DeliberationBench: When Do More Voices Hurt? A Controlled Study of Multi-LLM Deliberation Protocols
作者: Vaarunay Kaushal, Taranveer Singh
分类: cs.CL, cs.AI
发布日期: 2025-12-14
备注: 6 pages, 5 figures
💡 一句话要点
DeliberationBench揭示多LLM协商一致协议效果不佳,优于单模型最佳选择的假设被证伪
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多智能体系统 大型语言模型 协商协议 基准测试 性能评估
📋 核心要点
- 现有方法依赖多LLM协商以期提高性能,但缺乏与简单方法的有效对比。
- 论文提出DELIBERATIONBENCH基准,系统评估多种协商协议与单模型最佳选择的性能。
- 实验结果表明,最佳单模型选择显著优于多LLM协商,且计算成本更低。
📝 摘要(中文)
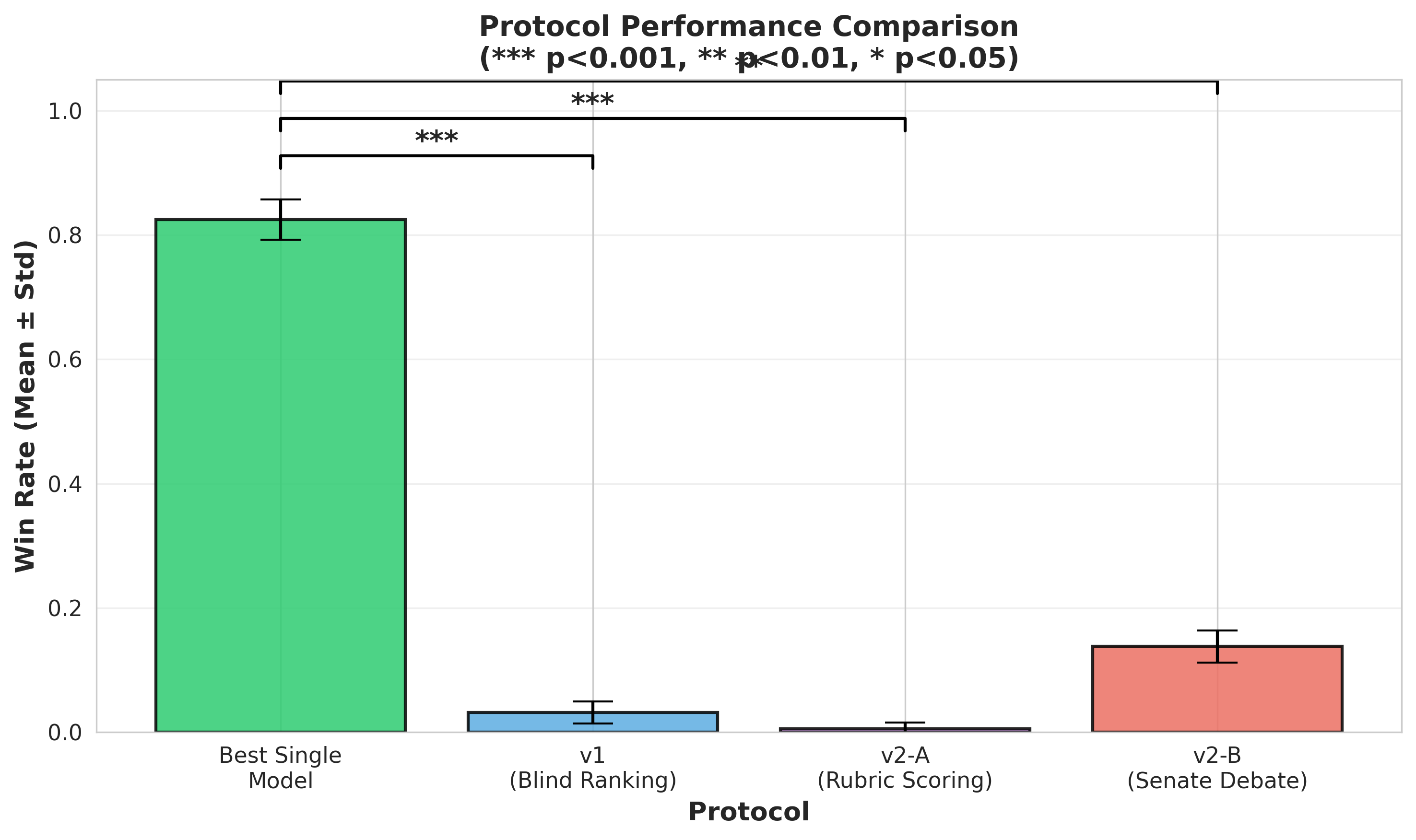
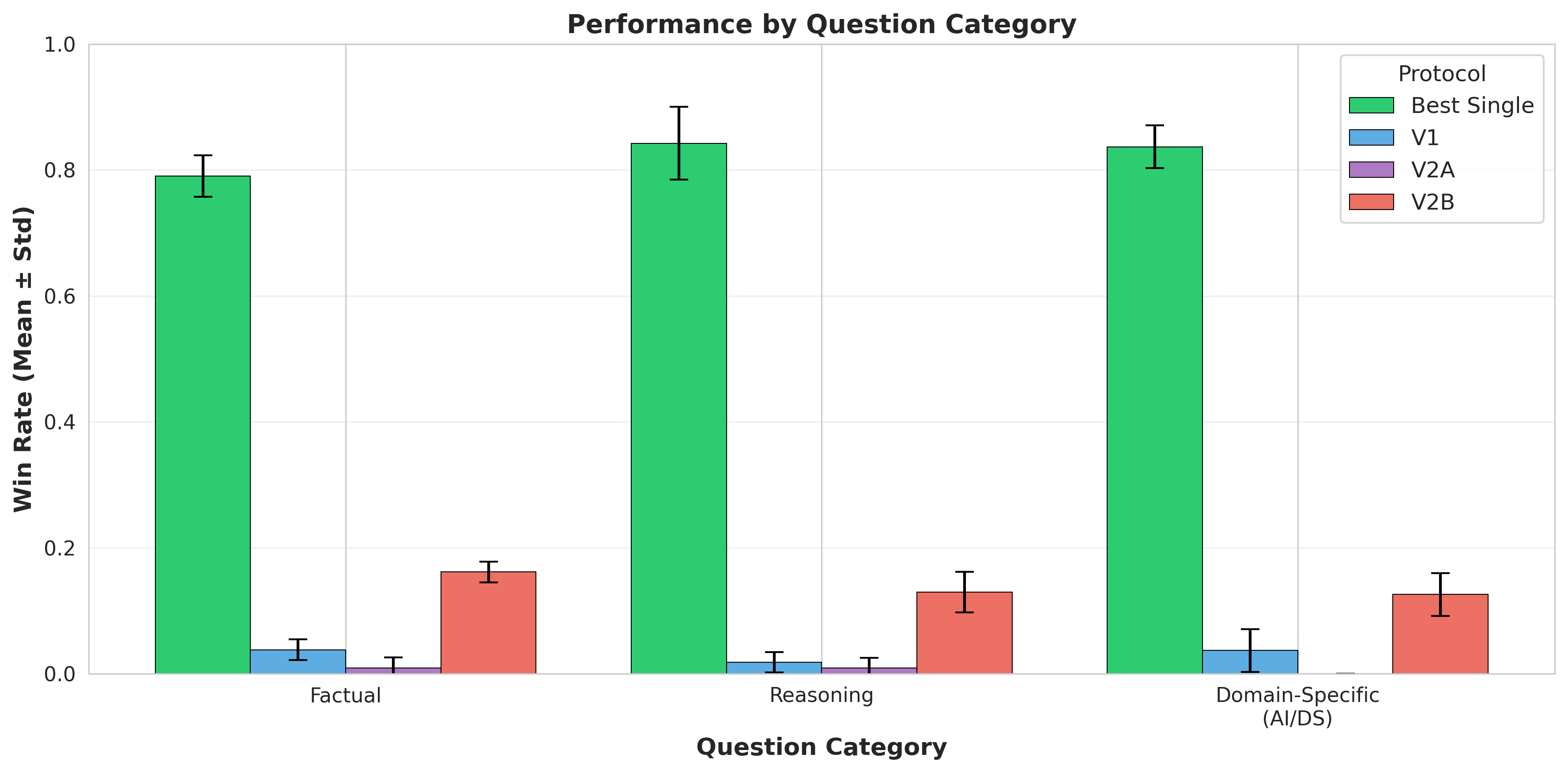
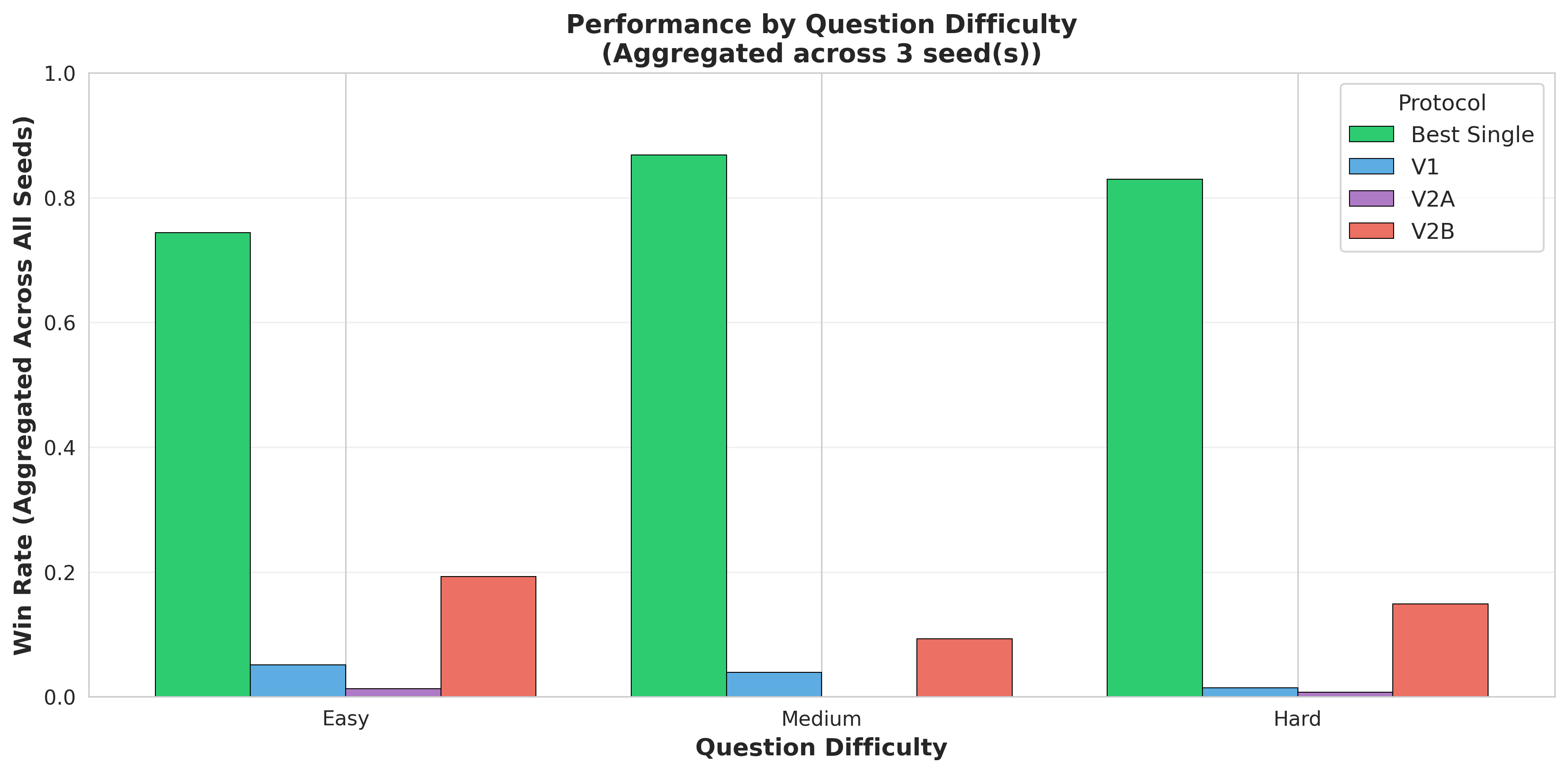
