Multiscale Aggregated Hierarchical Attention (MAHA): A Game Theoretic and Optimization Driven Approach to Efficient Contextual Modeling in Large Language Models
作者: Caner Erden
分类: cs.CL
发布日期: 2025-12-16 (更新: 2025-12-18)
💡 一句话要点
提出多尺度聚合分层注意力(MAHA),高效建模长文本上下文,降低LLM计算复杂度。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本建模 注意力机制 分层注意力 计算复杂度 大型语言模型 凸优化 博弈论 可扩展性
📋 核心要点
- 传统注意力机制在处理长文本时计算复杂度高,难以捕捉多尺度语义信息。
- MAHA通过分层分解和优化聚合,动态划分输入序列,平衡局部细节和全局上下文。
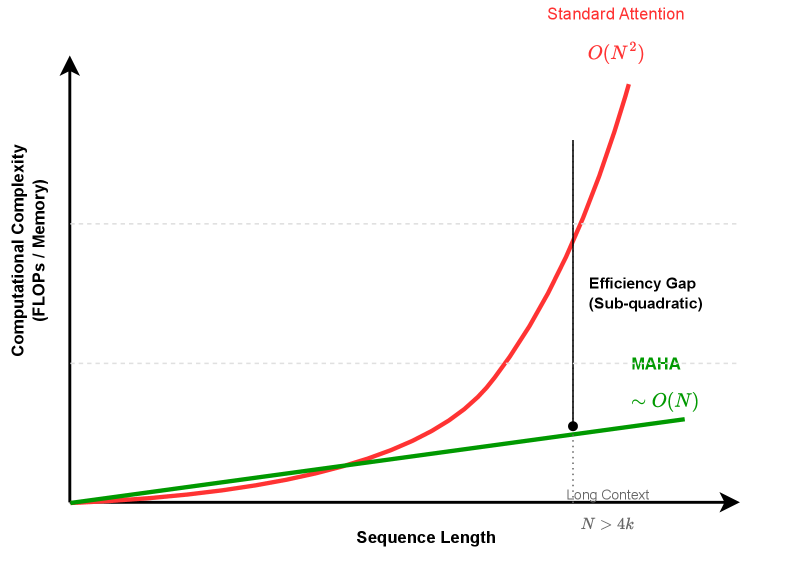
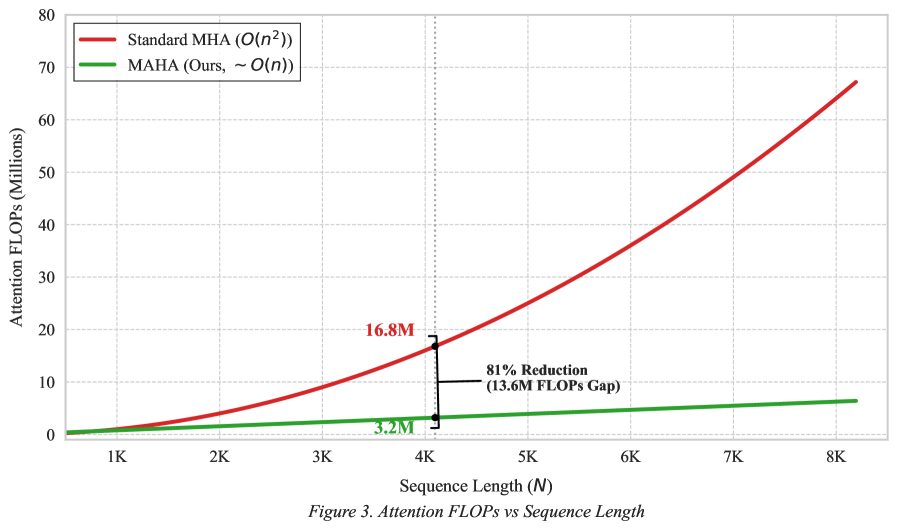
- 实验表明,MAHA在长序列上显著降低计算成本,序列长度4096时FLOPs降低81%。
📝 摘要(中文)
多头自注意力(MHSA)的二次计算复杂度仍然是扩展大型语言模型(LLM)以处理长上下文任务的根本瓶颈。虽然稀疏和线性化注意力机制试图缓解这个问题,但它们通常会损害全局依赖关系的表示,或者无法有效地捕获多尺度语义粒度。本文提出了一种新颖的架构框架——多尺度聚合分层注意力(MAHA),它通过分层分解和数学上严格的聚合来重新构建注意力机制。与在单一分辨率下处理token交互的传统方法不同,MAHA通过可学习的下采样算子将输入序列动态地划分为分层尺度。其核心创新在于其聚合策略:我们将尺度特定的注意力矩阵的融合建模为一个资源分配问题,通过凸优化框架或基于纳什均衡的博弈论方法来解决。这确保了局部细微差别和全局上下文保真度之间在理论上的最佳平衡。MAHA在混合扩张卷积Transformer骨干网络中实现,利用可微优化层来实现端到端训练。实验评估表明,MAHA实现了卓越的可扩展性;经验FLOPs分析证实,在序列长度为4096时,与标准注意力相比,计算成本降低了81%。这项工作弥合了优化理论和序列建模之间的差距,为下一代LLM提供了一个可扩展的解决方案。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在处理长文本时,由于多头自注意力(MHSA)的二次计算复杂度而导致的计算瓶颈问题。现有的稀疏注意力或线性化注意力方法虽然降低了计算复杂度,但往往牺牲了全局依赖关系的建模能力或无法有效捕捉多尺度语义信息。
