Evaluating Large Language Models on Multimodal Chemistry Olympiad Exams
作者: Yiming Cui, Xin Yao, Yuxuan Qin, Xin Li, Shijin Wang, Guoping Hu
分类: cs.CL, cs.AI, cs.CV
发布日期: 2025-12-17
备注: Published at Communications Chemistry
期刊: Commun. Chem. 8 (2025)
DOI: 10.1038/s42004-025-01782-x
💡 一句话要点
评估大型语言模型在多模态化学奥林匹克竞赛题上的表现
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 大型语言模型 化学推理 视觉-语言融合 奥林匹克竞赛题
📋 核心要点
- 现有大型语言模型在处理化学等领域的多模态科学推理问题时面临挑战,无法有效融合视觉和文本信息。
- 论文通过构建化学奥林匹克竞赛题基准,系统评估了40个多模态LLM在视觉和文本推理方面的能力。
- 实验表明,模型在模态融合方面存在不足,思维链提示能有效提升准确性和视觉基础,为改进模型提供了方向。
📝 摘要(中文)
多模态科学推理对大型语言模型(LLMs)来说仍然是一个重大挑战,尤其是在化学领域,问题解决依赖于符号图、分子结构和结构化的视觉数据。本文系统地评估了40个专有和开源的多模态LLM,包括GPT-5、o3、Gemini-2.5-Pro和Qwen2.5-VL,使用一个精心策划的基准,该基准包含来自过去二十多年美国国家化学奥林匹克(USNCO)考试的奥林匹克风格化学问题。这些问题需要在不同的模态之间进行综合的视觉和文本推理。研究发现,许多模型在模态融合方面存在困难,在某些情况下,移除图像甚至可以提高准确性,这表明视觉-语言集成存在不一致。思维链提示始终可以提高准确性和视觉基础,这通过消融研究和基于遮挡的可解释性得到证明。研究结果揭示了当前MLLM在科学推理能力方面的关键局限性,为开发更强大和可解释的化学多模态系统提供了可操作的策略。这项工作为衡量特定领域多模态AI的进展提供了一个及时的基准,并强调了在人工智能和科学推理交叉领域进一步发展的必要性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在处理多模态化学问题时,无法有效融合图像(如分子结构、图表)和文本信息进行推理的难题。现有方法在视觉-语言集成方面存在不足,导致模型在处理需要综合视觉和文本信息的化学问题时表现不佳。
核心思路:论文的核心思路是通过构建一个高质量的化学奥林匹克竞赛题基准,系统地评估现有大型语言模型在多模态化学推理方面的能力。通过分析模型的表现,揭示其在模态融合、视觉基础等方面的不足,并探索改进策略。
技术框架:论文主要包含以下几个阶段:1) 构建化学奥林匹克竞赛题基准,该基准包含需要综合视觉和文本信息进行推理的化学问题;2) 选择并评估40个大型语言模型,包括专有模型和开源模型;3) 分析模型的表现,包括准确率、视觉基础等指标;4) 通过消融研究和可解释性分析,探索模型在模态融合方面的不足,并提出改进策略,例如使用思维链提示。
关键创新:论文的关键创新在于:1) 构建了一个高质量的化学奥林匹克竞赛题基准,为评估多模态LLM在化学领域的推理能力提供了标准;2) 系统地评估了大量LLM,揭示了现有模型在模态融合方面的普遍不足;3) 探索了思维链提示等方法在提高模型性能方面的有效性。
关键设计:论文的关键设计包括:1) 基准题目的选择,确保题目既具有挑战性,又能够反映化学推理的本质;2) 评估指标的选择,包括准确率和视觉基础等,能够全面反映模型的性能;3) 消融研究的设计,能够有效分析不同因素对模型性能的影响;4) 使用遮挡技术进行可解释性分析,能够揭示模型在进行视觉推理时所关注的区域。
🖼️ 关键图片