多智能体系统利用大型语言模型(LLM)进行协商以达成共识,受到了广泛关注,但其相对于更简单方法的实际价值仍缺乏充分审查。我们引入了DELIBERATIONBENCH,这是一个受控的基准,用于评估三种协商协议,并与从模型输出池中选择最佳响应的强大基线进行比较。在270个问题和三个独立种子(总共810次评估)中,我们发现了一个惊人的负面结果:最佳单模型基线实现了82.5% +- 3.3%的胜率,显著优于最佳协商协议(13.8% +- 2.6%)。这种6.0倍的性能差距具有统计学意义(p < 0.01),并且计算成本高出1.5-2.5倍。我们的发现挑战了多LLM系统中复杂性可以提高质量的假设。
🔬 方法详解
问题定义:现有研究倾向于认为多LLM协商能够提升性能,但缺乏充分的实验验证,尤其是在与简单的单模型选择策略进行对比时。现有的多LLM协商方法的有效性以及计算成本收益并不明确。
核心思路:论文的核心思路是通过构建一个受控的基准测试环境,系统地比较不同的多LLM协商协议与单模型最佳选择策略的性能。通过大量实验数据,验证多LLM协商是否真的优于简单的单模型选择,并评估其计算成本。
技术框架:DELIBERATIONBENCH基准测试框架包含以下几个主要组成部分:1) 问题集:包含270个问题,用于评估不同方法的性能。2) 多LLM协商协议:实现了三种不同的协商协议,用于进行对比实验。3) 单模型最佳选择基线:从多个模型输出中选择最佳的响应作为基线。4) 评估指标:使用胜率作为评估指标,比较不同方法之间的性能差异。实验设置了三个独立的随机种子,以保证结果的可靠性。