核心思路:论文的核心思路是将注意力机制进行分层分解,并通过优化方法聚合不同尺度的注意力信息。通过将输入序列划分为不同的尺度,模型可以同时关注局部细节和全局上下文。然后,通过凸优化或博弈论方法,将不同尺度的注意力矩阵进行融合,从而在计算效率和表示能力之间取得平衡。
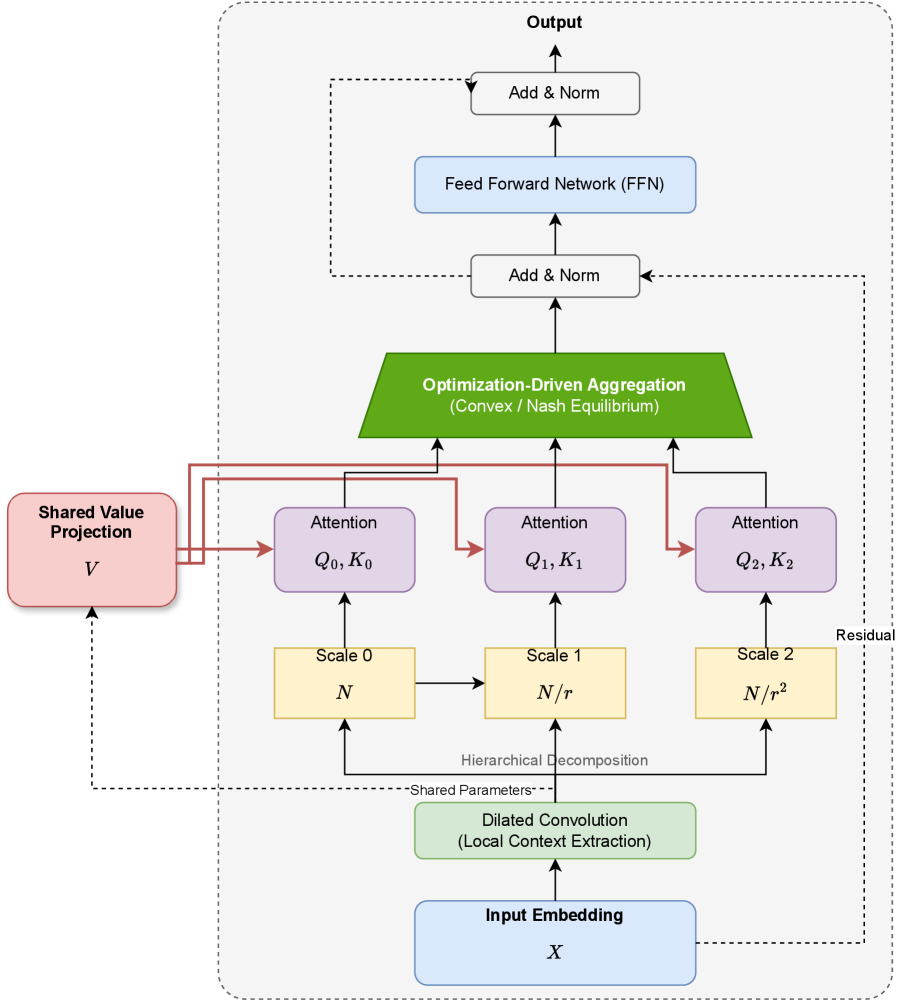
技术框架:MAHA的整体架构基于混合扩张卷积Transformer骨干网络。首先,通过可学习的下采样算子将输入序列划分为不同的尺度。然后,在每个尺度上计算注意力矩阵。最后,使用可微优化层将不同尺度的注意力矩阵进行聚合。整个框架可以进行端到端训练。
关键创新:MAHA的关键创新在于其聚合策略。论文将不同尺度注意力矩阵的融合建模为一个资源分配问题,并使用凸优化或博弈论方法来解决。这种方法可以确保在局部细节和全局上下文之间实现理论上的最佳平衡。与传统的注意力机制相比,MAHA能够更有效地利用计算资源,并更好地捕捉长文本中的依赖关系。
关键设计:MAHA的关键设计包括:1) 可学习的下采样算子,用于将输入序列划分为不同的尺度;2) 基于凸优化或博弈论的聚合策略,用于融合不同尺度的注意力矩阵;3) 可微优化层,用于实现端到端训练。具体的参数设置和网络结构细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
MAHA在实验中表现出卓越的可扩展性。经验FLOPs分析表明,在序列长度为4096时,MAHA的计算成本比标准注意力降低了81%。这表明MAHA能够显著提高LLM处理长文本的效率,使其能够应用于更大规模的数据集和更复杂的任务。
🎯 应用场景
MAHA具有广泛的应用前景,尤其是在需要处理长文本的领域,如机器翻译、文本摘要、问答系统、对话生成等。通过降低计算复杂度,MAHA可以使LLM能够处理更长的上下文,从而提高模型的性能和泛化能力。此外,MAHA还可以应用于其他序列建模任务,如语音识别、视频理解等。
📄 摘要(原文)
The quadratic computational complexity of MultiHead SelfAttention (MHSA) remains a fundamental bottleneck in scaling Large Language Models (LLMs) for longcontext tasks. While sparse and linearized attention mechanisms attempt to mitigate this, they often compromise the representation of global dependencies or fail to capture multiscale semantic granularity effectively. In this paper, we propose Multiscale Aggregated Hierarchical Attention (MAHA), a novel architectural framework that reformulates the attention mechanism through hierarchical decomposition and mathematically rigorous aggregation. Unlike conventional approaches that treat token interactions at a single resolution, MAHA dynamically partitions the input sequence into hierarchical scales via learnable downsampling operators. The core innovation lies in its aggregation strategy: we model the fusion of scalespecific attention matrices as a resource allocation problem, solved via a convex optimization framework or a Nash equilibriumbased gametheoretic approach. This ensures a theoretically optimal balance between local nuance and global context fidelity. Implemented within a hybrid dilatedconvolutional transformer backbone, MAHA utilizes differentiable optimization layers to enable endtoend training. Experimental evaluations demonstrate that MAHA achieves superior scalability; empirical FLOPs analysis confirms an 81% reduction in computational cost at a sequence length of 4096 compared to standard attention. This work bridges the gap between optimization theory and sequence modeling, offering a scalable solution for nextgeneration LLMs.