LoPA: Scaling dLLM Inference via Lookahead Parallel Decoding
作者: Chenkai Xu, Yijie Jin, Jiajun Li, Yi Tu, Guoping Long, Dandan Tu, Mingcong Song, Hongjie Si, Tianqi Hou, Junchi Yan, Zhijie Deng
分类: cs.CL
发布日期: 2025-12-18 (更新: 2025-12-22)
🔗 代码/项目: GITHUB
💡 一句话要点
LoPA:通过前瞻并行解码加速扩散大语言模型推理
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 扩散大语言模型 并行解码 Token填充顺序 推理加速 多设备推理
📋 核心要点
- 现有扩散大语言模型推理受限于置信度驱动的解码策略,并行度低,严重影响推理速度。
- LoPA通过并行探索不同的Token填充顺序,并基于置信度选择最优顺序,从而提高并行度。
- 实验表明,LoPA显著提高了D2F模型的解码效率,在GSM8K上实现了更高的TPF和性能。
📝 摘要(中文)
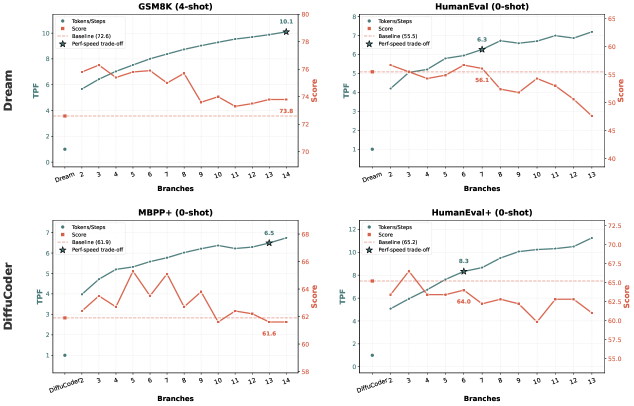
扩散大语言模型(dLLMs)在高速推理方面展现出巨大潜力。然而,目前基于置信度的解码策略受到有限并行性的制约,通常每次前向传播只能实现1-3个token。本文发现,dLLM推理过程中的并行度对Token填充顺序(TFO)高度敏感。因此,我们引入了前瞻并行解码LoPA,这是一种无需训练、即插即用的算法,用于识别更优的TFO,从而加速推理。LoPA通过并行分支同时探索不同的候选TFO,并根据分支置信度选择未来并行潜力最大的一个。我们将LoPA应用于最先进的D2F模型,观察到解码效率的显著提高。值得注意的是,LoPA将D2F-Dream在GSM8K上的TPF提高到10.1,同时保持了优于Dream基线的性能。此外,为了支持这种前所未有的并行度,我们开发了一种专门的多设备推理系统,该系统具有分支并行性(BP),在多GPU部署下实现了每秒1073.9个token的单样本吞吐量。代码已开源。
🔬 方法详解
问题定义:扩散大语言模型(dLLMs)的推理速度受限于其解码过程的并行度。现有的基于置信度的解码策略,由于Token填充顺序(TFO)的限制,导致并行度较低,通常每次前向传播只能生成少量token。这成为了dLLM实际应用中的一个瓶颈。
核心思路:LoPA的核心思路是通过探索和选择更优的Token填充顺序(TFO)来提高dLLM推理的并行度。它认为不同的TFO会导致不同的并行潜力,因此通过并行探索多个候选TFO,并根据置信度选择最有希望的TFO,从而实现更高的并行解码效率。
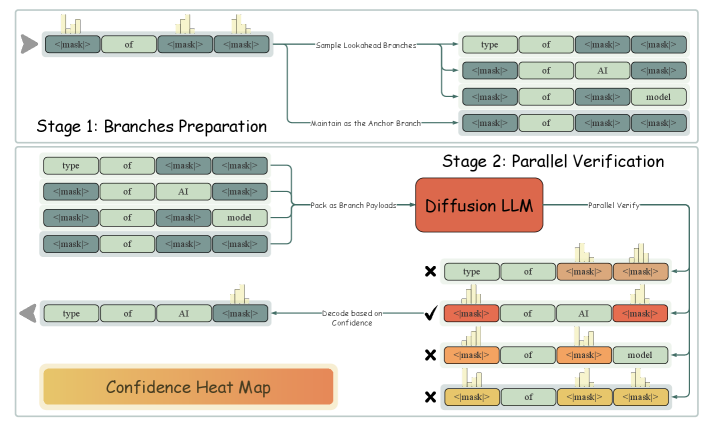
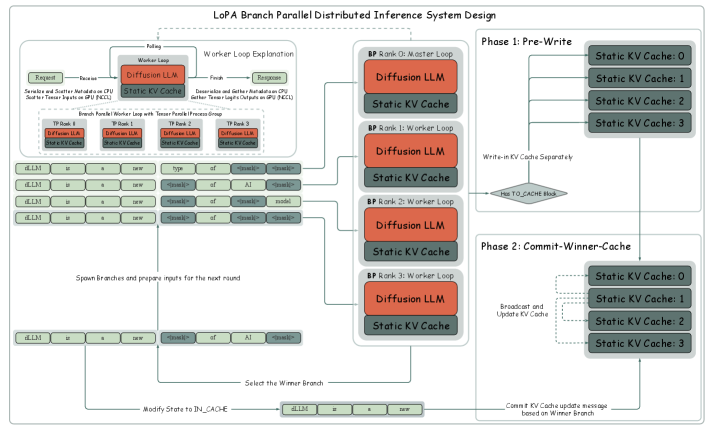
技术框架:LoPA算法主要包含以下几个阶段:1) 分支并行探索:同时探索多个候选的Token填充顺序(TFO),每个TFO对应一个并行分支。2) 置信度评估:评估每个分支的置信度,用于衡量该分支未来并行解码的潜力。3) 最优分支选择:根据置信度选择最有希望的分支,并继续在该分支上进行解码。4) 多设备推理系统:为了支持高并行度,开发了具有分支并行性(BP)的多设备推理系统,充分利用多GPU资源。
关键创新:LoPA的关键创新在于它是一种无需训练、即插即用的算法,能够有效地识别更优的Token填充顺序(TFO),从而显著提高dLLM推理的并行度。与现有方法相比,LoPA不依赖于特定的模型结构或训练数据,具有更强的通用性和易用性。
关键设计:LoPA的关键设计包括:1) 并行分支数量:需要根据计算资源和性能需求进行调整。2) 置信度评估方法:可以使用模型输出的概率或其他指标来评估分支的置信度。3) 分支选择策略:可以选择置信度最高的分支,也可以采用其他策略,如加权平均等。4) 分支并行性(BP):多设备推理系统中的关键技术,用于在多个GPU上并行执行不同的分支。