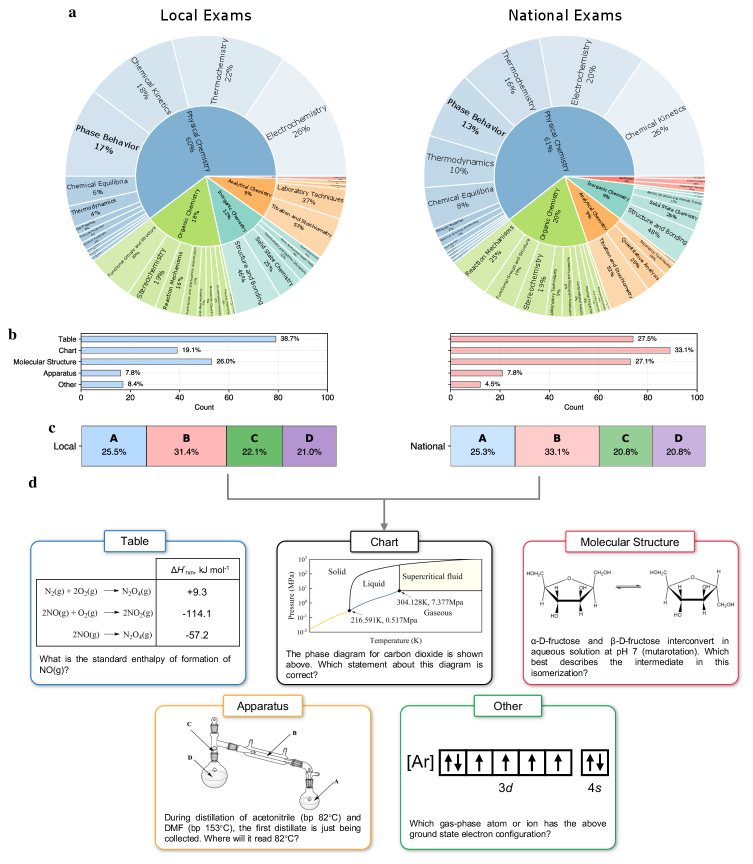
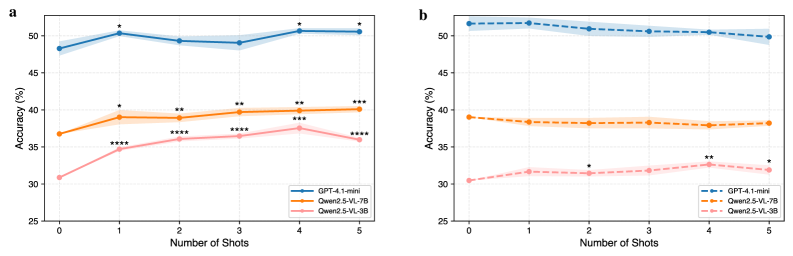

📊 实验亮点
实验结果表明,现有大型语言模型在多模态化学推理方面存在显著局限性,在某些情况下,移除图像甚至能提高准确率。思维链提示能够显著提升模型的准确率和视觉基础能力。例如,在某些模型上,使用思维链提示后,准确率提升了10%以上,表明该方法在提升模型多模态推理能力方面具有潜力。
🎯 应用场景
该研究成果可应用于开发更智能的化学教育工具,辅助化学研究人员进行文献分析和实验设计,以及构建能够理解和生成化学相关多模态内容的人工智能系统。未来,该研究有望推动人工智能在化学及其他科学领域的应用,加速科学发现和技术创新。
📄 摘要(原文)
Multimodal scientific reasoning remains a significant challenge for large language models (LLMs), particularly in chemistry, where problem-solving relies on symbolic diagrams, molecular structures, and structured visual data. Here, we systematically evaluate 40 proprietary and open-source multimodal LLMs, including GPT-5, o3, Gemini-2.5-Pro, and Qwen2.5-VL, on a curated benchmark of Olympiad-style chemistry questions drawn from over two decades of U.S. National Chemistry Olympiad (USNCO) exams. These questions require integrated visual and textual reasoning across diverse modalities. We find that many models struggle with modality fusion, where in some cases, removing the image even improves accuracy, indicating misalignment in vision-language integration. Chain-of-Thought prompting consistently enhances both accuracy and visual grounding, as demonstrated through ablation studies and occlusion-based interpretability. Our results reveal critical limitations in the scientific reasoning abilities of current MLLMs, providing actionable strategies for developing more robust and interpretable multimodal systems in chemistry. This work provides a timely benchmark for measuring progress in domain-specific multimodal AI and underscores the need for further advances at the intersection of artificial intelligence and scientific reasoning.