Auto-Tuning Safety Guardrails for Black-Box Large Language Models
作者: Perry Abdulkadir
分类: cs.CR, cs.CL, cs.LG
发布日期: 2025-12-14
备注: 8 pages, 7 figures, 1 table. Work completed as part of the M.S. in Artificial Intelligence at the University of St. Thomas using publicly available models and datasets; all views and any errors are the author's own
💡 一句话要点
针对黑盒大语言模型,提出基于超参数优化的安全护栏自动调优方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 安全护栏 超参数优化 黑盒优化 Optuna
📋 核心要点
- 现有大语言模型安全护栏依赖手工调整,存在脆弱性且难以复现的问题。
- 将安全护栏设计视为超参数优化问题,在冻结的基础模型上进行自动调优。
- 实验表明,该方法能显著减少评估次数和时间,同时重新发现最佳配置。
📝 摘要(中文)
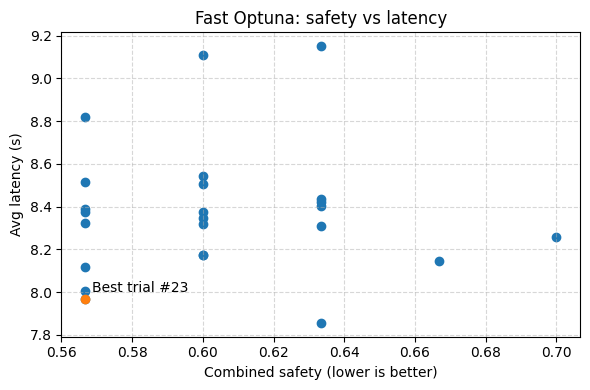
大型语言模型(LLM)越来越多地部署在安全护栏之后,例如系统提示和内容过滤器,尤其是在产品团队无法修改模型权重的情况下。实际上,这些护栏通常是手工调整的,脆弱且难以重现。本文研究了一种简单但实用的替代方案:将安全护栏设计本身视为冻结基础模型上的超参数优化问题。具体而言,我将Mistral-7B-Instruct与模块化的越狱和恶意软件系统提示以及基于ModernBERT的有害性分类器封装在一起,然后在涵盖恶意软件生成、经典越狱提示和良性用户查询的三个公共基准上评估候选配置。使用恶意软件和越狱攻击成功率、良性有害响应率以及端到端延迟对每个配置进行评分。对提示组合和过滤器模式进行48点网格搜索以建立基线。然后,我在同一空间上运行黑盒Optuna研究,并表明它可以可靠地重新发现最佳网格配置,同时需要的评估次数减少一个数量级,并且挂钟时间减少大约8倍。结果表明,将安全护栏视为可调超参数是在计算和时间约束下加强黑盒LLM部署的可行方法。
🔬 方法详解
问题定义:论文旨在解决黑盒大语言模型安全护栏的手工调优问题。现有方法依赖人工经验,难以找到最优配置,且缺乏可重复性,导致安全防护效果不稳定。此外,针对LLM的攻击方式不断演进,手工调整难以快速适应新的威胁。
核心思路:论文的核心思路是将安全护栏的设计过程转化为一个超参数优化问题。通过将系统提示、内容过滤器等安全组件视为可调节的超参数,利用优化算法自动搜索最佳配置,从而提高安全护栏的有效性和鲁棒性。这种方法无需修改模型权重,适用于无法直接访问模型参数的场景。
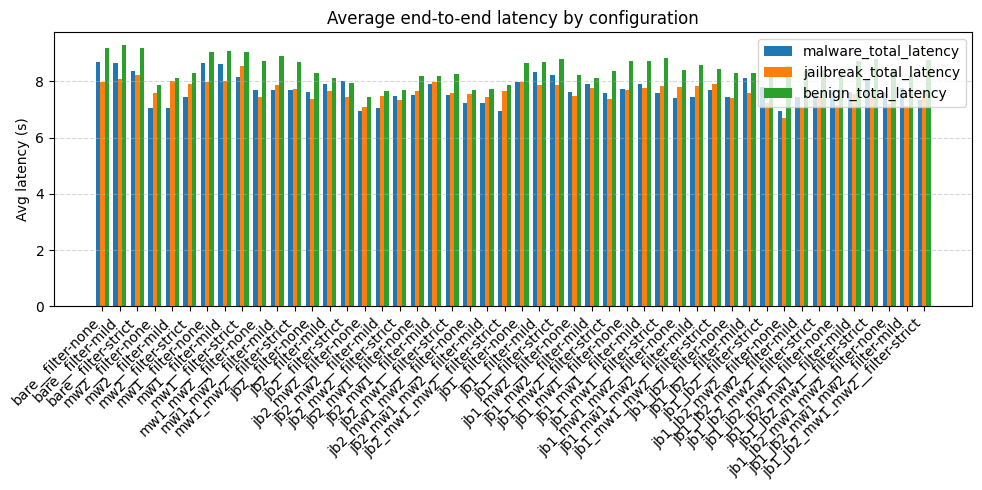
技术框架:该方法的技术框架主要包括以下几个模块:1) 基础LLM:使用预训练的黑盒LLM,例如Mistral-7B-Instruct。2) 安全护栏组件:包括越狱和恶意软件系统提示、有害性分类器等。3) 评估指标:包括恶意软件和越狱攻击成功率、良性有害响应率以及端到端延迟。4) 优化算法:使用黑盒优化算法(如Optuna)在超参数空间中搜索最佳配置。
关键创新:该方法最重要的创新点在于将安全护栏设计问题转化为超参数优化问题,并采用黑盒优化算法进行自动调优。与传统的手工调整方法相比,该方法能够更高效地搜索最佳配置,提高安全护栏的性能和鲁棒性。此外,该方法具有较强的通用性,可以应用于不同的LLM和安全护栏组件。
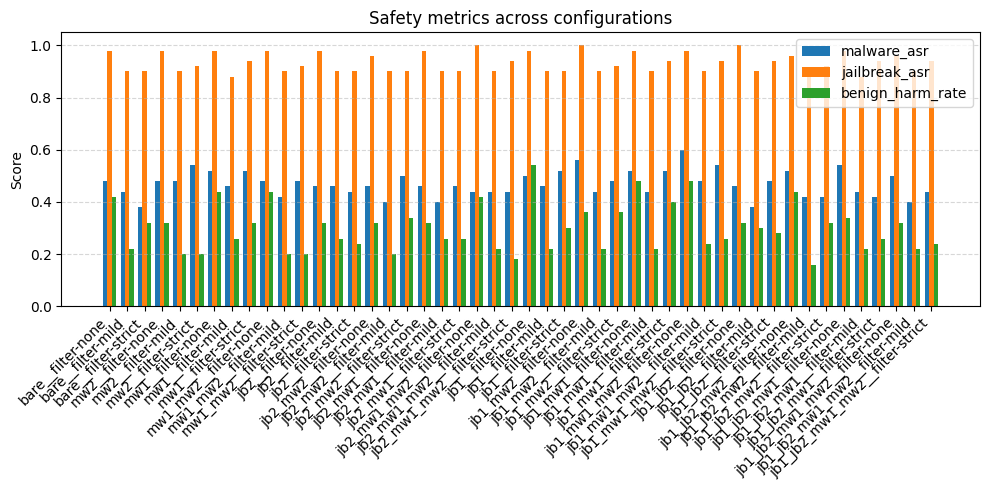
