Building from Scratch: A Multi-Agent Framework with Human-in-the-Loop for Multilingual Legal Terminology Mapping
作者: Lingyi Meng, Maolin Liu, Hao Wang, Yilan Cheng, Qi Yang, Idlkaid Mohanmmed
分类: cs.CL, cs.AI
发布日期: 2025-12-15
备注: 43 pages, 6 fingures, accepted in Artificial Intelligence and Law (2025)
DOI: 10.1007/s10506-025-09490-6
💡 一句话要点
提出一种人机协作的多Agent框架,用于多语种法律术语映射,提升准确性和可扩展性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语种法律术语映射 人机协作 多Agent系统 法律人工智能 自然语言处理
📋 核心要点
- 现有跨语言法律术语映射方法在处理中日等语言时面临挑战,原因是同形异义词多且缺乏有效资源。
- 论文提出人机协作的多Agent框架,让人工智能Agent和法律专家协同完成术语提取和映射任务。
- 实验结果表明,该框架提高了多语种法律术语映射的精度和一致性,并具备良好的可扩展性。
📝 摘要(中文)
本文针对跨语言法律术语映射的挑战,尤其是在中日等同形异义词较多的语言对上,现有资源和工具的局限性问题,提出了一种基于多Agent框架的人工智能协作方法,用于构建多语种法律术语数据库。该方法将先进的大型语言模型和法律领域专家整合到整个流程中,包括原始文档预处理、文章级对齐、术语提取、映射和质量保证。与单一的自动化流程不同,该方法更强调人类专家在多Agent系统中的参与。人工智能Agent处理特定的、重复性的任务,如OCR、文本分割、语义对齐和初始术语提取,而人类专家提供关键的监督、审查,并利用上下文知识和法律判断来监督输出。我们使用包含35个关键中文法规及其英文和日文翻译的三语平行语料库测试了该框架的有效性。实验结果表明,这种人机协作的多Agent工作流程不仅提高了多语种法律术语映射的精度和一致性,而且与传统的手动方法相比,提供了更大的可扩展性。
🔬 方法详解
问题定义:论文旨在解决多语种法律术语映射的难题,特别是针对中文和日文等存在大量同形异义词的语言。现有方法,包括完全自动化的流程和传统的手动方法,在精度、一致性和可扩展性方面存在不足。自动化流程缺乏领域知识和人工干预,容易产生错误;手动方法效率低下,难以处理大规模语料库。
核心思路:论文的核心思路是构建一个人机协作的多Agent框架,将大型语言模型(LLM)的自动化处理能力与法律领域专家的专业知识相结合。通过明确分工,让人工智能Agent负责重复性任务,人类专家负责监督、审查和提供法律判断,从而提高映射的准确性和效率。
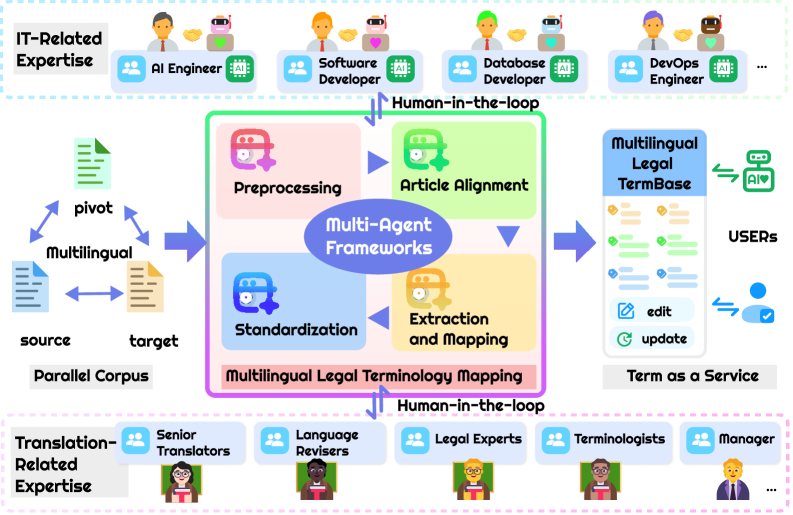
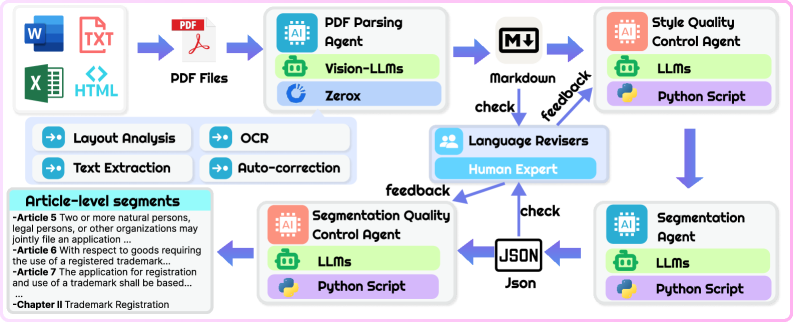
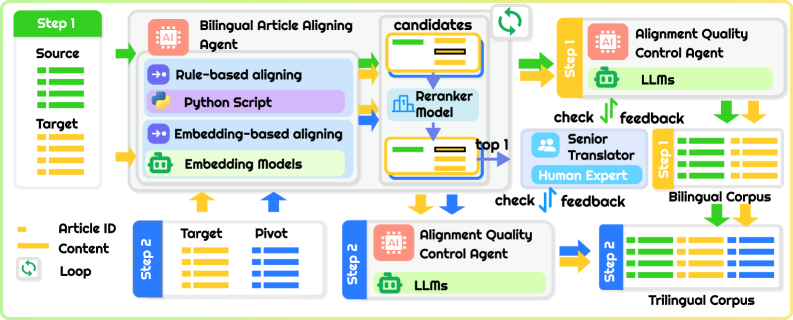
技术框架:该框架包含以下主要模块/阶段:1) 原始文档预处理(OCR、文本分割);2) 文章级对齐;3) 术语提取(人工智能Agent初步提取);4) 术语映射(人工智能Agent进行初步映射);5) 质量保证(法律专家审查和修正);6) 数据库构建。人工智能Agent和人类专家在各个阶段协同工作,形成一个闭环反馈系统。
关键创新:该方法最重要的创新点在于其人机协作的模式,强调人类专家在整个流程中的关键作用。与传统的自动化流程相比,该方法能够更好地利用领域知识和上下文信息,从而提高映射的准确性和一致性。此外,多Agent框架的设计使得任务可以并行处理,提高了效率和可扩展性。
关键设计:论文中未明确提及关键的参数设置、损失函数、网络结构等技术细节。但可以推断,大型语言模型的选择和微调、术语提取算法的优化、以及人机交互界面的设计是关键的技术细节。具体的损失函数和网络结构取决于所使用的大型语言模型和术语提取算法,这些细节在论文中没有详细描述,属于未知信息。
