VLegal-Bench: Cognitively Grounded Benchmark for Vietnamese Legal Reasoning of Large Language Models
作者: Nguyen Tien Dong, Minh-Anh Nguyen, Thanh Dat Hoang, Nguyen Tuan Ngoc, Dao Xuan Quang Minh, Phan Phi Hai, Nguyen Thi Ngoc Anh, Dang Van Tu, Binh Vu
分类: cs.CL, cs.AI
发布日期: 2025-12-16 (更新: 2025-12-24)
💡 一句话要点
提出VLegal-Bench,用于评估大型语言模型在越南法律推理任务中的能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 越南法律 大型语言模型 法律推理 评估基准 认知分类学
📋 核心要点
- 现有方法难以评估LLMs在复杂、层级化且频繁修订的越南法律环境中的推理能力。
- VLegal-Bench通过模拟实际法律助理工作流程,从认知角度系统评估LLMs的法律理解能力。
- VLegal-Bench包含10,450个样本,涵盖多种法律任务,为LLMs在越南法律领域的应用提供基准。
📝 摘要(中文)
大型语言模型(LLMs)的快速发展为人工智能在法律领域的应用带来了新的可能性。然而,越南法律的复杂性、层级结构和频繁修订对评估这些模型解释和利用法律知识的能力提出了巨大的挑战。为了解决这一差距,我们推出了越南法律基准(VLegal-Bench),这是第一个旨在系统评估LLMs在越南法律任务上的综合基准。VLegal-Bench以Bloom的认知分类学为基础,通过旨在反映实际使用场景的任务,涵盖了多个层次的法律理解。该基准包含10,450个样本,这些样本通过严格的标注流程生成,法律专家使用我们的标注系统对每个实例进行标注和交叉验证,以确保每个样本都基于权威的法律文件,并反映了真实的法律助理工作流程,包括一般法律问答、检索增强生成、多步骤推理和针对越南法律的基于场景的问题解决。通过提供一个标准化、透明和认知驱动的评估框架,VLegal-Bench为评估LLM在越南法律环境中的性能奠定了坚实的基础,并支持开发更可靠、可解释和符合伦理的AI辅助法律系统。为了方便访问和重现,我们在https://vilegalbench.cmcai.vn/上提供了一个公共主页。
🔬 方法详解
问题定义:论文旨在解决缺乏针对越南法律领域的大型语言模型(LLMs)评估基准的问题。现有方法无法有效评估LLMs在越南法律的复杂性、层级结构和频繁修订下的法律推理能力,阻碍了AI在越南法律领域的应用。
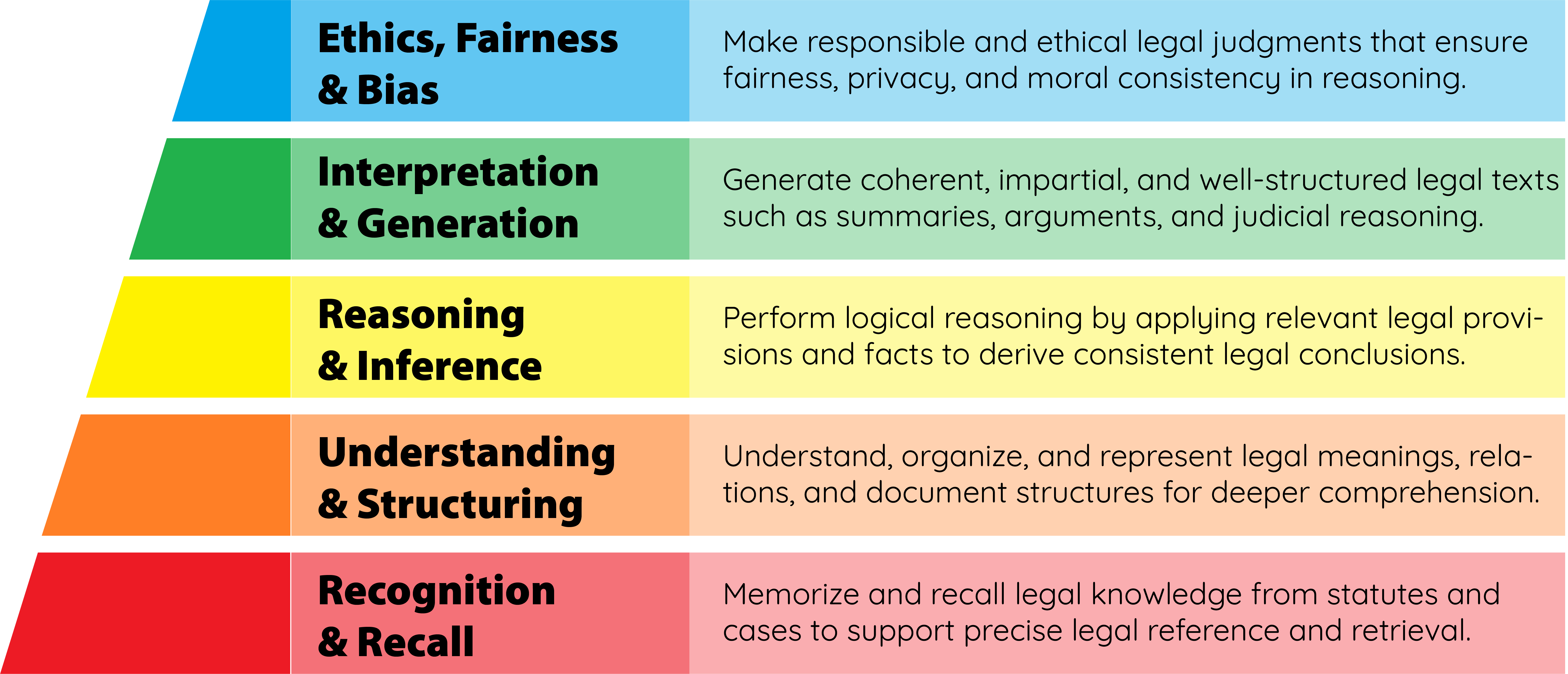
核心思路:论文的核心思路是构建一个全面、标准化且认知驱动的评估基准VLegal-Bench,该基准模拟真实的法律助理工作流程,涵盖多个层次的法律理解,从而系统地评估LLMs在越南法律任务中的表现。基准的设计参考了Bloom的认知分类学,确保评估的全面性和深度。
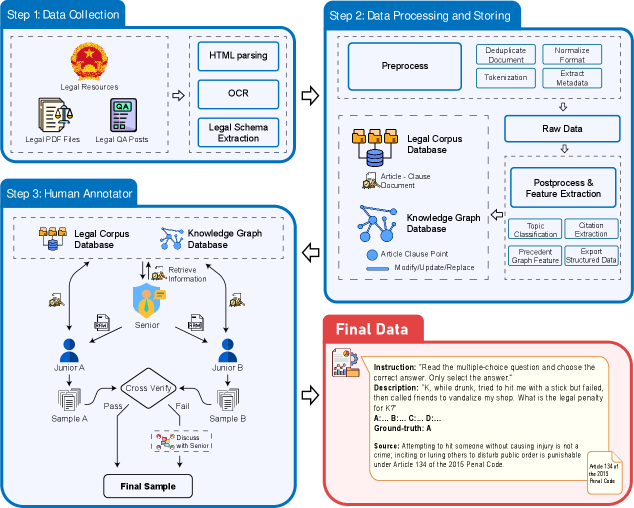
技术框架:VLegal-Bench的构建流程包括: 1. 任务定义:定义了包括一般法律问答、检索增强生成、多步骤推理和基于场景的问题解决等多种法律任务。 2. 数据收集与标注:通过严格的标注流程,由法律专家使用专门的标注系统对每个实例进行标注和交叉验证,确保样本基于权威的法律文件。 3. 基准构建:最终构建包含10,450个样本的VLegal-Bench数据集。 4. 评估指标:使用准确率等指标评估LLMs在不同任务上的表现。
关键创新:VLegal-Bench的主要创新在于: 1. 首个越南法律基准:是第一个专门针对越南法律领域设计的LLM评估基准。 2. 认知驱动设计:基于Bloom的认知分类学,从认知角度评估LLMs的法律理解能力。 3. 模拟真实场景:任务设计模拟真实的法律助理工作流程,更贴近实际应用。
关键设计:VLegal-Bench的关键设计包括: 1. 多样化的任务类型:涵盖多种法律任务,全面评估LLMs的法律能力。 2. 高质量的标注数据:由法律专家进行标注和交叉验证,确保数据的准确性和可靠性。 3. 标准化的评估流程:提供标准化的评估流程和指标,方便研究人员进行比较和分析。
