Scaling Laws for Code: Every Programming Language Matters
作者: Jian Yang, Shawn Guo, Lin Jing, Wei Zhang, Aishan Liu, Chuan Hao, Zhoujun Li, Wayne Xin Zhao, Xianglong Liu, Weifeng Lv, Bryan Dai
分类: cs.CL
发布日期: 2025-12-15
💡 一句话要点
针对代码大语言模型,提出编程语言感知的多语言缩放法则,优化预训练性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码大语言模型 多语言预训练 缩放法则 编程语言 模型训练
📋 核心要点
- 现有代码大语言模型训练成本高,且忽略了不同编程语言对模型性能的差异化影响。
- 提出编程语言感知的多语言缩放法则,通过分析不同语言的特性,优化训练数据的分配策略。
- 实验表明,该方法能够提升多语言代码大语言模型的平均性能,尤其是在跨语言能力方面。
📝 摘要(中文)
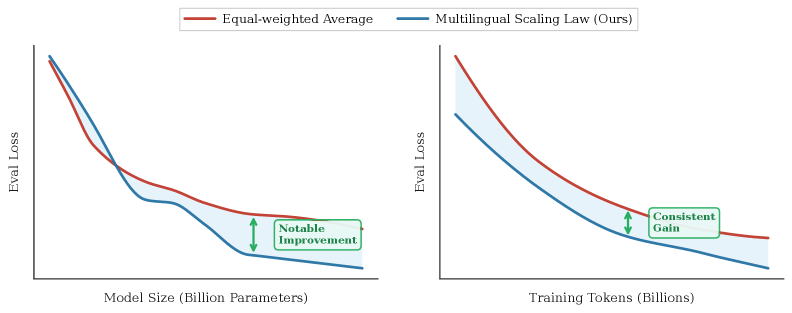
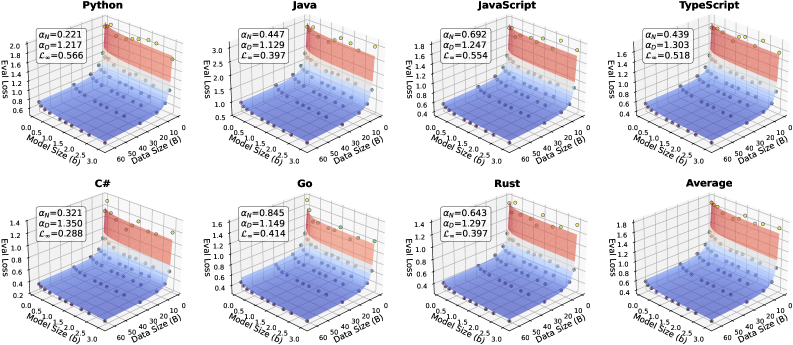
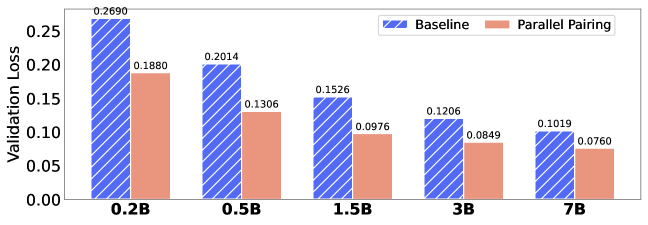
代码大语言模型(Code LLM)功能强大但训练成本高昂,缩放法则可以根据模型大小、数据和计算量预测性能。然而,不同编程语言(PL)在预训练期间的影响不同,显著影响基础模型性能,导致性能预测不准确。此外,现有工作侧重于语言无关设置,忽略了现代软件开发固有的多语言性质。因此,首先需要研究不同PL的缩放法则,然后考虑它们的相互影响,以得出最终的多语言缩放法则。本文首次对多语言代码预训练的缩放法则进行了系统探索,进行了1000多次实验(相当于336,000多个H800小时),涵盖了多种PL、模型大小(0.2B到14B参数)和数据集大小(1T tokens)。我们建立了跨多种PL的代码LLM的综合缩放法则,揭示了解释型语言(如Python)比编译型语言(如Rust)从增加模型大小和数据中获益更多。研究表明,多语言预训练提供了协同效益,尤其是在语法相似的PL之间。此外,并行配对(将代码片段与其翻译连接起来)的预训练策略显著增强了跨语言能力,并具有良好的缩放特性。最后,提出了一种比例依赖的多语言缩放法则,通过优先考虑高实用性的PL(如Python)、平衡高协同配对(如JavaScript-TypeScript)和减少对快速饱和语言(Rust)的分配来优化训练tokens的分配,与相同计算预算下的均匀分配相比,实现了所有PL的卓越平均性能。
🔬 方法详解
问题定义:现有代码大语言模型(Code LLM)的训练依赖于缩放法则,但这些法则通常忽略了不同编程语言(PL)在预训练过程中的差异性影响。现有方法通常采用语言无关的设置,未能充分利用现代软件开发中多语言协同的优势。因此,如何针对不同编程语言的特性,优化多语言代码大语言模型的训练,是一个亟待解决的问题。
核心思路:论文的核心思路是建立编程语言感知的多语言缩放法则。该法则通过分析不同编程语言的特性(如解释型语言与编译型语言的差异),以及它们之间的协同效应,来指导训练数据的分配。核心在于根据不同语言的“效用”和“协同性”进行加权,从而在相同的计算资源下,最大化模型的整体性能。
技术框架:该研究的技术框架主要包含以下几个阶段:1) 大规模实验:进行超过1000次实验,涵盖多种编程语言、模型大小和数据集大小,以收集不同语言的缩放数据。2) 缩放法则建模:基于实验数据,建立不同编程语言的缩放法则,分析模型大小、数据量与性能之间的关系。3) 多语言协同分析:研究不同编程语言之间的协同效应,例如语法相似的语言之间的互补性。4) 比例依赖的训练策略:提出一种比例依赖的训练策略,根据不同语言的效用和协同性,动态调整训练数据的分配比例。
关键创新:该论文的关键创新在于:1) 首次系统性地研究了多语言代码预训练的缩放法则,揭示了不同编程语言对模型性能的差异化影响。2) 提出了比例依赖的多语言缩放法则,能够根据不同语言的特性,优化训练数据的分配,从而提升模型的整体性能。3) 验证了并行配对的预训练策略能够有效提升模型的跨语言能力。
关键设计:在比例依赖的训练策略中,关键的设计包括:1) 定义了编程语言的“效用”指标,用于衡量该语言对模型性能的贡献。2) 定义了编程语言之间的“协同性”指标,用于衡量两种语言之间的互补程度。3) 基于效用和协同性,设计了一种动态调整训练数据分配比例的算法。具体而言,该算法会优先分配更多资源给高效用语言(如Python),平衡高效协同配对(如JavaScript-TypeScript),并减少对快速饱和语言(如Rust)的分配。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法提出的比例依赖的多语言缩放法则,在相同的计算预算下,能够显著提升多语言代码大语言模型的平均性能。具体而言,与均匀分配训练数据相比,该方法能够提升模型在多种编程语言上的代码生成和理解能力,尤其是在跨语言代码翻译任务上,性能提升更为明显。
