LLM Rationalis? Measuring Bargaining Capabilities of AI Negotiators
作者: Cheril Shah, Akshit Agarwal, Kanak Garg, Mourad Heddaya
分类: cs.CL, cs.AI
发布日期: 2025-12-15
备注: Published in the First Workshop on Multi-Turn Interactions in Large Language Models at Neurips 2025
💡 一句话要点
提出统一数学框架以量化AI谈判能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 双边谈判 AI谈判能力 让步动态 突发性指标 让步刚性指数 大型语言模型 策略推理 权力不对称
📋 核心要点
- 现有的AI谈判模型在动态适应和推断对手策略方面表现不佳,无法有效应对复杂的谈判环境。
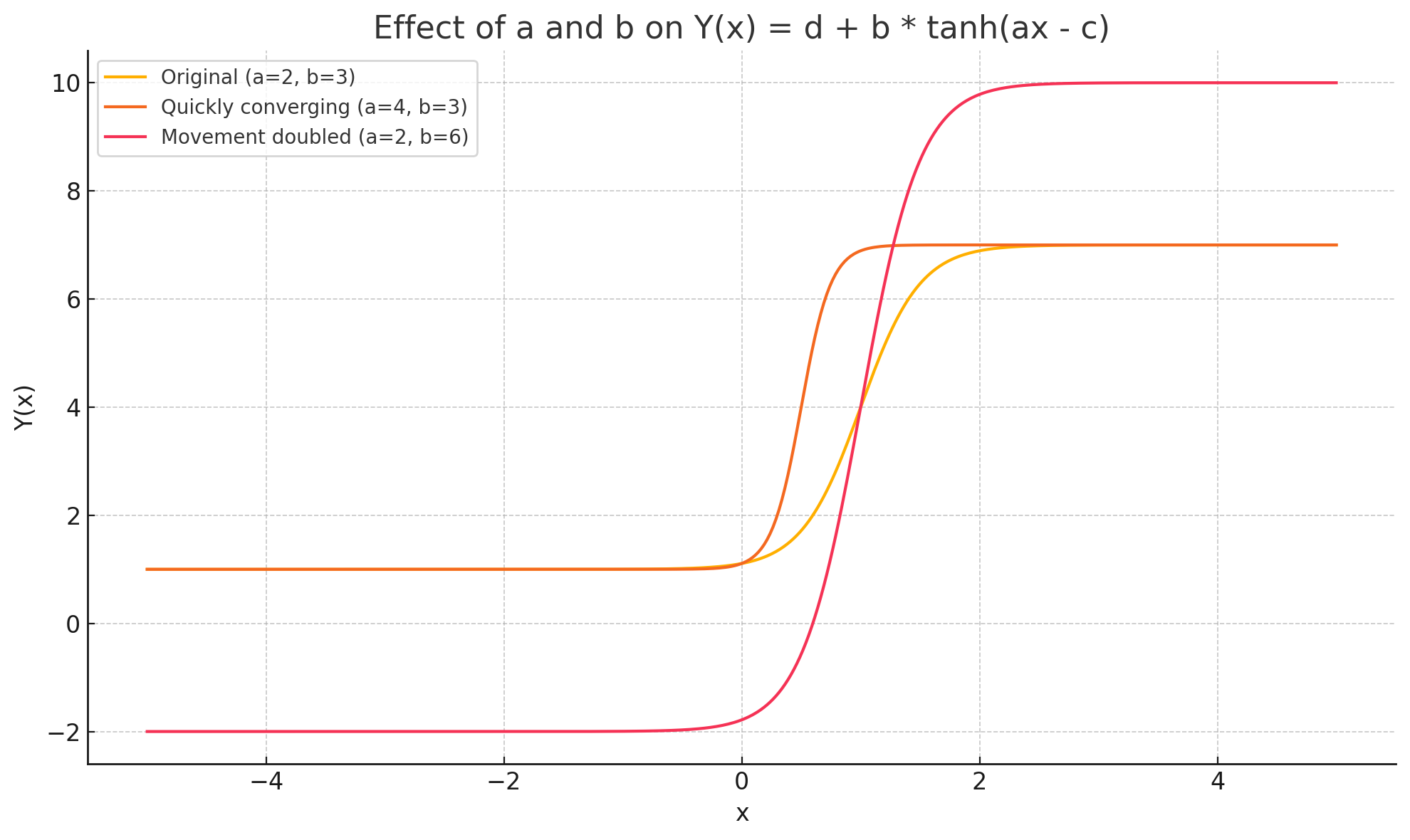
- 论文提出了一种基于双曲正切曲线的数学框架,结合突发性τ和让步刚性指数(CRI)来量化谈判过程中的让步动态。
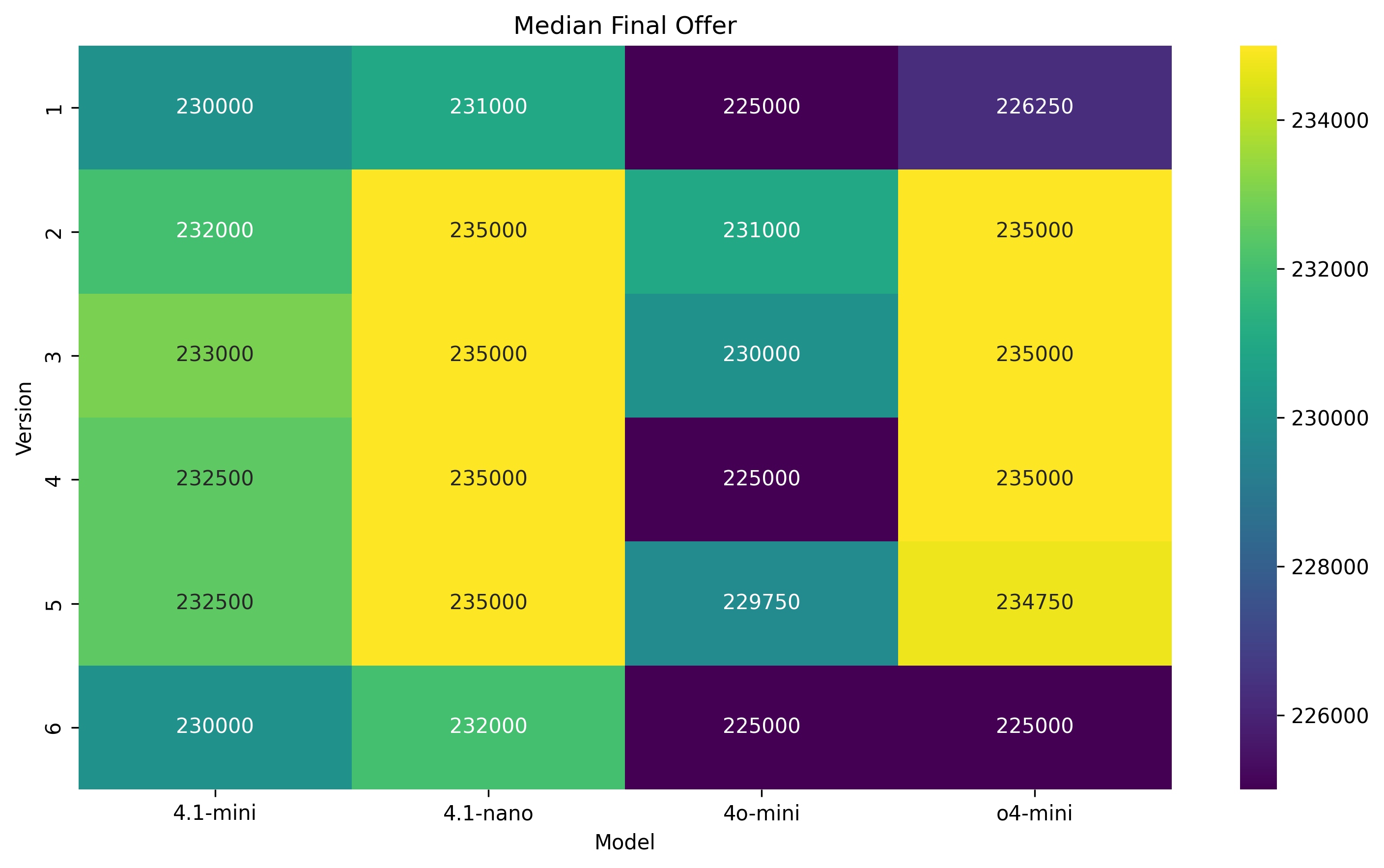
- 实验结果表明,LLMs在谈判中表现出系统性的极端锚定,缺乏策略多样性,且其谈判能力未随模型改进而提升。
📝 摘要(中文)
双边谈判是一项复杂且敏感于上下文的任务,涉及人类谈判者动态调整锚点、节奏和灵活性,以利用权力不对称和非正式线索。本文引入了一种基于双曲正切曲线的统一数学框架来建模让步动态,并提出了两个指标:突发性τ和让步刚性指数(CRI),以量化报价轨迹的时机和刚性。通过大规模实证比较人类谈判者与四种先进的大型语言模型(LLMs),结果显示LLMs在谈判中系统性地锚定在可能协议区的极端位置,缺乏灵活性和策略多样性,且其谈判能力并未随着模型的改进而提升。这些发现突显了当前LLMs谈判能力的基本局限性,并指出需要更好地内化对手推理和上下文依赖策略的模型。
🔬 方法详解
问题定义:本文旨在解决AI在双边谈判中的能力不足,尤其是在动态适应和推断对手策略方面的挑战。现有方法往往无法有效应对复杂的谈判环境,导致谈判效果不理想。
