T5Gemma 2: Seeing, Reading, and Understanding Longer
作者: Biao Zhang, Paul Suganthan, Gaël Liu, Ilya Philippov, Sahil Dua, Ben Hora, Kat Black, Gus Martins, Omar Sanseviero, Shreya Pathak, Cassidy Hardin, Francesco Visin, Jiageng Zhang, Kathleen Kenealy, Qin Yin, Xiaodan Song, Olivier Lacombe, Armand Joulin, Tris Warkentin, Adam Roberts
分类: cs.CL
发布日期: 2025-12-16 (更新: 2025-12-23)
备注: technical report
💡 一句话要点
T5Gemma 2:提出一种轻量级多模态长文本理解的Encoder-Decoder模型。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Encoder-Decoder模型 多模态学习 长文本建模 自适应学习 UL2 轻量级模型 Gemma Transformer
📋 核心要点
- 现有Decoder-only模型在长文本建模和多模态任务中存在效率和性能瓶颈。
- T5Gemma 2通过UL2自适应策略,将Decoder-only模型转化为Encoder-Decoder模型,并扩展到多模态。
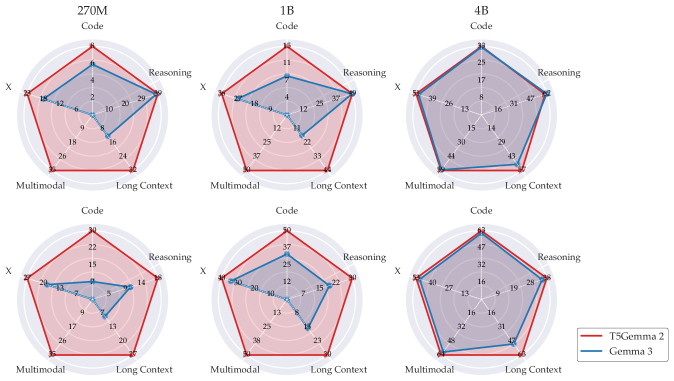
- 实验表明,T5Gemma 2在预训练和后训练性能上均优于Gemma 3,尤其在长文本建模方面。
📝 摘要(中文)
本文介绍了T5Gemma 2,这是下一代T5Gemma系列的轻量级开放Encoder-Decoder模型,具有强大的多语言、多模态和长上下文处理能力。T5Gemma 2沿用了T5Gemma中的自适应方法(通过UL2),将预训练的Decoder-only模型适配为Encoder-Decoder模型,并基于Gemma 3模型将其从纯文本扩展到多模态。此外,我们提出了两种提高效率的方法:共享Encoder和Decoder之间所有嵌入的绑定词嵌入,以及将Decoder自注意力机制和交叉注意力机制统一到单个联合模块中的合并注意力机制。实验表明,该自适应策略在架构和模态上的通用性,以及Encoder-Decoder架构在长上下文建模方面的独特优势。与T5Gemma类似,T5Gemma 2产生了可比或更好的预训练性能,并且比其Gemma 3对应模型显著提高了后训练性能。我们将预训练模型(270M-270M、1B-1B和4B-4B)发布给社区,以供未来研究。
🔬 方法详解
问题定义:现有Decoder-only模型在处理长文本和多模态任务时,由于其固有的单向性,效率较低且难以有效捕捉全局信息。此外,将Decoder-only模型直接应用于多模态任务通常需要复杂的适配和训练策略,效果并不理想。
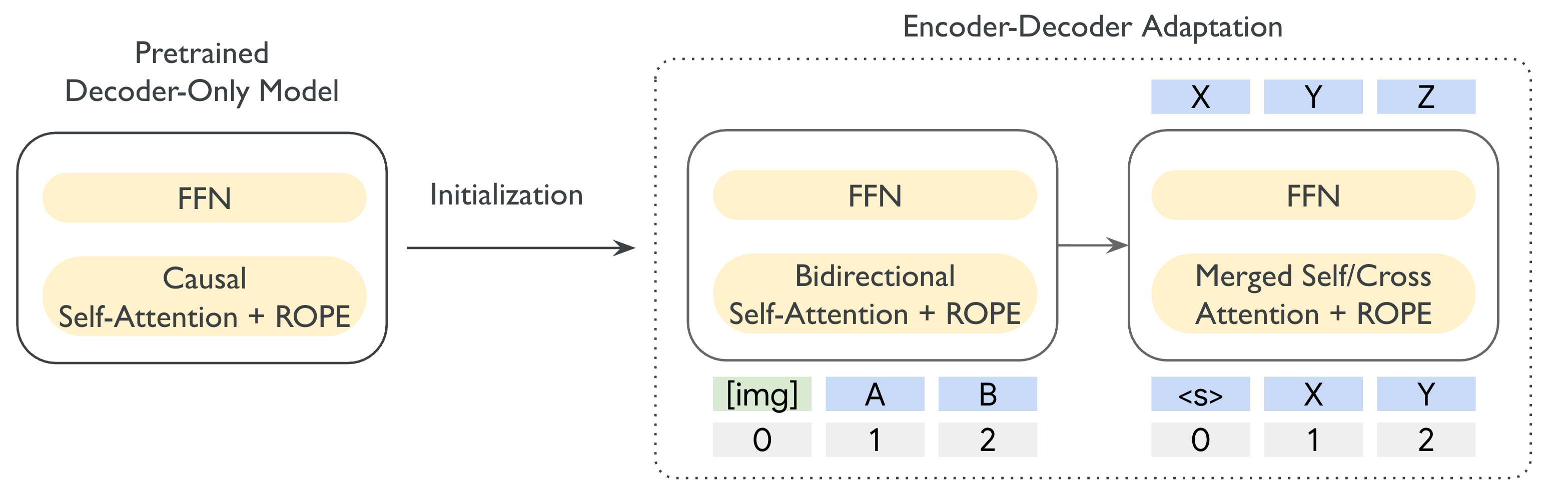
核心思路:本文的核心思路是将预训练的Decoder-only模型(Gemma 3)通过自适应方法(UL2)转化为Encoder-Decoder模型(T5Gemma 2)。Encoder-Decoder架构能够更好地处理长文本,因为Encoder可以压缩输入信息,Decoder可以生成输出。同时,通过共享词嵌入和合并注意力机制来提高模型的效率。
技术框架:T5Gemma 2的整体框架包括以下几个主要步骤:首先,使用UL2自适应策略将Gemma 3模型转化为Encoder-Decoder结构。然后,引入绑定词嵌入,共享Encoder和Decoder之间的所有嵌入。接着,采用合并注意力机制,将Decoder的自注意力和交叉注意力统一到一个模块中。最后,在多语言、多模态数据集上进行预训练和后训练。