🎯 应用场景
该研究成果可应用于代码大语言模型的预训练,提升模型在多语言环境下的代码生成、代码理解和代码翻译能力。通过优化训练数据的分配,可以降低训练成本,提高模型性能,从而加速软件开发效率,并促进跨语言软件的开发和维护。此外,该研究也为其他多语言自然语言处理任务提供了借鉴。
📄 摘要(原文)
Code large language models (Code LLMs) are powerful but costly to train, with scaling laws predicting performance from model size, data, and compute. However, different programming languages (PLs) have varying impacts during pre-training that significantly affect base model performance, leading to inaccurate performance prediction. Besides, existing works focus on language-agnostic settings, neglecting the inherently multilingual nature of modern software development. Therefore, it is first necessary to investigate the scaling laws of different PLs, and then consider their mutual influences to arrive at the final multilingual scaling law. In this paper, we present the first systematic exploration of scaling laws for multilingual code pre-training, conducting over 1000+ experiments (Equivalent to 336,000+ H800 hours) across multiple PLs, model sizes (0.2B to 14B parameters), and dataset sizes (1T tokens). We establish comprehensive scaling laws for code LLMs across multiple PLs, revealing that interpreted languages (e.g., Python) benefit more from increased model size and data than compiled languages (e.g., Rust). The study demonstrates that multilingual pre-training provides synergistic benefits, particularly between syntactically similar PLs. Further, the pre-training strategy of the parallel pairing (concatenating code snippets with their translations) significantly enhances cross-lingual abilities with favorable scaling properties. Finally, a proportion-dependent multilingual scaling law is proposed to optimally allocate training tokens by prioritizing high-utility PLs (e.g., Python), balancing high-synergy pairs (e.g., JavaScript-TypeScript), and reducing allocation to fast-saturating languages (Rust), achieving superior average performance across all PLs compared to uniform distribution under the same compute budget.