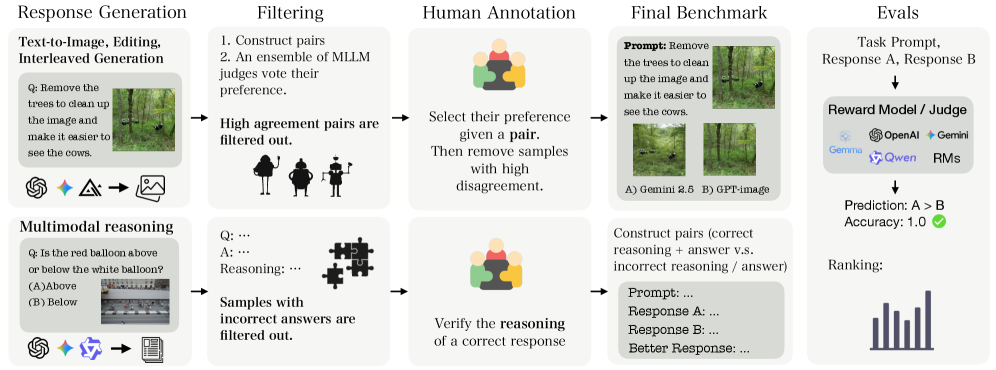
核心思路:论文的核心思路是构建一个全面的多模态奖励模型评估基准,即MMRB2。该基准通过收集高质量的图文交错数据,并由人类专家进行标注,形成偏好对,从而为奖励模型的训练和评估提供可靠的数据基础。同时,基准的设计考虑了实际应用场景,包含具有挑战性的提示和来自先进模型的响应。
技术框架:MMRB2基准主要包含以下几个关键组成部分:1)任务定义:包括文本到图像生成、图像编辑、交错生成和多模态推理四个任务。2)数据收集:从21个源任务中收集数据,涵盖23个模型和代理的输出。3)偏好标注:由人类专家对模型输出进行偏好标注,形成偏好对。4)质量控制:采用集成过滤策略,确保偏好对具有高度的人类专家共识。5)评估指标:使用准确率等指标评估奖励模型的性能。
关键创新:MMRB2的关键创新在于它是第一个专门针对多模态奖励模型的综合性评估基准,特别是针对图文交错的场景。它不仅提供了高质量的数据集,还设计了合理的评估流程,能够更准确地反映奖励模型在多模态任务中的性能。此外,MMRB2还采用了集成过滤策略,提高了偏好标注的质量和可靠性。
关键设计:MMRB2的关键设计包括:1)提示设计:采用实用但具有挑战性的提示,模拟真实应用场景。2)模型选择:选择最先进的模型和代理,确保评估结果具有代表性。3)标注策略:采用多人标注和集成过滤,提高标注质量。4)任务多样性:涵盖四个不同的多模态任务,全面评估奖励模型的性能。
🖼️ 关键图片

📊 实验亮点
实验结果表明,最新的Gemini 3 Pro在MMRB2上达到了75-80%的准确率,GPT-5和Gemini 2.5 Pro达到了66-75%的准确率,超过了GPT-4o(59%)。开源模型Qwen3-VL-32B的性能与Gemini 2.5 Flash(64%)相当。MMRB2的性能与下游任务的成功率高度相关,验证了该基准的有效性。
🎯 应用场景
该研究成果可应用于训练和评估多模态大型语言模型,提升模型在图文生成、图像编辑和多模态推理等任务中的性能。高质量的奖励模型能够更好地对齐模型输出与人类偏好,从而提高用户体验和应用价值。未来,该基准可以促进多模态人工智能领域的发展。
📄 摘要(原文)
Reward models (RMs) are essential for training large language models (LLMs), but remain underexplored for omni models that handle interleaved image and text sequences. We introduce Multimodal RewardBench 2 (MMRB2), the first comprehensive benchmark for reward models on multimodal understanding and (interleaved) generation. MMRB2 spans four tasks: text-to-image, image editing, interleaved generation, and multimodal reasoning ("thinking-with-images"), providing 1,000 expert-annotated preference pairs per task from 23 models and agents across 21 source tasks. MMRB2 is designed with: (1) practical but challenging prompts; (2) responses from state-of-the-art models and agents; and (3) preference pairs with strong human-expert consensus, curated via an ensemble filtering strategy. Using MMRB2, we study existing judges for each subtask, including multimodal LLM-as-a-judge and models trained with human preferences. The latest Gemini 3 Pro attains 75-80% accuracy. GPT-5 and Gemini 2.5 Pro reach 66-75% accuracy, compared to >90% for humans, yet surpass the widely used GPT-4o (59%). The best performing open-source model Qwen3-VL-32B achieves similar accuracies as Gemini 2.5 Flash (64%). We also show that MMRB2 performance strongly correlates with downstream task success using Best-of-N sampling and conduct an in-depth analysis that shows key areas to improve the reward models going forward.