Uncovering the Role of Initial Saliency in U-Shaped Attention Bias: Scaling Initial Token Weight for Enhanced Long-Text Processing
作者: Zewen Qiang, Sendong Zhao, Haochun Wang, Bing Qin, Ting Liu
分类: cs.CL, cs.AI
发布日期: 2025-12-15
💡 一句话要点
揭示初始显著性在U型注意力偏差中的作用:通过缩放初始Token权重增强长文本处理
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本处理 注意力机制 初始显著性 U型注意力偏差 大型语言模型
📋 核心要点
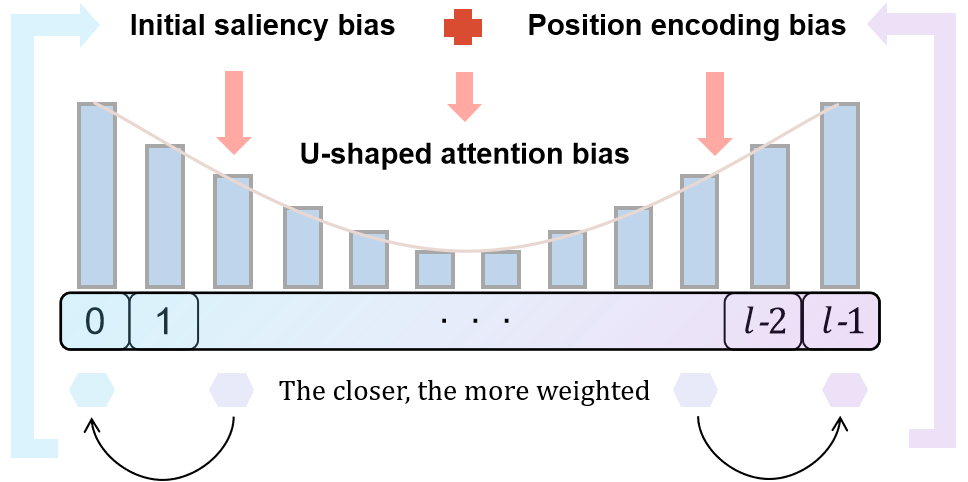
- 大型语言模型在长文本处理中存在“中间迷失”问题,即对文本中间部分的关注不足。
- 论文提出通过缩放初始token的注意力权重来利用初始显著性,从而改善模型对长文本的处理能力。
- 实验表明,该方法在MDQA和KV-Retrieval任务中均取得了显著的性能提升,最高分别提升3.6%和3.4%。
📝 摘要(中文)
大型语言模型(LLMs)在各种自然语言处理(NLP)任务中表现出强大的性能。然而,由于“中间迷失”现象,它们在处理长文本序列时常常遇到困难。这个问题已被证明源于U型注意力偏差,即注意力不成比例地集中在文本的开头和结尾,而中间部分则被低估。先前的研究将这种偏差归因于位置编码,但我们的研究首先确定了一个额外的因素:初始显著性。这意味着在每个token的注意力计算中,相对于初始token具有更高注意权重的token,在预测下一个token时往往会获得更多的关注。我们进一步发现,通过缩放初始token和其他token之间的注意力权重来利用这一特性,可以提高模型处理长上下文的能力,在MDQA数据集中实现了高达3.6%的改进。此外,将这种方法与现有方法相结合,以减少位置编码偏差,可以进一步提高性能,在KV-Retrieval任务中实现了高达3.4%的改进。
🔬 方法详解
问题定义:大型语言模型在处理长文本时,存在“中间迷失”现象,即模型对文本中间部分的理解和利用不足。现有方法主要关注位置编码带来的偏差,但忽略了初始token的显著性对后续token注意力的影响。这种现象导致模型在长文本任务中性能下降,无法充分利用文本信息。
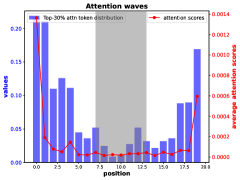
核心思路:论文的核心思路是揭示并利用初始显著性在U型注意力偏差中的作用。通过观察发现,相对于初始token具有更高注意权重的token,在预测下一个token时往往会获得更多的关注。因此,通过调整初始token与其他token之间的注意力权重,可以引导模型更多地关注文本的中间部分,从而缓解“中间迷失”问题。
技术框架:该方法主要是在Transformer模型的注意力机制中进行改进。具体来说,在计算每个token的注意力权重时,对初始token与其他token之间的注意力权重进行缩放。这个缩放操作可以增强或减弱初始token对其他token的影响,从而调整模型对文本不同位置的关注程度。该方法可以与现有的位置编码偏差缓解方法相结合,进一步提升性能。
关键创新:论文的关键创新在于发现了初始显著性是导致U型注意力偏差的一个重要因素,并提出了一种简单有效的缩放初始token注意力权重的方法来缓解这个问题。与以往主要关注位置编码的方法不同,该研究从注意力机制本身入手,揭示了初始token在注意力计算中的特殊作用。
关键设计:论文的关键设计在于如何选择合适的缩放因子来调整初始token的注意力权重。具体实现上,可以通过一个可学习的参数来控制缩放的程度,也可以根据任务的特点手动设置。此外,该方法可以灵活地与不同的Transformer模型和注意力机制相结合,具有较强的通用性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,通过缩放初始token的注意力权重,该方法在MDQA数据集中实现了高达3.6%的性能提升,在KV-Retrieval任务中实现了高达3.4%的性能提升。这些结果表明,该方法能够有效地缓解“中间迷失”问题,提高模型对长文本的处理能力。此外,该方法与现有位置编码偏差缓解方法相结合,可以进一步提升性能。
🎯 应用场景
该研究成果可应用于各种需要处理长文本的自然语言处理任务,例如长文档摘要、问答系统、机器翻译等。通过提升模型对长文本的理解能力,可以提高这些应用在处理复杂文本时的准确性和效率。此外,该研究对于改进大型语言模型的架构设计和训练策略具有一定的指导意义。
📄 摘要(原文)
Large language models (LLMs) have demonstrated strong performance on a variety of natural language processing (NLP) tasks. However, they often struggle with long-text sequences due to the ``lost in the middle'' phenomenon. This issue has been shown to arise from a U-shaped attention bias, where attention is disproportionately focused on the beginning and end of a text, leaving the middle section underrepresented. While previous studies have attributed this bias to position encoding, our research first identifies an additional factor: initial saliency. It means that in the attention computation for each token, tokens with higher attention weights relative to the initial token tend to receive more attention in the prediction of the next token. We further find that utilizing this property by scaling attention weight between the initial token and others improves the model's ability to process long contexts, achieving a maximum improvement of 3.6\% in MDQA dataset. Moreover, combining this approach with existing methods to reduce position encoding bias further enhances performance, achieving a maximum improvement of 3.4\% in KV-Retrieval tasks.