SkipCat: Rank-Maximized Low-Rank Compression of Large Language Models via Shared Projection and Block Skipping
作者: Yu-Chen Lu, Sheng-Feng Yu, Hui-Hsien Weng, Pei-Shuo Wang, Yu-Fang Hu, Liang Hung-Chun, Hung-Yueh Chiang, Kai-Chiang Wu
分类: cs.CL, cs.AI
发布日期: 2025-12-15
备注: Accepted by AAAI 2026
💡 一句话要点
SkipCat:通过共享投影和块跳跃实现大语言模型秩最大化的低秩压缩
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 低秩压缩 大语言模型 模型压缩 共享投影 块跳跃
📋 核心要点
- 大语言模型参数量巨大,给边缘设备的部署带来挑战,需要有效的压缩方法。
- SkipCat通过共享投影和块跳跃,在相同压缩率下保留更高的有效秩,从而提升性能。
- 实验表明,SkipCat在零样本任务上,无需微调即可比现有低秩压缩方法提升7%的准确率。
📝 摘要(中文)
大型语言模型(LLM)在各种任务中取得了显著的性能。然而,它们庞大的参数规模对在计算和内存资源有限的边缘设备上的部署提出了重大挑战。低秩压缩是一种很有前途的方法,因为它降低了计算和内存成本,使LLM更适合资源受限的环境。然而,简单的低秩压缩方法需要大幅降低保留秩才能实现有意义的内存和计算节省。对于低秩模型,需要将秩降低一半以上才能产生效率提升。然而,这种激进的截断通常会导致严重的性能下降。为了解决这种权衡,我们提出SkipCat,一种新颖的低秩压缩框架,它能够在实现相同压缩率的同时使用更高的秩。首先,我们引入了一种层内共享低秩投影方法,其中多个共享相同输入的矩阵使用公共投影。这减少了冗余并提高了压缩效率。其次,我们提出了一种块跳跃技术,该技术省略了低秩分解中选定子块的计算和内存传输。这两种技术共同使我们的压缩模型能够在相同的压缩预算下保留更有效的秩。实验结果表明,在没有任何额外微调的情况下,我们的方法在相同压缩率下,在零样本任务上的准确率比以前的低秩压缩方法提高了7%。这些结果突出了我们的秩最大化压缩策略在保持资源受限情况下的模型性能方面的有效性。
🔬 方法详解
问题定义:论文旨在解决大语言模型低秩压缩中,为了达到足够的压缩率,不得不大幅降低秩,导致模型性能显著下降的问题。现有方法在压缩率和模型性能之间存在严重的trade-off。
核心思路:核心思路是在相同的压缩预算下,尽可能保留更多的有效秩。通过减少冗余计算和内存传输,使得模型能够在压缩的同时,保持较高的性能水平。
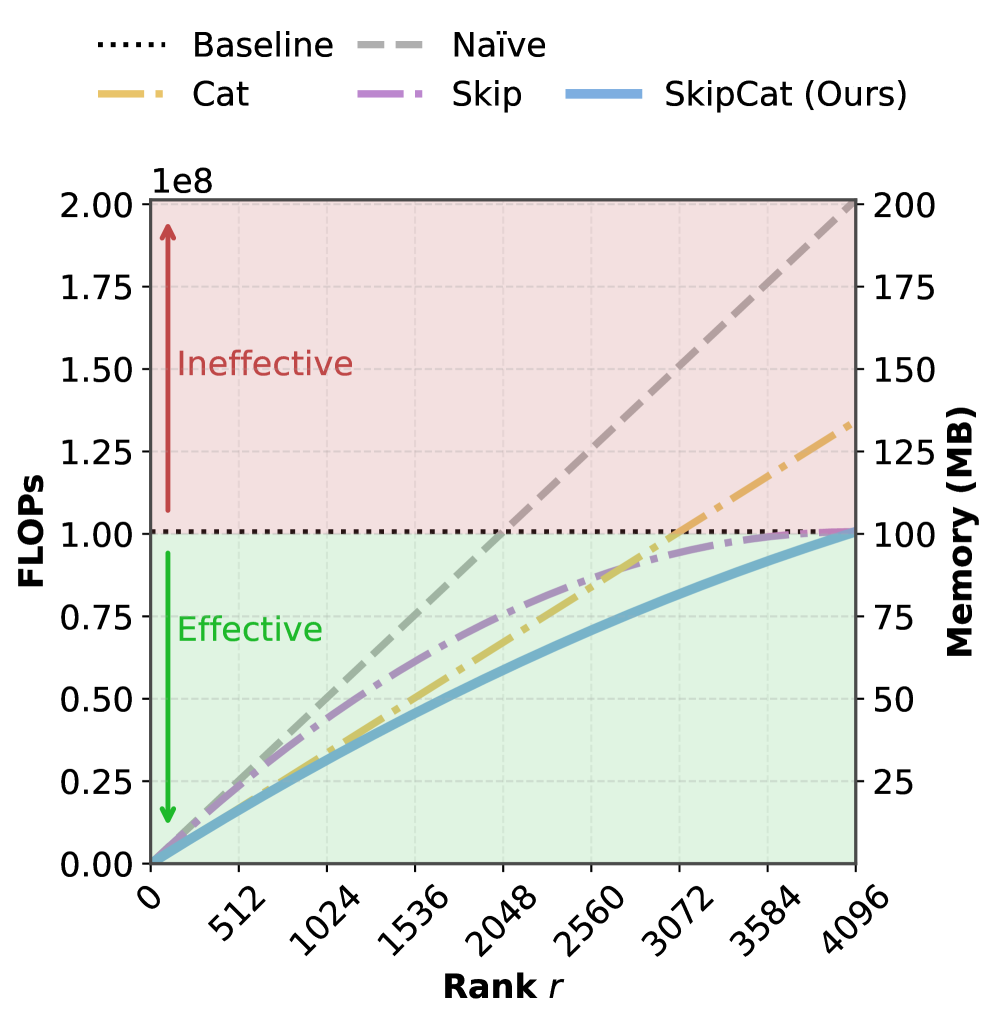
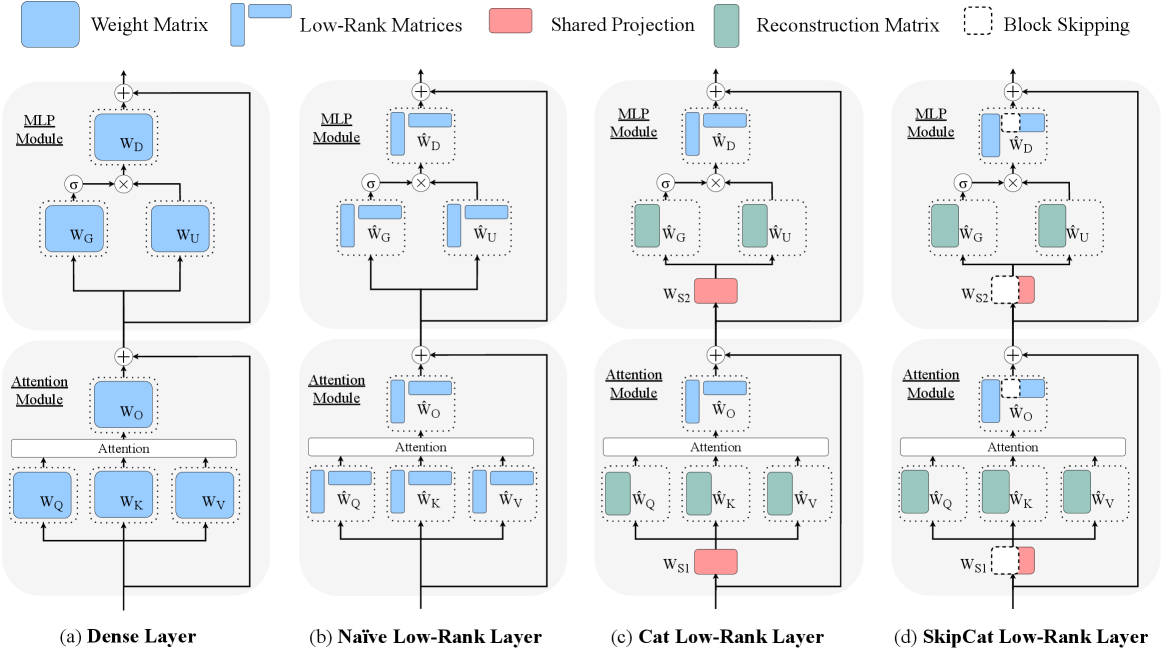
技术框架:SkipCat包含两个主要技术:1) 层内共享低秩投影:多个矩阵共享同一个低秩投影,减少冗余;2) 块跳跃:跳过低秩分解中部分子块的计算和内存传输。这两个技术结合使用,能够在相同的压缩率下,保留更多的有效秩。
关键创新:关键创新在于将共享投影和块跳跃两种技术结合,实现了秩最大化的低秩压缩。与传统低秩压缩方法不同,SkipCat不是简单地降低秩,而是通过减少冗余来提升有效秩。
关键设计:共享投影的具体实现方式是让多个矩阵共享同一个输入投影矩阵。块跳跃的具体实现方式是根据一定的策略(例如,基于重要性评分)选择要跳过的子块。论文中没有详细说明具体的重要性评分策略,这部分可能是未来的研究方向。
🖼️ 关键图片

📊 实验亮点
SkipCat在零样本任务上取得了显著的性能提升。在相同的压缩率下,SkipCat无需任何额外的微调,即可比之前的低秩压缩方法提高7%的准确率。这表明SkipCat能够更有效地保留模型中的重要信息,从而在压缩的同时保持较高的性能水平。
🎯 应用场景
SkipCat适用于需要在资源受限的边缘设备上部署大型语言模型的场景,例如移动设备、嵌入式系统等。该方法可以有效降低模型的计算和内存需求,使得这些设备能够运行复杂的LLM应用,例如智能助手、机器翻译、文本生成等。该研究对于推动LLM在边缘计算领域的应用具有重要意义。
