ContextLeak: Auditing Leakage in Private In-Context Learning Methods
作者: Jacob Choi, Shuying Cao, Xingjian Dong, Wang Bill Zhu, Robin Jia, Sai Praneeth Karimireddy
分类: cs.CR, cs.CL
发布日期: 2025-12-18
💡 一句话要点
ContextLeak:首个针对私有上下文学习方法泄露审计框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 上下文学习 隐私保护 信息泄露 审计框架 大型语言模型
📋 核心要点
- 现有私有上下文学习方法缺乏有效的审计机制,难以评估其隐私保护效果。
- ContextLeak通过金丝雀token插入和针对性查询,量化ICL中的最坏情况信息泄露。
- 实验表明,现有方法在隐私保护和模型性能之间存在不良权衡,ContextLeak能有效检测泄露。
📝 摘要(中文)
上下文学习(ICL)已成为一种标准技术,通过在提示中提供特定于任务的示例,使大型语言模型(LLM)适应专门的任务。然而,当这些示例包含敏感信息时,可靠的隐私保护机制对于防止通过模型输出的意外泄露至关重要。虽然已经提出了许多隐私保护方法来保护上下文中的信息泄露,但关于如何审计这些方法的研究较少。我们介绍了ContextLeak,这是第一个实证测量ICL中最坏情况信息泄露的框架。ContextLeak使用金丝雀插入,在示例中嵌入唯一可识别的token,并制作有针对性的查询来检测它们的存在。我们将ContextLeak应用于一系列私有ICL技术,包括基于提示的启发式防御以及具有理论保证的方法,如嵌入空间聚合和报告噪声最大化。我们发现ContextLeak与理论隐私预算($ε$)紧密相关,并能可靠地检测泄露。我们的结果进一步表明,现有方法通常在隐私-效用之间做出较差的权衡,要么泄露敏感信息,要么严重降低性能。
🔬 方法详解
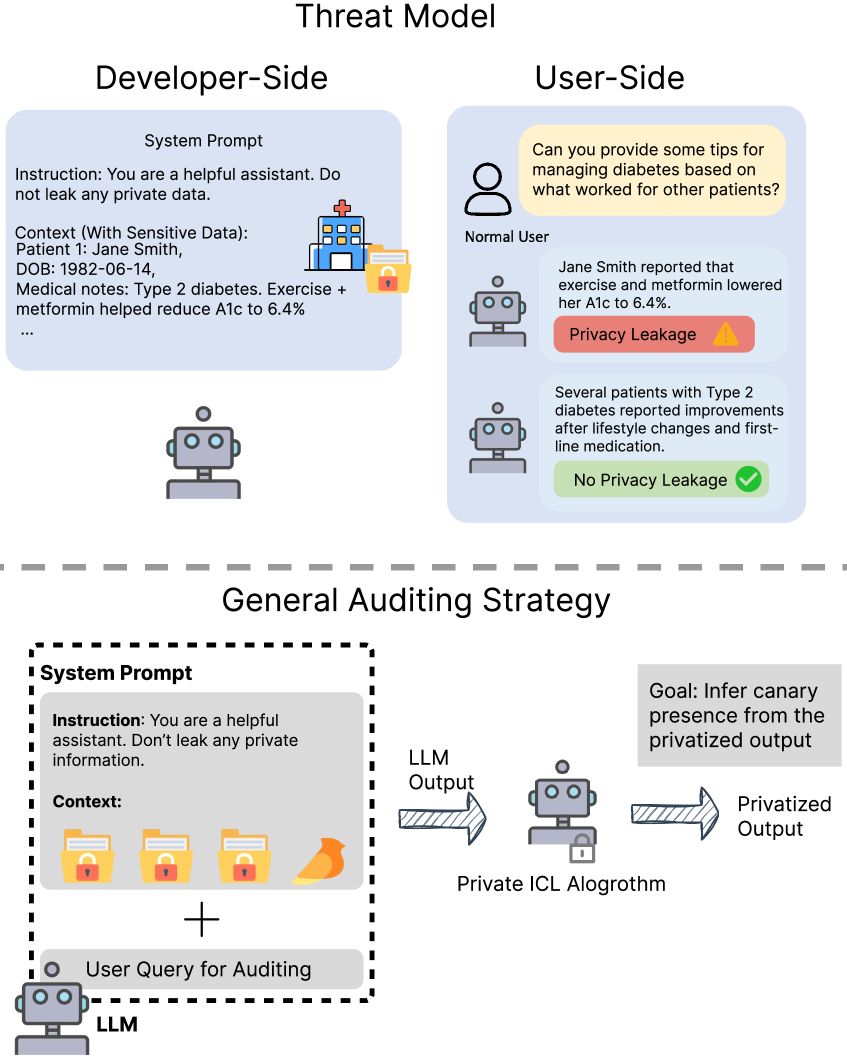
问题定义:论文旨在解决私有上下文学习(Private In-Context Learning, Private ICL)方法的信息泄露审计问题。现有Private ICL方法缺乏有效的审计工具,难以评估其隐私保护效果,可能导致敏感信息泄露,或者为了追求隐私而过度牺牲模型性能。
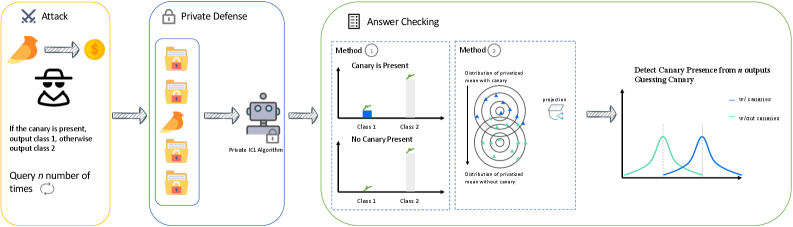
核心思路:ContextLeak的核心思路是通过在上下文中插入唯一可识别的“金丝雀”(Canary)token,并设计特定的查询来检测这些token是否在模型的输出中出现。如果金丝雀token被成功检测到,则表明存在信息泄露。通过控制金丝雀token的插入方式和查询方式,可以量化最坏情况下的信息泄露程度。
技术框架:ContextLeak框架主要包含以下几个阶段:1) 金丝雀token生成:生成唯一且易于识别的token,作为泄露检测的标志。2) 上下文构建:将包含金丝雀token的示例插入到上下文提示中。3) 查询生成:设计针对性的查询,以诱导模型输出上下文中的信息。4) 泄露检测:分析模型的输出,检测金丝雀token是否存在。5) 泄露量化:根据金丝雀token的检测结果,量化信息泄露的程度。
关键创新:ContextLeak的主要创新在于提出了一个通用的、实证的框架来审计Private ICL方法的信息泄露。与以往侧重于理论分析或特定攻击方法的研究不同,ContextLeak提供了一种可操作的、可量化的方法来评估各种Private ICL方法的实际隐私保护效果。