关键创新:T5Gemma 2的关键创新在于:1) 将Decoder-only模型自适应为Encoder-Decoder模型,使其更适合长文本和多模态任务;2) 提出绑定词嵌入和合并注意力机制,显著提高了模型的效率,减少了参数量;3) 验证了自适应策略在不同架构和模态上的通用性。与直接训练Encoder-Decoder模型相比,这种自适应方法可以更好地利用预训练模型的知识。
关键设计:T5Gemma 2的关键设计包括:1) 使用UL2作为自适应策略,具体参数设置未知;2) 绑定词嵌入,共享Encoder和Decoder的词嵌入矩阵,减少参数量;3) 合并注意力机制,将Decoder的自注意力和交叉注意力合并为一个模块,减少计算量;4) 模型大小包括270M-270M、1B-1B和4B-4B三种规模,具体层数、头数等网络结构细节未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,T5Gemma 2在预训练性能上与Gemma 3相当或更好,并且在后训练性能上显著优于Gemma 3。具体性能提升数据未知,但论文强调了Encoder-Decoder架构在长上下文建模方面的优势。此外,绑定词嵌入和合并注意力机制有效地提高了模型的效率,减少了参数量。
🎯 应用场景
T5Gemma 2可应用于机器翻译、文本摘要、图像描述、视觉问答等多种任务。其轻量级和高效的特性使其能够在资源受限的环境中部署。该模型有望推动多语言、多模态和长文本理解领域的研究和应用,例如,可以用于开发更智能的对话系统、更准确的搜索引擎和更强大的内容生成工具。
📄 摘要(原文)
We introduce T5Gemma 2, the next generation of the T5Gemma family of lightweight open encoder-decoder models, featuring strong multilingual, multimodal and long-context capabilities. T5Gemma 2 follows the adaptation recipe (via UL2) in T5Gemma -- adapting a pretrained decoder-only model into an encoder-decoder model, and extends it from text-only regime to multimodal based on the Gemma 3 models. We further propose two methods to improve the efficiency: tied word embedding that shares all embeddings across encoder and decoder, and merged attention that unifies decoder self- and cross-attention into a single joint module. Experiments demonstrate the generality of the adaptation strategy over architectures and modalities as well as the unique strength of the encoder-decoder architecture on long context modeling. Similar to T5Gemma, T5Gemma 2 yields comparable or better pretraining performance and significantly improved post-training performance than its Gemma 3 counterpart. We release the pretrained models (270M-270M, 1B-1B and 4B-4B) to the community for future research.