VersatileFFN: Achieving Parameter Efficiency in LLMs via Adaptive Wide-and-Deep Reuse
作者: Ying Nie, Kai Han, Hongguang Li, Hang Zhou, Tianyu Guo, Enhua Wu, Xinghao Chen, Yunhe Wang
分类: cs.CL
发布日期: 2025-12-16 (更新: 2026-02-01)
🔗 代码/项目: GITHUB
💡 一句话要点
VersatileFFN:通过自适应宽深复用提升LLM的参数效率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 参数高效 大型语言模型 前馈网络 参数复用 宽度深度 自适应 难度感知 模型压缩
📋 核心要点
- 现有LLM参数高效方法主要集中于压缩模型,忽略了架构容量的提升,限制了模型性能。
- VersatileFFN通过宽度和深度两个维度上的参数复用,在固定参数预算下提升模型容量。
- 实验表明,VersatileFFN在多种基准测试和模型规模上均表现出有效性,验证了其参数效率。
📝 摘要(中文)
大型语言模型(LLM)的快速扩展带来了卓越的性能,但也导致了巨大的内存成本。现有的参数高效方法,如剪枝和量化,主要压缩预训练模型,而没有增强架构容量,从而触及了基础模型的表征上限。本文提出了VersatileFFN,一种新颖的前馈网络(FFN),它能够在固定参数预算内灵活地复用宽度和深度维度上的参数。受到认知双过程理论的启发,VersatileFFN包含两个自适应路径:一个宽度多功能路径,从单个共享FFN生成子专家混合,模拟稀疏专家路由而不增加参数;以及一个深度多功能路径,递归地应用相同的FFN来模拟更深层次的处理,以应对复杂的token。一个难度感知门控动态地平衡这两个路径,引导“简单”的token通过高效的宽度路径,并为“困难”的token分配更深层次的迭代细化。至关重要的是,这两个路径都复用相同的参数,因此所有额外的容量都来自计算而非内存。在各种基准和模型规模上的实验证明了该方法的有效性。
🔬 方法详解
问题定义:大型语言模型(LLM)的参数量巨大,导致部署和推理成本高昂。现有的参数高效方法,如剪枝和量化,虽然可以减少参数量,但往往会降低模型性能,并且没有充分利用模型架构的潜力。这些方法主要关注压缩预训练模型,而忽略了通过更有效的架构设计来提升模型容量。
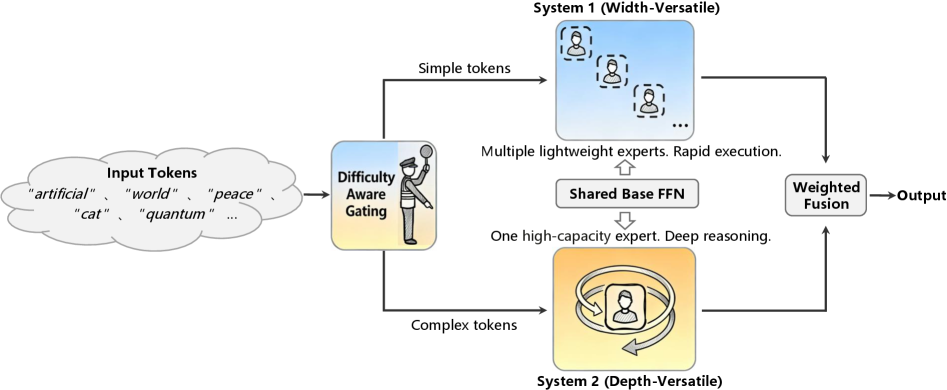
核心思路:VersatileFFN的核心思路是在固定参数预算下,通过参数的宽度和深度复用,提升模型的表达能力。它借鉴了认知双过程理论,设计了宽度多功能路径和深度多功能路径,分别处理简单和复杂的token。通过难度感知门控机制,动态地将token分配到不同的路径,从而实现参数的有效利用。
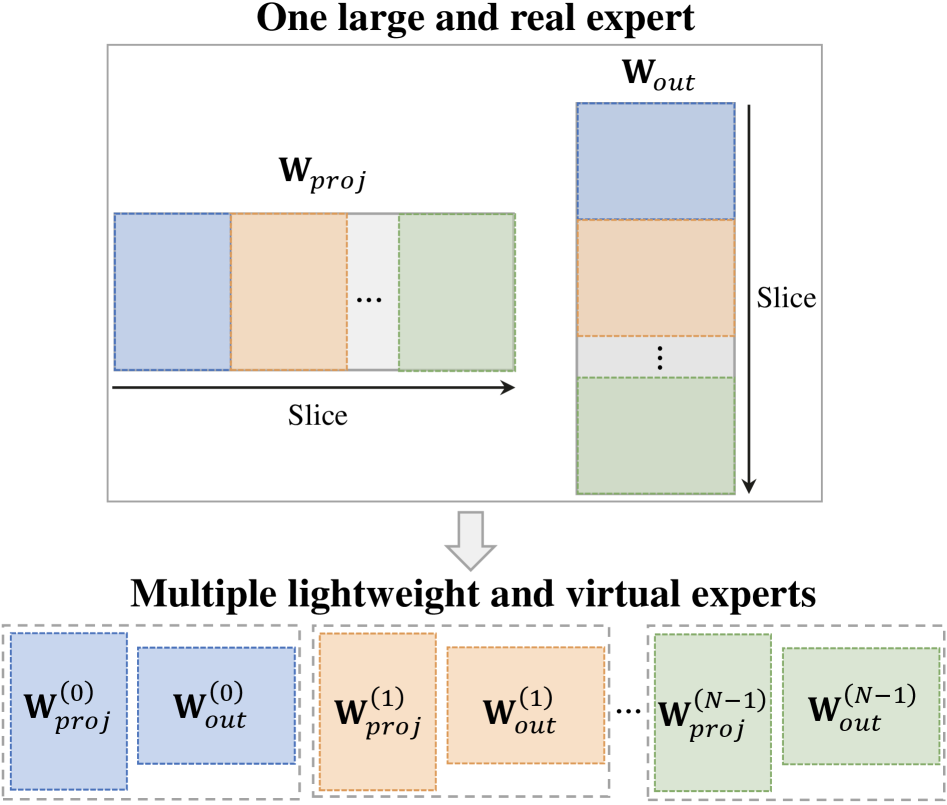
技术框架:VersatileFFN主要包含以下几个模块:1) 共享FFN:一个基础的前馈网络,其参数被宽度和深度路径复用。2) 宽度多功能路径:通过混合来自共享FFN的子专家,模拟稀疏专家路由。3) 深度多功能路径:递归地应用共享FFN,模拟更深层次的处理。4) 难度感知门控:根据token的难度,动态地平衡宽度和深度路径的权重。
关键创新:VersatileFFN的关键创新在于其参数复用机制,它允许模型在不增加参数量的情况下,通过计算来提升模型容量。与传统的参数高效方法不同,VersatileFFN关注于架构设计,通过宽度和深度两个维度上的参数复用,实现了更高的参数效率。难度感知门控也是一个重要的创新点,它能够根据token的难度,动态地调整计算资源的分配。
关键设计:难度感知门控使用一个小型神经网络来预测token的难度,并根据难度值来计算宽度和深度路径的权重。宽度多功能路径通过线性组合来自共享FFN的多个子专家来实现,子专家的数量是一个可调参数。深度多功能路径的递归次数也是一个可调参数,用于控制模型的深度。
