FiNERweb: Datasets and Artifacts for Scalable Multilingual Named Entity Recognition
作者: Jonas Golde, Patrick Haller, Alan Akbik
分类: cs.CL
发布日期: 2025-12-15
💡 一句话要点
FiNERweb:构建可扩展的多语命名实体识别数据集及相关工具
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语命名实体识别 数据集构建 教师-学生学习 零样本迁移 大型语言模型
📋 核心要点
- 现有的多语命名实体识别工作依赖大型语言模型进行合成监督,但数据集通常是实验副产品,缺乏系统性和可重用性。
- FiNERweb通过训练回归模型识别NER相关段落,并利用多语种LLM进行标注,从而大规模创建多语NER数据集。
- 实验表明,FiNERweb训练的模型在零样本迁移任务中表现优异,且标注质量高,为多语NER研究提供了宝贵资源。
📝 摘要(中文)
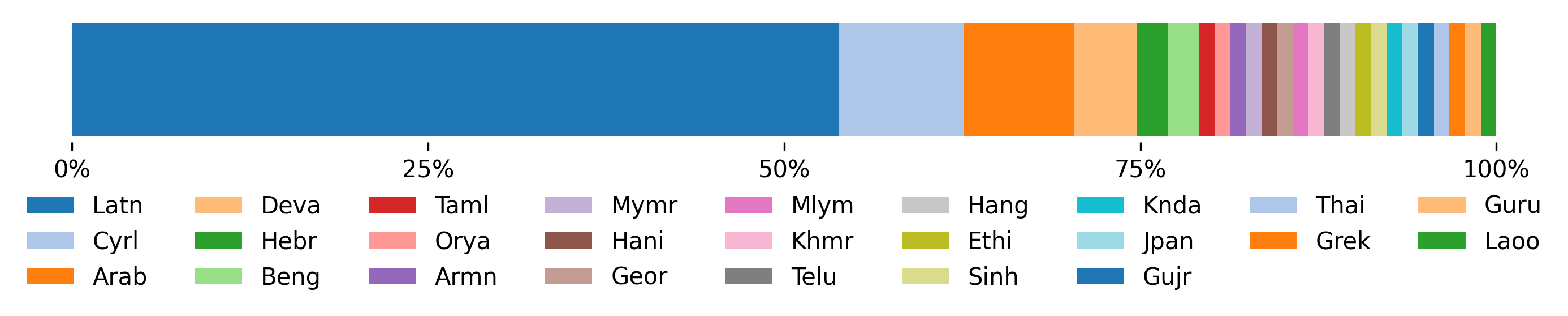
本文介绍了一种名为FiNERweb的数据集创建流程,该流程将教师-学生范式扩展到91种语言和25种文字。该方法基于FineWeb-Edu,训练回归模型来识别与命名实体识别(NER)相关的段落,并使用多语种LLM对其进行标注,从而产生约22.5万个段落,包含23.5万个不同的实体标签。实验表明,回归模型实现了超过84的F1值,并且在FiNERweb上训练的模型在英语、泰语和斯瓦希里语的零样本迁移设置中获得了可比较或更高的性能,尽管训练数据比强基线少19倍。此外,我们使用LLM作为评判者评估了标注质量,观察到忠实度(5分制为3.99)和完整性(5分制为4.05)均获得了持续的高分,表明标注是可靠且信息丰富的。我们发布了包含英文标签和翻译成目标语言的标签集的数据集,因为我们观察到,使用目标语言标签而不是英文标签进行评估时,当前最先进模型的性能会下降0.02到0.09 F1。为了促进更有效的多语命名实体识别的师生训练,我们将FiNERweb及其所有相关工具发布给研究社区。
🔬 方法详解
问题定义:论文旨在解决多语命名实体识别(NER)中缺乏大规模、高质量训练数据的问题。现有的方法要么依赖于人工标注,成本高昂且难以扩展到多种语言,要么使用大型语言模型(LLM)进行合成数据生成,但这些数据集通常是特定实验的副产品,缺乏通用性和可重用性。因此,需要一种能够高效、可扩展地生成多语NER训练数据的方法。
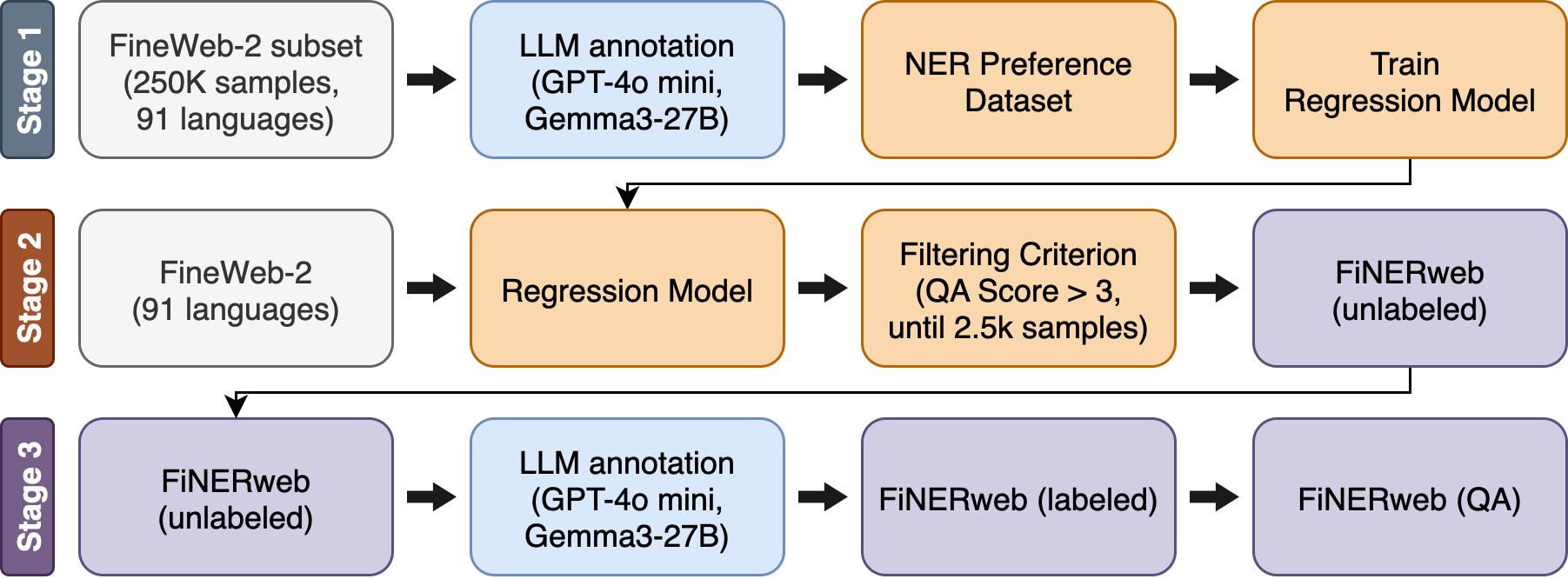
核心思路:论文的核心思路是利用教师-学生范式,首先训练一个回归模型(教师模型)来识别包含NER相关信息的文本段落,然后使用多语种LLM(学生模型)对这些段落进行自动标注。这种方法结合了回归模型的高效性和LLM的语言理解能力,能够在多种语言中快速生成大量的NER训练数据。
