Sigma-MoE-Tiny Technical Report
作者: Qingguo Hu, Zhenghao Lin, Ziyue Yang, Yucheng Ding, Xiao Liu, Yuting Jiang, Ruizhe Wang, Tianyu Chen, Zhongxin Guo, Yifan Xiong, Rui Gao, Lei Qu, Jinsong Su, Peng Cheng, Yeyun Gong
分类: cs.CL, cs.AI
发布日期: 2025-12-18 (更新: 2025-12-19)
🔗 代码/项目: GITHUB | PROJECT_PAGE
💡 一句话要点
提出Sigma-MoE-Tiny,一种高稀疏MoE语言模型,解决专家负载均衡难题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 混合专家模型 MoE 稀疏模型 负载均衡 渐进式稀疏化 语言模型 Transformer
📋 核心要点
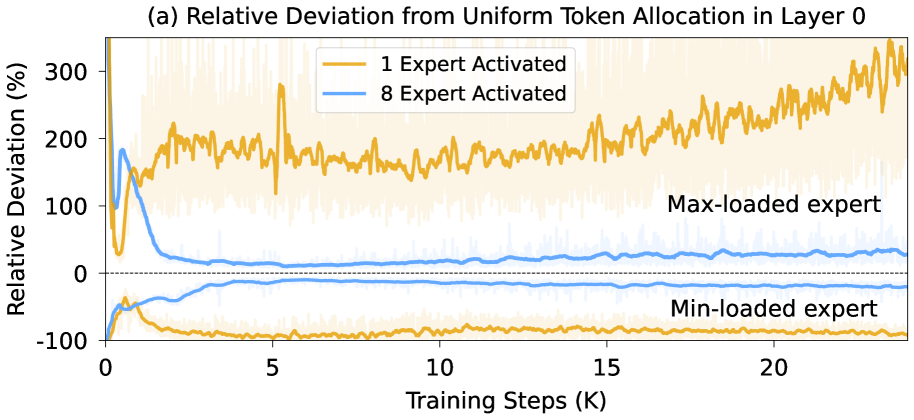
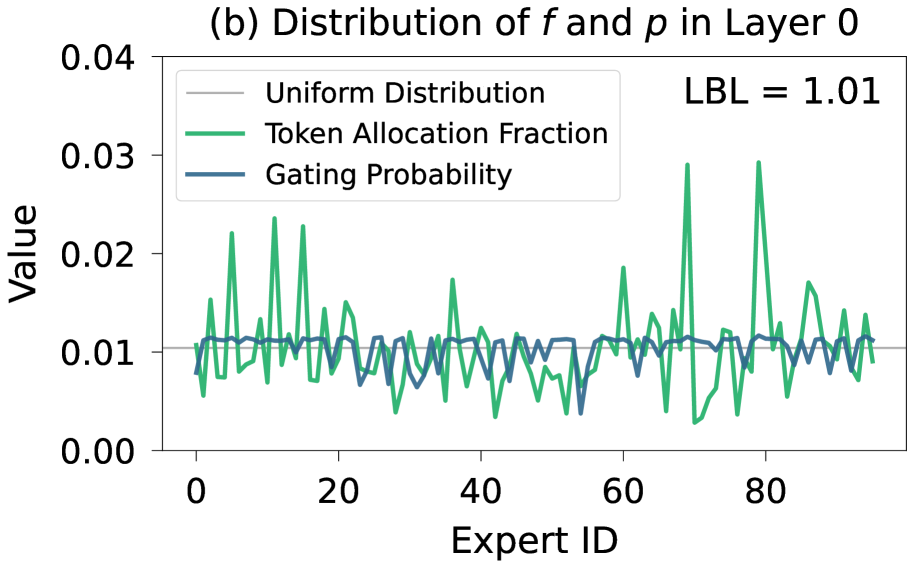
- 现有MoE模型在极端稀疏性下,专家负载均衡面临挑战,传统负载均衡损失在较低层失效。
- 提出渐进式稀疏化策略,平衡专家利用率和训练稳定性,解决高稀疏性下的负载均衡问题。
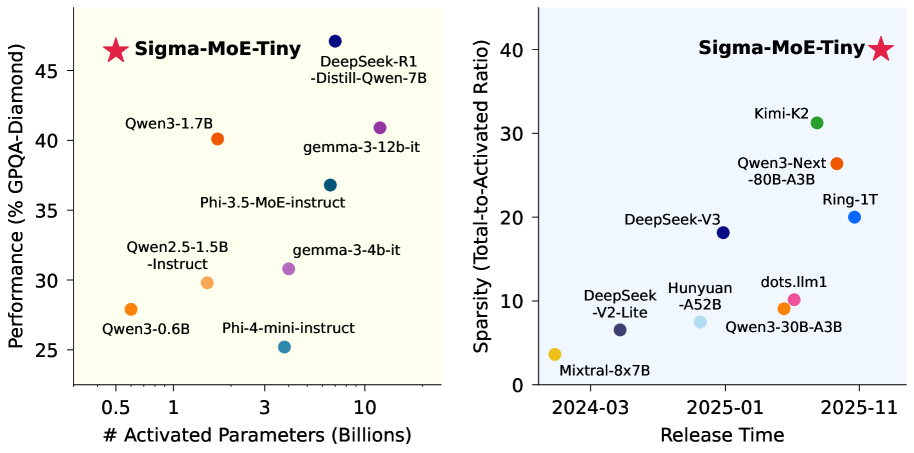
- Sigma-MoE-Tiny仅激活0.5B参数,但在同等或更大规模模型中表现出色,训练过程稳定。
📝 摘要(中文)
本文提出了Sigma-MoE-Tiny,一种混合专家(MoE)语言模型,与现有开源模型相比,实现了最高的稀疏性。Sigma-MoE-Tiny采用细粒度的专家分割,每层最多有96个专家,但每个token仅激活一个专家,从而在总参数量为200亿的情况下,仅激活0.5B参数。这种极端稀疏性带来的主要挑战是专家负载均衡。研究发现,在这种设置下,广泛使用的负载均衡损失在较低层中往往失效。为了解决这个问题,本文提出了一种渐进式稀疏化策略,旨在平衡专家利用率和训练稳定性。Sigma-MoE-Tiny在一个多样化和高质量的语料库上进行预训练,然后进行后训练以进一步释放其能力。整个训练过程保持了显著的稳定性,没有出现不可恢复的损失峰值。全面的评估表明,尽管仅激活0.5B参数,Sigma-MoE-Tiny在同等或更大规模的同类模型中实现了顶级的性能。此外,本文还深入讨论了高稀疏MoE模型中的负载均衡问题,为未来MoE架构中提高稀疏性提供了见解。
🔬 方法详解
问题定义:论文旨在解决混合专家模型(MoE)中,在极高稀疏性下专家负载不均衡的问题。现有的负载均衡损失在高稀疏度下,尤其是在模型的浅层,效果不佳,导致部分专家过度使用,而另一些专家利用率不足,影响模型整体性能。
核心思路:论文的核心思路是通过渐进式稀疏化策略来解决专家负载均衡问题。该策略通过在训练初期保持较低的稀疏度,使得所有专家都有机会被训练,从而避免早期就出现专家利用率差异过大的情况。随着训练的进行,逐渐增加稀疏度,最终达到目标稀疏度。这样可以保证在整个训练过程中,专家之间的负载相对均衡。
技术框架:Sigma-MoE-Tiny的整体架构基于Transformer模型,并在Transformer层中引入MoE结构。每个MoE层包含多个专家(高达96个),但每个token只激活一个专家。训练过程分为预训练和后训练两个阶段。预训练阶段使用大规模高质量语料库,后训练阶段进一步提升模型性能。关键在于训练过程中使用的渐进式稀疏化策略。
关键创新:论文最重要的技术创新点是提出的渐进式稀疏化策略。与传统的固定稀疏度训练方法不同,该策略允许在训练初期保持较低的稀疏度,随着训练的进行逐步增加稀疏度。这种方法能够有效避免早期专家利用率不均衡的问题,从而提高模型的整体性能和训练稳定性。
关键设计:渐进式稀疏化策略的关键设计在于如何控制稀疏度的变化。论文中可能采用了一种schedule函数来控制稀疏度随训练步数的变化。此外,专家选择机制(例如,使用Top-K门控)以及负载均衡损失的具体形式也是重要的设计细节。具体的参数设置,比如初始稀疏度、最终稀疏度以及稀疏度变化的速率,都会影响模型的性能和训练稳定性。论文中可能还对损失函数进行了调整,以更好地适应高稀疏度MoE模型的训练。
