Integrating Large Language Models and Knowledge Graphs to Capture Political Viewpoints in News Media
作者: Massimiliano Fadda, Enrico Motta, Francesco Osborne, Diego Reforgiato Recupero, Angelo Salatino
分类: cs.CL, cs.AI, cs.IR
发布日期: 2025-12-16
💡 一句话要点
融合大型语言模型与知识图谱以捕捉新闻媒体中的政治观点
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 知识图谱 政治观点分析 新闻媒体 观点分类
📋 核心要点
- 现有方法难以有效捕捉新闻媒体中复杂的政治观点,缺乏对观点分类的精确性和对相关行动者语义信息的利用。
- 本文提出一种融合大型语言模型和知识图谱的方法,通过微调LLM进行观点分类,并利用Wikidata丰富主张的语义表示。
- 实验结果表明,该方法在英国移民辩论基准上优于其他解决方案,特别是当使用能够处理长输入的LLM时,集成的效果最佳。
📝 摘要(中文)
新闻媒体在民主社会中扮演着重要角色,它们通过特定的主题、观点和声音塑造政治和社会讨论。理解这些动态对于评估媒体环境是否能对公共辩论提供平衡和公正的描述至关重要。本文改进了一个已有的流程,该流程针对新闻语料库,首先使用混合人机方法识别关于给定主题表达的各种观点,然后根据已识别的观点对相关主张进行分类。这些观点被定义为语义和意识形态上一致的主张集合(例如,认为移民对英国经济产生积极影响的立场)。本文通过以下方式改进了该流程:1) 微调大型语言模型(LLM)用于观点分类;2) 使用从Wikidata提取的相关行动者的语义描述来丰富主张的表示。我们在一个以英国移民辩论为中心的基准上评估了我们的方法,结果表明,虽然这两种机制都能独立提高分类性能,但它们的集成产生了最佳结果,尤其是在使用能够处理长输入的LLM时。
🔬 方法详解
问题定义:论文旨在解决新闻媒体中政治观点捕捉的问题。现有方法在观点分类的准确性和对新闻事件中相关行动者的语义理解方面存在不足,难以全面、深入地分析新闻报道中的政治立场。
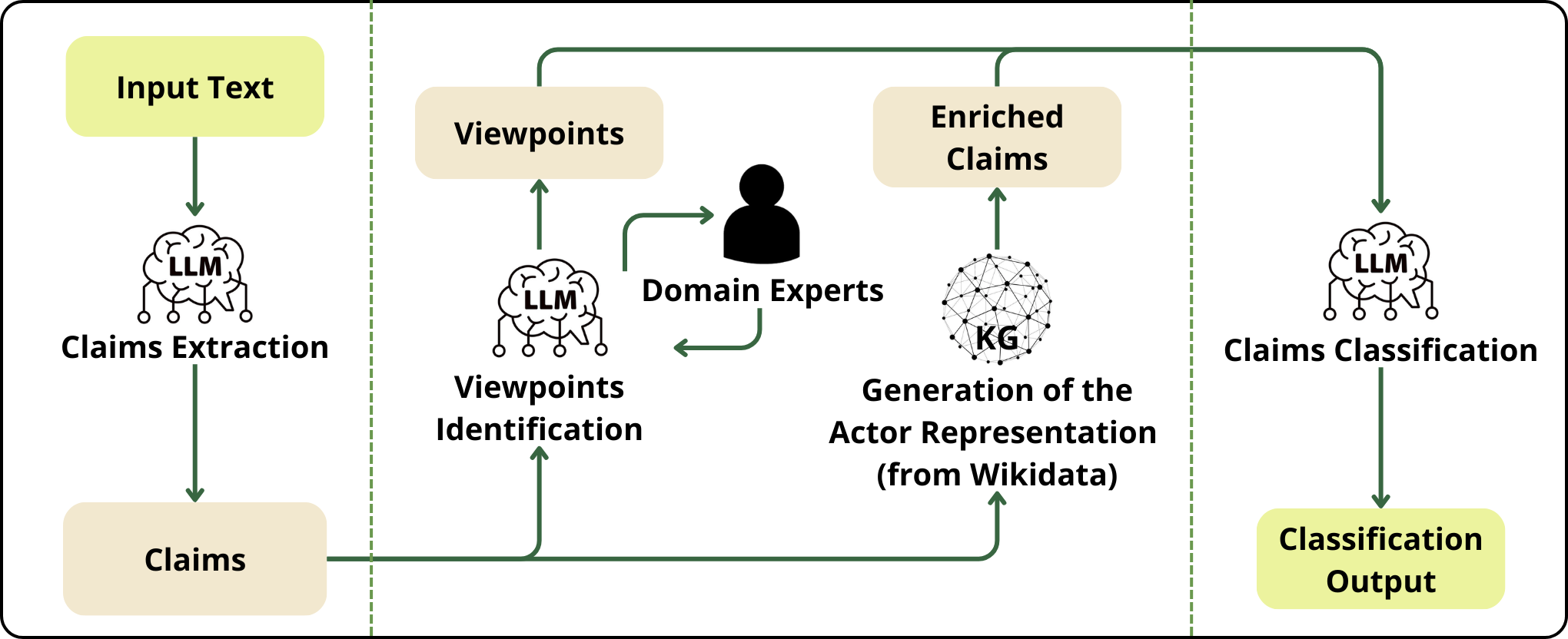
核心思路:论文的核心思路是将大型语言模型(LLM)的强大语义理解能力与知识图谱(特别是Wikidata)提供的丰富实体信息相结合。通过微调LLM进行观点分类,并利用知识图谱增强对新闻报道中关键行动者的理解,从而更准确地捕捉和分析政治观点。
技术框架:该方法包含以下主要模块:1) 数据预处理:收集新闻语料库,并进行清洗和标注。2) 观点识别:使用混合人机方法识别关于特定主题的各种观点。3) LLM微调:针对观点分类任务,微调大型语言模型。4) 知识图谱集成:利用Wikidata获取相关行动者的语义描述,并将其融入到主张的表示中。5) 观点分类:使用微调后的LLM和增强的主张表示进行观点分类。
关键创新:该方法最重要的创新点在于将LLM的上下文理解能力与知识图谱的结构化知识相结合,从而更全面地理解新闻报道中的政治观点。与传统方法相比,该方法能够更准确地识别和分类观点,并更好地理解新闻事件中相关行动者的角色和立场。
