Parameter Efficient Multimodal Instruction Tuning for Romanian Vision Language Models
作者: George-Andrei Dima, Dumitru-Clementin Cercel
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-12-16
💡 一句话要点
提出针对罗马尼亚语视觉语言模型的参数高效多模态指令微调方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 多模态学习 指令微调 参数高效微调 低资源语言 罗马尼亚语 视觉问答
📋 核心要点
- 现有视觉语言模型在低资源语言(如罗马尼亚语)上的表现不足,缺乏高质量的训练数据是主要瓶颈。
- 论文提出了一种参数高效的多模态指令微调方法,并构建了罗马尼亚语的视觉问答数据集,以提升模型性能。
- 实验结果表明,微调后的模型在罗马尼亚语视觉问答和图像描述生成任务上均取得了显著提升,语法错误也明显减少。
📝 摘要(中文)
本文致力于缩小低资源语言在生成式AI领域的差距,专注于罗马尼亚语的多模态NLP资源。我们首先将广泛使用的Flickr30k数据集翻译成罗马尼亚语,并利用开源LLM进一步扩展它,用于视觉问答任务。我们通过在罗马尼亚语视觉问答任务上微调开源VLM来证明我们数据集的有效性。我们选择了来自三个广泛使用的模型系列的VLM:LLaMA 3.2、LLaVA 1.6和Qwen2。对于微调,我们采用了参数高效的LoRA方法。我们的模型在视觉问答以及未训练的任务(如罗马尼亚语图像描述生成)中都表现出改进的罗马尼亚语能力。拥有70亿参数的Qwen2-VL-RoVQA在两项任务中均获得最高分,BERTScore F1分别比其原始版本提高了+6.05%和+2.61%。最后,与原始形式相比,这些模型在语法错误方面有了显着减少,表明不仅在语言理解方面有所改进,而且在罗马尼亚语的流畅性方面也有所提高。
🔬 方法详解
问题定义:论文旨在解决罗马尼亚语视觉语言模型(VLM)在视觉问答(VQA)和图像描述生成等任务中性能不足的问题。现有方法在低资源语言上缺乏足够的高质量训练数据,导致模型效果不佳。此外,直接对大型VLM进行全参数微调成本高昂,不适用于资源有限的场景。
核心思路:论文的核心思路是利用参数高效的微调方法(LoRA)在已有的开源VLM基础上,通过在自建的罗马尼亚语VQA数据集上进行指令微调,提升模型在罗马尼亚语环境下的视觉理解和语言生成能力。通过LoRA,只训练少量参数,降低了计算成本和存储需求。
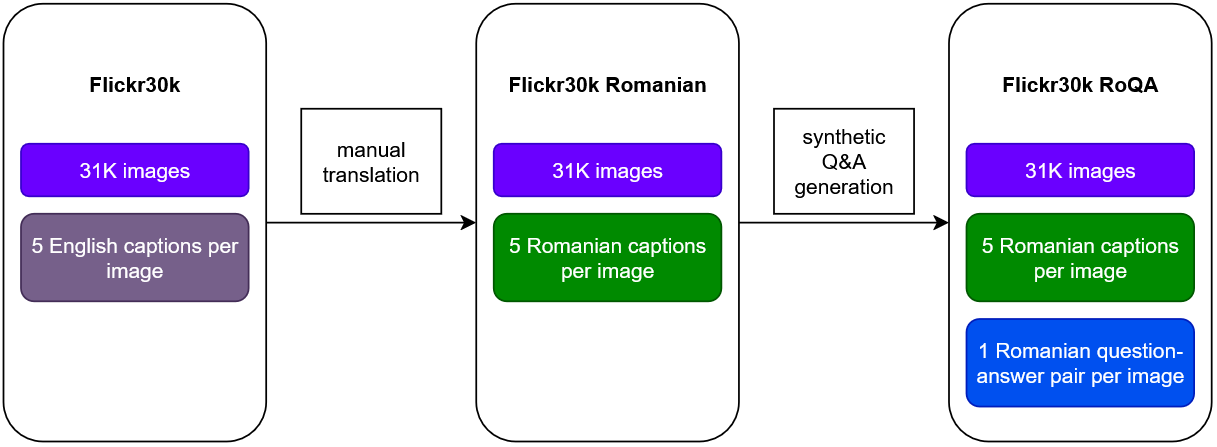
技术框架:整体框架包括以下几个阶段:1) 数据集构建:将Flickr30k数据集翻译成罗马尼亚语,并利用开源LLM扩展为VQA数据集。2) 模型选择:选择LLaMA 3.2、LLaVA 1.6和Qwen2等开源VLM作为基础模型。3) 参数高效微调:采用LoRA方法对选定的VLM进行微调,使其适应罗马尼亚语VQA任务。4) 评估:在罗马尼亚语VQA和图像描述生成任务上评估微调后的模型性能。
关键创新:论文的关键创新在于:1) 构建了高质量的罗马尼亚语VQA数据集,填补了低资源语言数据空白。2) 采用参数高效的LoRA方法,降低了微调大型VLM的计算成本。3) 验证了指令微调在提升低资源语言VLM性能方面的有效性。
关键设计:在数据集构建方面,使用了高质量的机器翻译和人工校对,确保数据的准确性和流畅性。在模型微调方面,使用了LoRA方法,具体参数设置(如LoRA rank)未知。损失函数和网络结构沿用了基础VLM的设置,未做显著修改。具体训练超参数未知。
🖼️ 关键图片

📊 实验亮点
实验结果表明,使用LoRA微调后的Qwen2-VL-RoVQA模型在罗马尼亚语视觉问答和图像描述生成任务上均取得了显著提升,BERTScore F1分别提高了+6.05%和+2.61%。此外,模型在语法错误方面也有明显减少,表明其罗马尼亚语理解和生成能力得到了有效提升。
🎯 应用场景
该研究成果可应用于多种场景,例如:智能客服、图像搜索、辅助教育等。通过提升罗马尼亚语视觉语言模型的性能,可以为当地用户提供更智能、更便捷的服务。未来,该方法可以推广到其他低资源语言,促进AI技术的普及和应用。
📄 摘要(原文)
Focusing on low-resource languages is an essential step toward democratizing generative AI. In this work, we contribute to reducing the multimodal NLP resource gap for Romanian. We translate the widely known Flickr30k dataset into Romanian and further extend it for visual question answering by leveraging open-source LLMs. We demonstrate the usefulness of our datasets by fine-tuning open-source VLMs on Romanian visual question answering. We select VLMs from three widely used model families: LLaMA 3.2, LLaVA 1.6, and Qwen2. For fine-tuning, we employ the parameter-efficient LoRA method. Our models show improved Romanian capabilities in visual QA, as well as on tasks they were not trained on, such as Romanian image description generation. The seven-billion-parameter Qwen2-VL-RoVQA obtains top scores on both tasks, with improvements of +6.05% and +2.61% in BERTScore F1 over its original version. Finally, the models show substantial reductions in grammatical errors compared to their original forms, indicating improvements not only in language understanding but also in Romanian fluency.