Nemotron-Cascade: Scaling Cascaded Reinforcement Learning for General-Purpose Reasoning Models
作者: Boxin Wang, Chankyu Lee, Nayeon Lee, Sheng-Chieh Lin, Wenliang Dai, Yang Chen, Yangyi Chen, Zhuolin Yang, Zihan Liu, Mohammad Shoeybi, Bryan Catanzaro, Wei Ping
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-12-15
备注: We publicly release the Nemotron-Cascade models and the full collection of training data at: https://huggingface.co/collections/nvidia/nemotron-cascade
💡 一句话要点
提出级联强化学习Nemotron-Cascade,用于构建通用推理模型。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 通用推理模型 级联学习 领域自适应 RLHF 价值回归 代码生成
📋 核心要点
- 现有通用推理模型在强化学习训练中面临跨领域异构性挑战,包括响应长度和验证延迟的巨大差异。
- Cascade RL通过编排领域相关的顺序强化学习,降低了工程复杂性,并简化了训练课程和超参数选择。
- 实验表明,RLHF预训练能显著提升模型推理能力,后续领域强化学习阶段能保持甚至提升性能。
📝 摘要(中文)
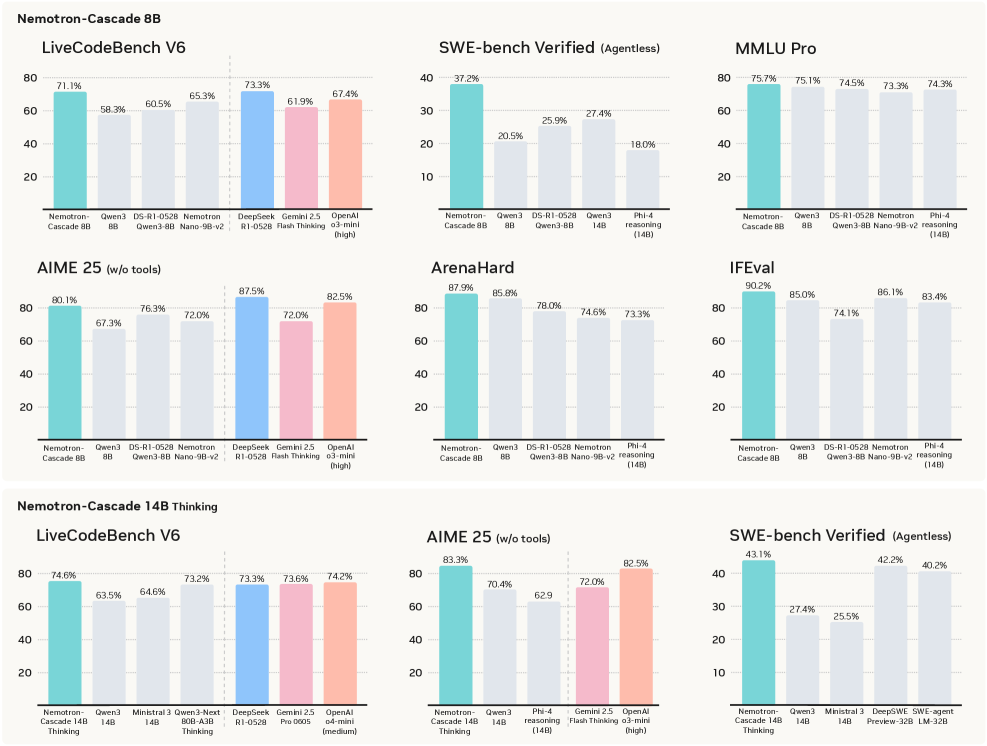
本文提出级联领域强化学习(Cascade RL)方法,用于开发能够以指令模式和深度思考模式运行的通用推理模型Nemotron-Cascade。与混合不同领域提示的传统方法不同,Cascade RL编排顺序的、领域相关的强化学习,从而降低工程复杂性,并在各种基准测试中提供最先进的性能。值得注意的是,用于对齐的RLHF作为预处理步骤,极大地提升了模型的推理能力,远超单纯的偏好优化。随后的领域强化学习价值回归(RLVR)阶段很少会降低早期领域中获得的基准性能,甚至可能有所提高。我们的14B模型在RL之后,在LiveCodeBench v5/v6/Pro上优于其SFT教师DeepSeek-R1-0528,并在2025年国际信息学奥林匹克竞赛(IOI)中获得银牌。我们透明地分享了我们的训练和数据方案。
🔬 方法详解
问题定义:论文旨在解决通用推理模型在强化学习训练中面临的跨领域异构性问题。具体来说,不同领域任务的响应长度和验证延迟差异很大,这使得强化学习基础设施复杂化,训练速度减慢,并且训练课程(例如,响应长度扩展)和超参数选择变得具有挑战性。现有方法通常采用混合不同领域提示的方式,但这种方式增加了工程复杂性。
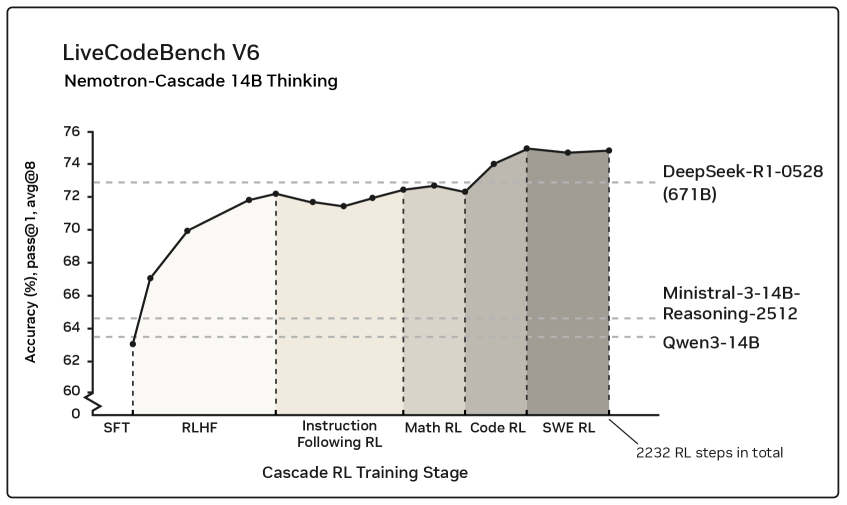
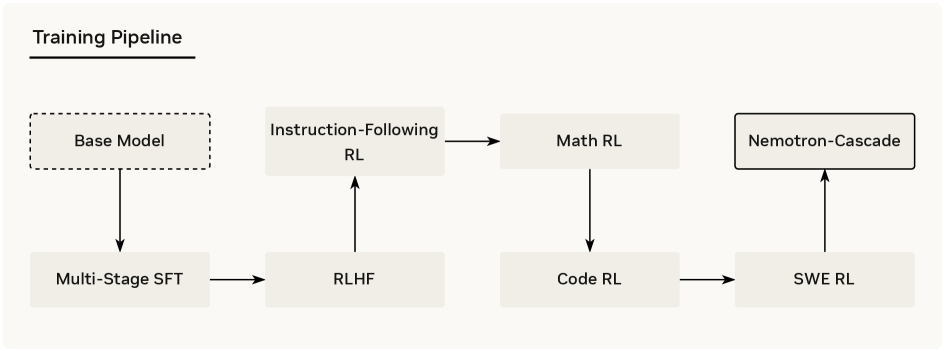
核心思路:论文的核心思路是采用级联的领域强化学习(Cascade RL)。即,将不同领域的强化学习任务按照一定的顺序进行训练,而不是混合在一起。这样可以针对每个领域单独进行优化,降低训练难度,并简化超参数调整。此外,论文还发现,先进行RLHF对齐,可以显著提升模型的推理能力。
技术框架:Nemotron-Cascade的训练流程主要包含两个阶段:首先,使用RLHF(Reinforcement Learning from Human Feedback)进行对齐,提升模型的基础推理能力。然后,进行领域相关的强化学习价值回归(RLVR),即Cascade RL。在Cascade RL阶段,模型按照预定的领域顺序进行训练,每个领域都使用特定的奖励函数和训练数据。
关键创新:论文的关键创新在于提出了Cascade RL,这是一种将强化学习应用于通用推理模型的新方法。与传统的混合领域提示方法相比,Cascade RL能够更好地处理跨领域异构性问题,降低工程复杂性,并提升模型性能。此外,论文还发现RLHF预训练对提升模型推理能力具有重要作用。