关键设计:论文的关键设计包括:1) 选择合适的LLM并进行微调,以适应观点分类任务。2) 设计有效的方法将Wikidata中的实体信息融入到主张的表示中,例如使用实体嵌入或关系嵌入。3) 针对长文本输入,选择能够处理长输入的LLM架构。4) 使用合适的评估指标来衡量观点分类的准确性和鲁棒性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,单独使用微调后的LLM和知识图谱集成都能提高观点分类的性能。然而,将两者结合使用可以获得最佳结果,尤其是在使用能够处理长输入的LLM时。具体而言,该方法在英国移民辩论基准上显著优于其他基线方法,证明了其有效性和优越性。
🎯 应用场景
该研究成果可应用于政治观点分析、舆情监控、新闻内容推荐、虚假信息检测等领域。通过更准确地理解新闻报道中的政治观点,可以帮助人们更好地了解社会动态,促进公共讨论,并提高对虚假信息的辨别能力。未来,该方法可以扩展到其他类型的文本数据,例如社交媒体帖子和在线评论。
📄 摘要(原文)
News sources play a central role in democratic societies by shaping political and social discourse through specific topics, viewpoints and voices. Understanding these dynamics is essential for assessing whether the media landscape offers a balanced and fair account of public debate. In earlier work, we introduced a pipeline that, given a news corpus, i) uses a hybrid human-machine approach to identify the range of viewpoints expressed about a given topic, and ii) classifies relevant claims with respect to the identified viewpoints, defined as sets of semantically and ideologically congruent claims (e.g., positions arguing that immigration positively impacts the UK economy). In this paper, we improve this pipeline by i) fine-tuning Large Language Models (LLMs) for viewpoint classification and ii) enriching claim representations with semantic descriptions of relevant actors drawn from Wikidata. We evaluate our approach against alternative solutions on a benchmark centred on the UK immigration debate. Results show that while both mechanisms independently improve classification performance, their integration yields the best results, particularly when using LLMs capable of processing long inputs.