🖼️ 关键图片
📊 实验亮点
Sigma-MoE-Tiny在激活仅0.5B参数的情况下,在多个benchmark上取得了与参数量更大模型相当甚至更优的性能。这表明其在高稀疏度下依然能够有效利用模型容量。训练过程表现出极高的稳定性,没有出现不可恢复的损失峰值,验证了渐进式稀疏化策略的有效性。
🎯 应用场景
Sigma-MoE-Tiny的研究成果可应用于各种需要高效和可扩展语言模型的场景,例如:智能对话系统、机器翻译、文本摘要、代码生成等。其高稀疏性使得模型可以在资源受限的设备上部署,降低了计算成本和能耗。未来,该技术有望推动更大规模、更高效的AI模型的开发和应用。
📄 摘要(原文)
Mixture-of-Experts (MoE) has emerged as a promising paradigm for foundation models due to its efficient and powerful scalability. In this work, we present Sigma-MoE-Tiny, an MoE language model that achieves the highest sparsity compared to existing open-source models. Sigma-MoE-Tiny employs fine-grained expert segmentation with up to 96 experts per layer, while activating only one expert for each token, resulting in 20B total parameters with just 0.5B activated. The major challenge introduced by such extreme sparsity lies in expert load balancing. We find that the widely-used load balancing loss tends to become ineffective in the lower layers under this setting. To address this issue, we propose a progressive sparsification schedule aiming to balance expert utilization and training stability. Sigma-MoE-Tiny is pre-trained on a diverse and high-quality corpus, followed by post-training to further unlock its capabilities. The entire training process remains remarkably stable, with no occurrence of irrecoverable loss spikes. Comprehensive evaluations reveal that, despite activating only 0.5B parameters, Sigma-MoE-Tiny achieves top-tier performance among counterparts of comparable or significantly larger scale. In addition, we provide an in-depth discussion of load balancing in highly sparse MoE models, offering insights for advancing sparsity in future MoE architectures. Project page: https://qghuxmu.github.io/Sigma-MoE-Tiny Code: https://github.com/microsoft/ltp-megatron-lm