关键设计:论文中没有详细描述具体的参数设置、损失函数或网络结构等技术细节。但是,论文强调了RLHF预训练的重要性,并指出领域强化学习阶段很少会降低早期领域中获得的基准性能,甚至可能有所提高。这表明Cascade RL具有良好的稳定性和泛化能力。
🖼️ 关键图片
📊 实验亮点
实验结果表明,经过Cascade RL训练的14B模型Nemotron-Cascade,在LiveCodeBench v5/v6/Pro上优于其SFT教师DeepSeek-R1-0528。此外,该模型在2025年国际信息学奥林匹克竞赛(IOI)中获得银牌,证明了其强大的推理能力和解决复杂问题的能力。
🎯 应用场景
该研究成果可应用于构建更强大的通用人工智能系统,例如智能助手、代码生成工具和科学研究助手。通过级联强化学习,可以有效地训练模型处理各种复杂任务,并提升其推理能力和泛化性能。该方法在自动化编程、问题求解、决策支持等领域具有广阔的应用前景。
📄 摘要(原文)
Building general-purpose reasoning models with reinforcement learning (RL) entails substantial cross-domain heterogeneity, including large variation in inference-time response lengths and verification latency. Such variability complicates the RL infrastructure, slows training, and makes training curriculum (e.g., response length extension) and hyperparameter selection challenging. In this work, we propose cascaded domain-wise reinforcement learning (Cascade RL) to develop general-purpose reasoning models, Nemotron-Cascade, capable of operating in both instruct and deep thinking modes. Departing from conventional approaches that blend heterogeneous prompts from different domains, Cascade RL orchestrates sequential, domain-wise RL, reducing engineering complexity and delivering state-of-the-art performance across a wide range of benchmarks. Notably, RLHF for alignment, when used as a pre-step, boosts the model's reasoning ability far beyond mere preference optimization, and subsequent domain-wise RLVR stages rarely degrade the benchmark performance attained in earlier domains and may even improve it (see an illustration in Figure 1). Our 14B model, after RL, outperforms its SFT teacher, DeepSeek-R1-0528, on LiveCodeBench v5/v6/Pro and achieves silver-medal performance in the 2025 International Olympiad in Informatics (IOI). We transparently share our training and data recipes.