Roles of MLLMs in Visually Rich Document Retrieval for RAG: A Survey
作者: Xiantao Zhang
分类: cs.IR, cs.CL
发布日期: 2025-12-16
备注: 18 pages; accepted at AACL-IJCNLP 2025 (main conference)
💡 一句话要点
综述MLLM在富视觉文档RAG检索中的应用,分析三种角色及其优劣势。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 富视觉文档检索 多模态大型语言模型 检索增强生成 跨模态检索 文档理解
📋 核心要点
- 现有RAG系统在处理富视觉文档时,面临布局复杂、OCR易错、信息分散等挑战。
- 论文综述了MLLM在VRD检索中的三种角色,分别是模态统一、多模态嵌入和端到端表示。
- 论文对比了不同角色在检索性能、效率和兼容性上的差异,并提出了未来研究方向。
📝 摘要(中文)
富视觉文档(VRD)因其布局相关的语义、脆弱的OCR以及分散在复杂图表中的证据,对检索增强生成(RAG)提出了挑战。本综述探讨了多模态大型语言模型(MLLM)如何被用于使VRD检索在RAG中变得可行。我们将文献组织成三个角色:模态统一的字幕生成器、多模态嵌入器和端到端表示器。我们比较了这些角色在检索粒度、信息保真度、延迟和索引大小、以及与重排序和 grounding 的兼容性方面的表现。我们还概述了关键的权衡,并提供了一些关于何时选择每个角色的实用指导。最后,我们确定了未来研究的有希望的方向,包括自适应检索单元、模型尺寸缩减和评估方法的发展。
🔬 方法详解
问题定义:论文旨在解决富视觉文档(VRD)的检索问题,该问题是检索增强生成(RAG)系统中的一个关键瓶颈。现有方法在处理VRD时,面临着布局复杂、OCR结果不稳定以及关键信息分散在图表中的挑战,导致检索效果不佳。
核心思路:论文的核心思路是将多模态大型语言模型(MLLM)应用于VRD检索,并分析MLLM在其中扮演的不同角色。通过对这些角色的优缺点进行比较,为实际应用提供指导,并为未来的研究方向提供思路。
技术框架:论文将MLLM在VRD检索中的应用分为三个主要角色: 1. 模态统一的字幕生成器:将视觉信息转换为文本描述,从而可以使用传统的文本检索方法。 2. 多模态嵌入器:将文本和图像信息嵌入到同一个向量空间中,从而可以进行跨模态检索。 3. 端到端表示器:直接学习VRD的表示,从而可以进行端到端的检索。 论文对这三种角色在检索粒度、信息保真度、延迟、索引大小以及与重排序和 grounding 的兼容性等方面进行了比较。
关键创新:论文的主要创新在于对MLLM在VRD检索中的角色进行了系统性的分类和分析,并提出了不同角色之间的权衡。这为研究人员和工程师在实际应用中选择合适的MLLM提供了指导。
关键设计:论文没有提出新的模型或算法,而是对现有方法进行了综述和分析。关键的设计在于对不同角色的评估指标的选择,例如检索粒度、信息保真度、延迟和索引大小等。这些指标可以帮助用户根据实际需求选择合适的MLLM。
🖼️ 关键图片

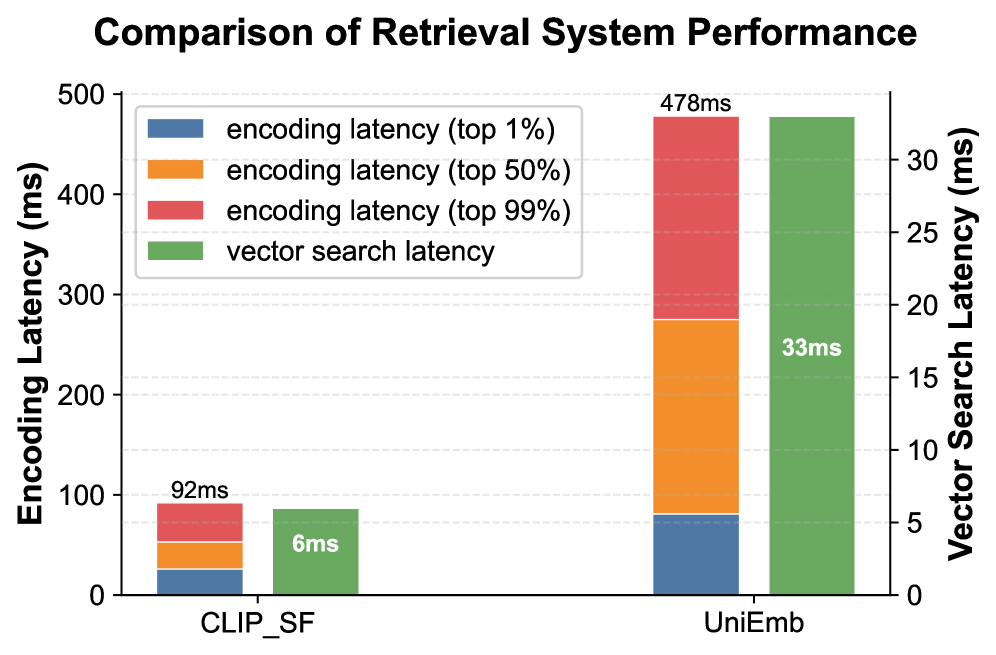
📊 实验亮点
该综述论文系统地分析了MLLM在VRD检索中的三种角色,并对比了它们在检索粒度、信息保真度、延迟和索引大小等方面的表现。通过对这些角色的优缺点进行比较,为实际应用提供了有价值的指导,并为未来的研究方向提供了思路。
🎯 应用场景
该研究成果可应用于各种需要处理富视觉文档的场景,例如金融报告分析、法律文档检索、科学论文理解等。通过提升VRD检索的准确性和效率,可以显著提高RAG系统的性能,并为用户提供更准确、更全面的信息。
📄 摘要(原文)
Visually rich documents (VRDs) challenge retrieval-augmented generation (RAG) with layout-dependent semantics, brittle OCR, and evidence spread across complex figures and structured tables. This survey examines how Multimodal Large Language Models (MLLMs) are being used to make VRD retrieval practical for RAG. We organize the literature into three roles: Modality-Unifying Captioners, Multimodal Embedders, and End-to-End Representers. We compare these roles along retrieval granularity, information fidelity, latency and index size, and compatibility with reranking and grounding. We also outline key trade-offs and offer some practical guidance on when to favor each role. Finally, we identify promising directions for future research, including adaptive retrieval units, model size reduction, and the development of evaluation methods.