关键创新:该论文的关键创新在于:1) 构建了一个受控的基准测试环境DELIBERATIONBENCH,用于系统地评估多LLM协商协议的性能。2) 实验结果表明,在所测试的场景下,多LLM协商协议的性能不如单模型最佳选择策略,挑战了现有研究的假设。
关键设计:论文的关键设计包括:1) 选择了三种具有代表性的多LLM协商协议进行评估。2) 使用胜率作为评估指标,能够直观地反映不同方法之间的性能差异。3) 进行了大量的实验,并使用了多个随机种子,以保证结果的可靠性。没有提供关于参数设置、损失函数或网络结构的具体细节,因为该研究主要关注的是不同协商策略的比较,而不是特定模型的优化。
🖼️ 关键图片
📊 实验亮点
实验结果显示,最佳单模型基线实现了82.5% +- 3.3%的胜率,而最佳协商协议仅为13.8% +- 2.6%。单模型基线的性能是最佳协商协议的6.0倍,且具有统计学意义(p < 0.01)。此外,多LLM协商协议的计算成本高出1.5-2.5倍。
🎯 应用场景
该研究成果可应用于LLM应用开发,指导开发者在多智能体系统设计中谨慎选择协商策略,避免盲目追求复杂性。研究结果表明,在某些场景下,简单的单模型选择策略可能更有效且成本更低。未来可进一步研究哪些因素影响多LLM协商的有效性,以及如何设计更有效的协商协议。
📄 摘要(原文)
Multi-agent systems where Large Language Models (LLMs) deliberate to form consensus have gained significant attention, yet their practical value over simpler methods remains under-scrutinized. We introduce DELIBERATIONBENCH, a controlled benchmark evaluating three deliberation protocols against a strong baseline of selecting the best response from a pool of model outputs. Across 270 questions and three independent seeds (810 total evaluations), we find a striking negative result: the best-single baseline achieves an 82.5% +- 3.3% win rate, dramatically outperforming the best deliberation protocol(13.8% +- 2.6%). This 6.0x performance gap is statistically significant (p < 0.01) and comes at 1.5-2.5x higher computational cost. Our findings challenge assumptions that complexity enhances quality in multi-LLM systems.