关键设计:论文的关键设计包括:1) 超参数空间的设计:定义了系统提示、内容过滤器等安全组件的可调节参数范围。2) 评估指标的选择:选择了能够全面衡量安全护栏性能的指标,包括攻击成功率、有害响应率和延迟。3) 优化算法的选择:选择了适用于黑盒优化的Optuna算法,并进行了参数调优。4) 实验设置:设计了涵盖恶意软件生成、经典越狱提示和良性用户查询的三个公共基准,以评估不同配置的性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,使用Optuna进行黑盒优化能够可靠地重新发现最佳网格配置,同时需要的评估次数减少一个数量级,并且挂钟时间减少大约8倍。这意味着在计算和时间资源有限的情况下,该方法能够更高效地找到最佳的安全护栏配置,从而提高LLM的安全性。
🎯 应用场景
该研究成果可广泛应用于各种需要部署安全护栏的大语言模型应用场景,例如聊天机器人、智能助手、内容生成平台等。通过自动调优安全护栏,可以有效提高LLM的安全性,降低恶意攻击和有害内容输出的风险,从而提升用户体验和平台的可靠性。该方法尤其适用于无法直接修改模型权重的黑盒LLM部署场景。
📄 摘要(原文)
Large language models (LLMs) are increasingly deployed behind safety guardrails such as system prompts and content filters, especially in settings where product teams cannot modify model weights. In practice these guardrails are typically hand-tuned, brittle, and difficult to reproduce. This paper studies a simple but practical alternative: treat safety guardrail design itself as a hyperparameter optimization problem over a frozen base model. Concretely, I wrap Mistral-7B-Instruct with modular jailbreak and malware system prompts plus a ModernBERT-based harmfulness classifier, then evaluate candidate configurations on three public benchmarks covering malware generation, classic jailbreak prompts, and benign user queries. Each configuration is scored using malware and jailbreak attack success rate, benign harmful-response rate, and end-to-end latency. A 48-point grid search over prompt combinations and filter modes establishes a baseline. I then run a black-box Optuna study over the same space and show that it reliably rediscovers the best grid configurations while requiring an order of magnitude fewer evaluations and roughly 8x less wall-clock time. The results suggest that viewing safety guardrails as tunable hyperparameters is a feasible way to harden black-box LLM deployments under compute and time constraints.