技术框架:FiNERweb的整体流程包括以下几个主要步骤:1) 基于FineWeb-Edu数据集,训练一个回归模型,用于预测文本段落与NER任务的相关性得分。2) 使用训练好的回归模型从大规模文本语料库中筛选出NER相关的段落。3) 使用多语种LLM对筛选出的段落进行命名实体标注。4) 对标注结果进行质量评估,并发布数据集和相关工具。
关键创新:FiNERweb的关键创新在于其可扩展性。通过使用回归模型进行段落筛选,可以显著减少需要LLM标注的文本量,从而降低了标注成本,使得该方法能够扩展到91种语言和25种文字。此外,论文还提供了英文标签和翻译成目标语言的标签集,以解决不同语言标签带来的性能差异问题。
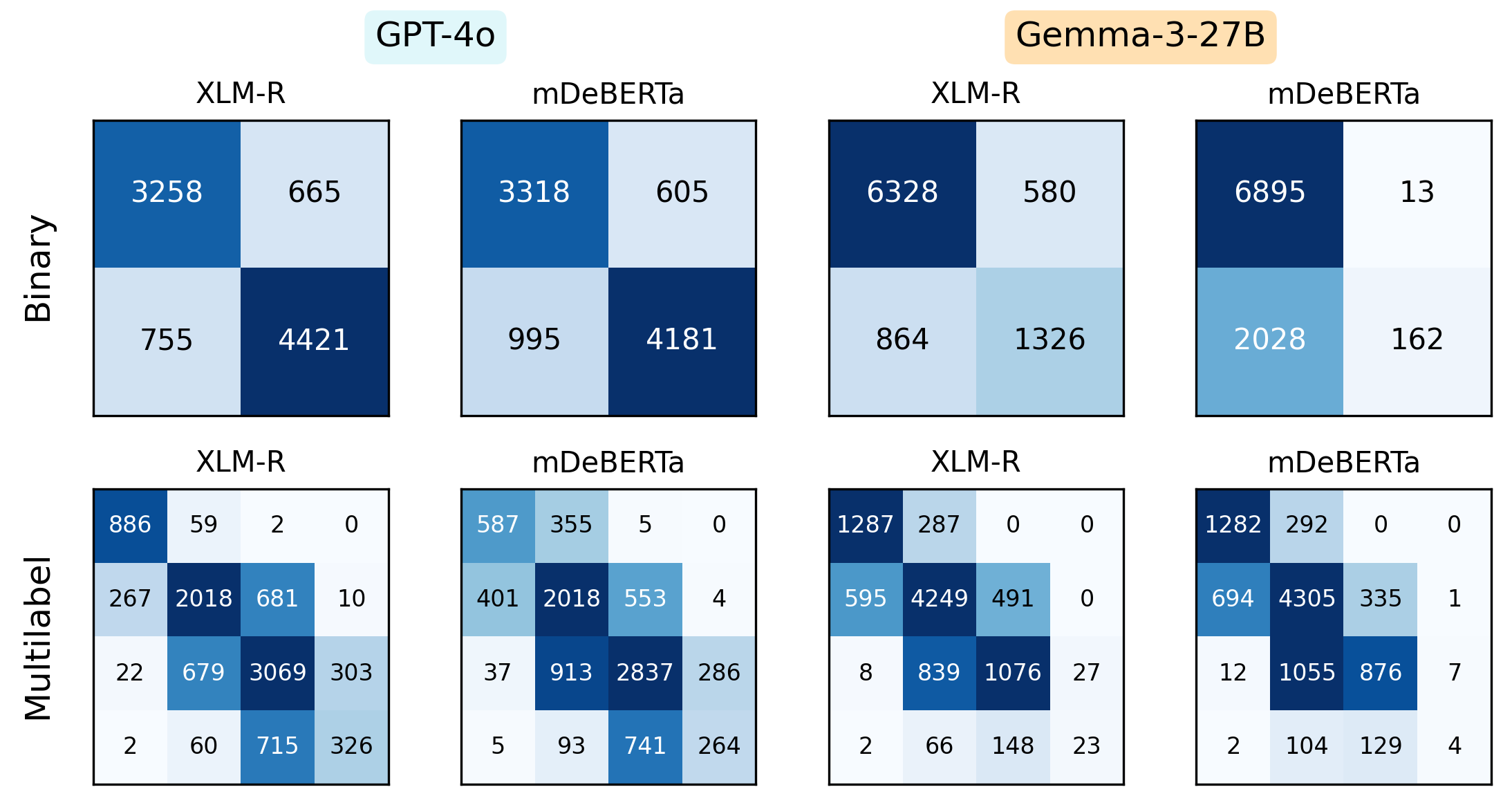
关键设计:回归模型使用预训练语言模型作为 backbone,并添加回归层预测NER相关性得分。损失函数采用均方误差(MSE)。LLM的选择和prompt的设计对标注质量至关重要,论文使用了高质量的多语种LLM,并设计了合适的prompt来指导LLM进行NER标注。此外,论文还使用LLM-as-a-judge的方法对标注质量进行了评估,以确保数据集的可靠性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在FiNERweb上训练的模型在英语、泰语和斯瓦希里语的零样本迁移设置中取得了与强基线模型相当甚至更好的性能,尽管训练数据量仅为基线的1/19。此外,使用LLM作为评判者对标注质量的评估结果显示,忠实度和完整性得分均超过4.0(满分5分),表明FiNERweb数据集具有较高的质量。
🎯 应用场景
FiNERweb数据集可广泛应用于多语命名实体识别任务,例如信息抽取、机器翻译、跨语言信息检索等。该数据集能够帮助研究人员训练出更鲁棒、更通用的多语NER模型,从而提升各种下游任务的性能。此外,FiNERweb的构建流程也为其他多语自然语言处理任务的数据集构建提供了借鉴。
📄 摘要(原文)
Recent multilingual named entity recognition (NER) work has shown that large language models (LLMs) can provide effective synthetic supervision, yet such datasets have mostly appeared as by-products of broader experiments rather than as systematic, reusable resources. We introduce FiNERweb, a dataset-creation pipeline that scales the teacher-student paradigm to 91 languages and 25 scripts. Building on FineWeb-Edu, our approach trains regression models to identify NER-relevant passages and annotates them with multilingual LLMs, resulting in about 225k passages with 235k distinct entity labels. Our experiments show that the regression model achieves more than 84 F1, and that models trained on FiNERweb obtain comparable or improved performance in zero shot transfer settings on English, Thai, and Swahili, despite being trained on 19x less data than strong baselines. In addition, we assess annotation quality using LLM-as-a-judge and observe consistently high scores for both faithfulness (3.99 out of 5) and completeness (4.05 out of 5), indicating reliable and informative annotations. Further, we release the dataset with both English labels and translated label sets in the respective target languages because we observe that the performance of current state-of-the-art models drops by 0.02 to 0.09 F1 when evaluated using target language labels instead of English ones. We release FiNERweb together with all accompanying artifacts to the research community in order to facilitate more effective student-teacher training for multilingual named entity recognition.