🖼️ 关键图片
📊 实验亮点
LoPA在D2F-Dream模型上取得了显著的性能提升。在GSM8K数据集上,LoPA将TPF(每前向传播的token数)提高到10.1,同时保持了优于Dream基线的性能。此外,通过开发具有分支并行性(BP)的多设备推理系统,LoPA在多GPU部署下实现了每秒1073.9个token的单样本吞吐量,展示了其强大的并行解码能力。
🎯 应用场景
LoPA算法可应用于各种需要高速推理的扩散大语言模型场景,例如:实时对话系统、快速文本生成、AI辅助创作等。通过提高推理速度,LoPA能够降低计算成本,提升用户体验,并推动dLLM在更多实际应用中的落地。未来,LoPA还可以与其他优化技术相结合,进一步提升dLLM的推理效率。
📄 摘要(原文)
Diffusion Large Language Models (dLLMs) have demonstrated significant potential for high-speed inference. However, current confidence-driven decoding strategies are constrained by limited parallelism, typically achieving only 1--3 tokens per forward pass (TPF). In this work, we identify that the degree of parallelism during dLLM inference is highly sensitive to the Token Filling Order (TFO). Then, we introduce Lookahead PArallel Decoding LoPA, a training-free, plug-and-play algorithm, to identify a superior TFO and hence accelerate inference. LoPA concurrently explores distinct candidate TFOs via parallel branches, and selects the one with the highest potential for future parallelism based on branch confidence. We apply LoPA to the state-of-the-art D2F model and observe a substantial enhancement in decoding efficiency. Notably, LoPA increases the TPF of D2F-Dream to 10.1 on the GSM8K while maintaining performance superior to the Dream baseline. Furthermore, to facilitate this unprecedented degree of parallelism, we develop a specialized multi-device inference system featuring Branch Parallelism (BP), which achieves a single-sample throughput of 1073.9 tokens per second under multi-GPU deployment. The code is available at https://github.com/zhijie-group/LoPA.