🖼️ 关键图片
📊 实验亮点
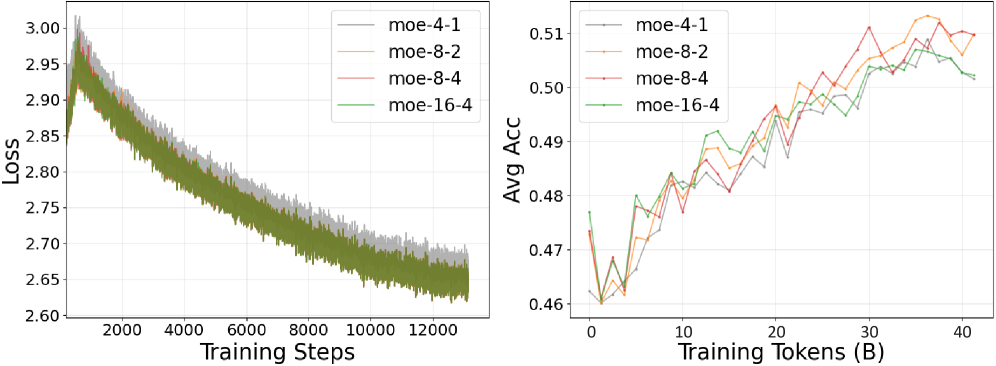
实验结果表明,VersatileFFN在多种基准测试和模型规模上均表现出优异的性能。例如,在某些任务上,VersatileFFN能够在保持相同参数量的情况下,显著提升模型精度,甚至可以达到与参数量更大的模型相当的性能。这些结果验证了VersatileFFN的参数效率和有效性。
🎯 应用场景
VersatileFFN可应用于各种需要高效部署和推理的大型语言模型场景,例如移动设备上的自然语言处理、边缘计算环境下的智能助手、以及资源受限的服务器集群。该方法能够降低模型大小和计算复杂度,从而降低部署成本,提高推理速度,并促进LLM在更广泛的应用场景中的普及。
📄 摘要(原文)
The rapid scaling of Large Language Models (LLMs) has achieved remarkable performance, but it also leads to prohibitive memory costs. Existing parameter-efficient approaches such as pruning and quantization mainly compress pretrained models without enhancing architectural capacity, thereby hitting the representational ceiling of the base model. In this work, we propose VersatileFFN, a novel feed-forward network (FFN) that enables flexible reuse of parameters in both width and depth dimensions within a fixed parameter budget. Inspired by the dual-process theory of cognition, VersatileFFN comprises two adaptive pathways: a width-versatile path that generates a mixture of sub-experts from a single shared FFN, mimicking sparse expert routing without increasing parameters, and a depth-versatile path that recursively applies the same FFN to emulate deeper processing for complex tokens. A difficulty-aware gating dynamically balances the two pathways, steering "easy" tokens through the efficient width-wise route and allocating deeper iterative refinement to "hard" tokens. Crucially, both pathways reuse the same parameters, so all additional capacity comes from computation rather than memory. Experiments across diverse benchmarks and model scales demonstrate the effectiveness of the method. The code is available at https://github.com/huawei-noah/noah-research/tree/master/VersatileFFN.