🖼️ 关键图片

📊 实验亮点
VLegal-Bench包含10,450个样本,涵盖一般法律问答、检索增强生成、多步骤推理和基于场景的问题解决等多种任务。通过该基准,研究人员可以系统地评估LLMs在越南法律领域的性能,并为开发更强大的法律AI系统提供数据支持。
🎯 应用场景
VLegal-Bench可用于评估和改进LLMs在越南法律领域的应用,例如智能法律咨询、法律文件检索、案件分析等。该基准有助于开发更可靠、可解释和符合伦理的AI辅助法律系统,提高法律服务的效率和质量,并促进法律知识的普及。
📄 摘要(原文)
The rapid advancement of large language models (LLMs) has enabled new possibilities for applying artificial intelligence within the legal domain. Nonetheless, the complexity, hierarchical organization, and frequent revisions of Vietnamese legislation pose considerable challenges for evaluating how well these models interpret and utilize legal knowledge. To address this gap, the Vietnamese Legal Benchmark (VLegal-Bench) is introduced, the first comprehensive benchmark designed to systematically assess LLMs on Vietnamese legal tasks. Informed by Bloom's cognitive taxonomy, VLegal-Bench encompasses multiple levels of legal understanding through tasks designed to reflect practical usage scenarios. The benchmark comprises 10,450 samples generated through a rigorous annotation pipeline, where legal experts label and cross-validate each instance using our annotation system to ensure every sample is grounded in authoritative legal documents and mirrors real-world legal assistant workflows, including general legal questions and answers, retrieval-augmented generation, multi-step reasoning, and scenario-based problem solving tailored to Vietnamese law. By providing a standardized, transparent, and cognitively informed evaluation framework, VLegal-Bench establishes a solid foundation for assessing LLM performance in Vietnamese legal contexts and supports the development of more reliable, interpretable, and ethically aligned AI-assisted legal systems. To facilitate access and reproducibility, we provide a public landing page for this benchmark at https://vilegalbench.cmcai.vn/.