📄 摘要(原文)
Large language models (LLM) have achieved remarkable performance across a wide range of tasks. However, their substantial parameter sizes pose significant challenges for deployment on edge devices with limited computational and memory resources. Low-rank compression is a promising approach to address this issue, as it reduces both computational and memory costs, making LLM more suitable for resource-constrained environments. Nonetheless, naïve low-rank compression methods require a significant reduction in the retained rank to achieve meaningful memory and computation savings. For a low-rank model, the ranks need to be reduced by more than half to yield efficiency gains. Such aggressive truncation, however, typically results in substantial performance degradation. To address this trade-off, we propose SkipCat, a novel low-rank compression framework that enables the use of higher ranks while achieving the same compression rates. First, we introduce an intra-layer shared low-rank projection method, where multiple matrices that share the same input use a common projection. This reduces redundancy and improves compression efficiency. Second, we propose a block skipping technique that omits computations and memory transfers for selected sub-blocks within the low-rank decomposition. These two techniques jointly enable our compressed model to retain more effective ranks under the same compression budget. Experimental results show that, without any additional fine-tuning, our method outperforms previous low-rank compression approaches by 7% accuracy improvement on zero-shot tasks under the same compression rate. These results highlight the effectiveness of our rank-maximized compression strategy in preserving model performance under tight resource constraints.