核心思路:论文提出了一种新的数学框架,利用双曲正切曲线来建模让步动态,并引入突发性τ和让步刚性指数(CRI)作为量化指标,以更好地理解和评估谈判过程中的让步行为。
技术框架:整体架构包括数据收集、模型训练和评估三个主要阶段。首先,通过实证数据收集人类和LLMs的谈判行为,然后训练模型以适应不同的谈判场景,最后通过量化指标评估其表现。
关键创新:最重要的技术创新在于引入了突发性τ和让步刚性指数(CRI),这两个指标能够有效量化谈判中的让步动态,提供了对比人类和LLMs谈判能力的新视角。
关键设计:在模型设计中,采用了双曲正切曲线来描述让步轨迹,并通过实验设置不同的权力不对称场景,以观察LLMs在不同条件下的表现。
🖼️ 关键图片
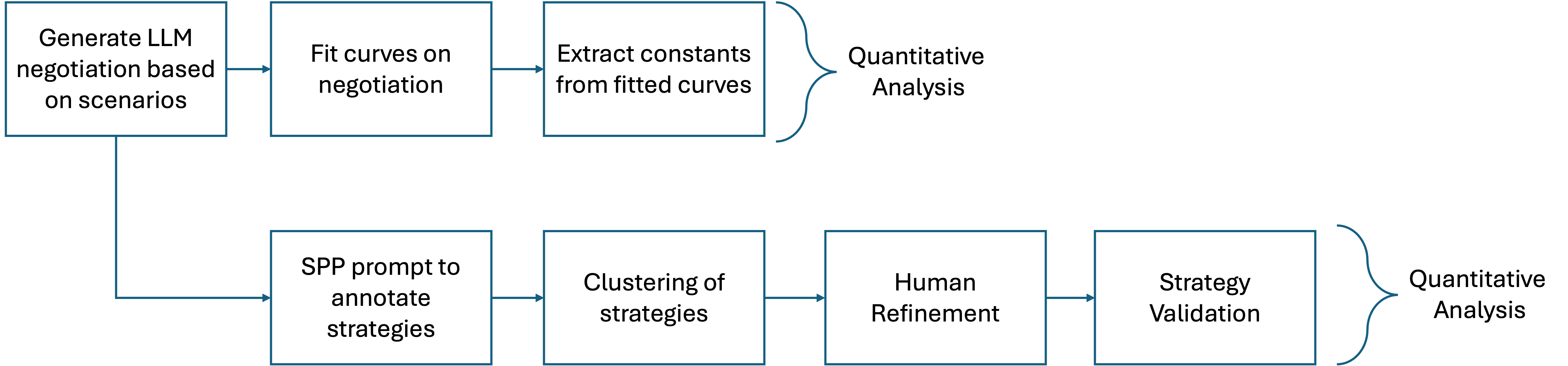
📊 实验亮点
实验结果显示,与人类谈判者相比,LLMs在谈判中表现出明显的极端锚定,缺乏灵活性和策略多样性。尽管进行了大规模比较,LLMs的谈判能力并未随着模型的改进而提升,突显了其在动态适应能力上的局限性。
🎯 应用场景
该研究的潜在应用领域包括商业谈判、自动化客服和人机交互等场景。通过改进AI的谈判能力,可以提升自动化系统在复杂环境中的决策质量,进而提高用户体验和满意度。未来,研究成果可能推动更智能的谈判代理的开发,使其能够更好地理解和适应人类谈判者的策略。
📄 摘要(原文)
Bilateral negotiation is a complex, context-sensitive task in which human negotiators dynamically adjust anchors, pacing, and flexibility to exploit power asymmetries and informal cues. We introduce a unified mathematical framework for modeling concession dynamics based on a hyperbolic tangent curve, and propose two metrics burstiness tau and the Concession-Rigidity Index (CRI) to quantify the timing and rigidity of offer trajectories. We conduct a large-scale empirical comparison between human negotiators and four state-of-the-art large language models (LLMs) across natural-language and numeric-offers settings, with and without rich market context, as well as six controlled power-asymmetry scenarios. Our results reveal that, unlike humans who smoothly adapt to situations and infer the opponents position and strategies, LLMs systematically anchor at extremes of the possible agreement zone for negotiations and optimize for fixed points irrespective of leverage or context. Qualitative analysis further shows limited strategy diversity and occasional deceptive tactics used by LLMs. Moreover the ability of LLMs to negotiate does not improve with better models. These findings highlight fundamental limitations in current LLM negotiation capabilities and point to the need for models that better internalize opponent reasoning and context-dependent strategy.