🖼️ 关键图片
📊 实验亮点
该研究使用包含35个关键中文法规及其英文和日文翻译的三语平行语料库进行实验,验证了人机协作的多Agent框架的有效性。实验结果表明,该框架能够提高多语种法律术语映射的精度和一致性,并具备良好的可扩展性。具体的性能数据和对比基线在摘要中没有明确给出,属于未知信息。
🎯 应用场景
该研究成果可应用于构建多语种法律术语数据库,为跨国法律研究、国际贸易、法律翻译等领域提供支持。通过提高法律术语映射的准确性和效率,有助于促进国际法律交流与合作,降低法律风险,并为法律人工智能的发展奠定基础。
📄 摘要(原文)
Accurately mapping legal terminology across languages remains a significant challenge, especially for language pairs like Chinese and Japanese, which share a large number of homographs with different meanings. Existing resources and standardized tools for these languages are limited. To address this, we propose a human-AI collaborative approach for building a multilingual legal terminology database, based on a multi-agent framework. This approach integrates advanced large language models and legal domain experts throughout the entire process-from raw document preprocessing, article-level alignment, to terminology extraction, mapping, and quality assurance. Unlike a single automated pipeline, our approach places greater emphasis on how human experts participate in this multi-agent system. Humans and AI agents take on different roles: AI agents handle specific, repetitive tasks, such as OCR, text segmentation, semantic alignment, and initial terminology extraction, while human experts provide crucial oversight, review, and supervise the outputs with contextual knowledge and legal judgment. We tested the effectiveness of this framework using a trilingual parallel corpus comprising 35 key Chinese statutes, along with their English and Japanese translations. The experimental results show that this human-in-the-loop, multi-agent workflow not only improves the precision and consistency of multilingual legal terminology mapping but also offers greater scalability compared to traditional manual methods.