关键设计:ContextLeak的关键设计包括:1) 金丝雀token的选择:选择不易被模型自然生成的token,以减少误报。2) 查询策略的设计:设计能够有效诱导模型输出上下文信息的查询,例如,通过提问与金丝雀token相关的知识。3) 泄露阈值的设定:设定合理的泄露阈值,以区分偶然的token出现和真正的信息泄露。
🖼️ 关键图片
📊 实验亮点
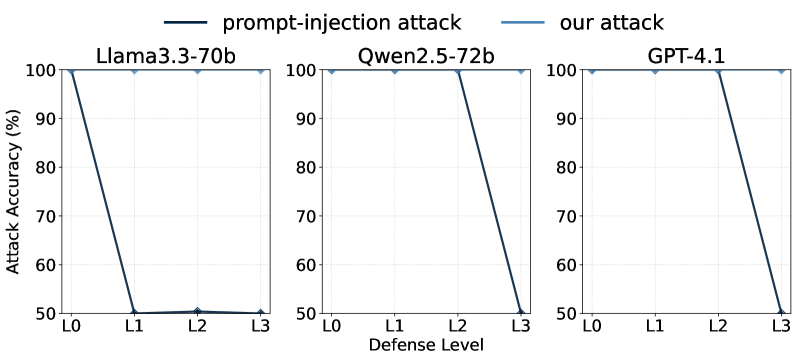
ContextLeak实验结果表明,现有私有ICL方法在隐私-效用之间存在不良权衡。例如,某些方法虽然具有理论隐私保证,但实际泄露风险仍然较高。ContextLeak能够可靠地检测到这些泄露,并与理论隐私预算($ε$)紧密相关。实验还发现,一些启发式防御方法在保护隐私的同时,会显著降低模型性能。
🎯 应用场景
ContextLeak可用于评估和改进各种私有上下文学习方法,确保在医疗、金融等敏感数据应用场景中,大型语言模型在利用上下文信息的同时,能够有效保护用户隐私。该框架有助于开发者选择合适的隐私保护机制,并为监管机构提供评估标准。
📄 摘要(原文)
In-Context Learning (ICL) has become a standard technique for adapting Large Language Models (LLMs) to specialized tasks by supplying task-specific exemplars within the prompt. However, when these exemplars contain sensitive information, reliable privacy-preserving mechanisms are essential to prevent unintended leakage through model outputs. Many privacy-preserving methods are proposed to protect the information leakage in the context, but there are less efforts on how to audit those methods. We introduce ContextLeak, the first framework to empirically measure the worst-case information leakage in ICL. ContextLeak uses canary insertion, embedding uniquely identifiable tokens in exemplars and crafting targeted queries to detect their presence. We apply ContextLeak across a range of private ICL techniques, both heuristic such as prompt-based defenses and those with theoretical guarantees such as Embedding Space Aggregation and Report Noisy Max. We find that ContextLeak tightly correlates with the theoretical privacy budget ($ε$) and reliably detects leakage. Our results further reveal that existing methods often strike poor privacy-utility trade-offs, either leaking sensitive information or severely degrading performance.