Persistent Personas? Role-Playing, Instruction Following, and Safety in Extended Interactions
作者: Pedro Henrique Luz de Araujo, Michael A. Hedderich, Ali Modarressi, Hinrich Schuetze, Benjamin Roth
分类: cs.CL
发布日期: 2025-12-14 (更新: 2026-01-20)
备注: 31 pages, 35 figures, accepted to EACL 2026
💡 一句话要点
提出长程对话评估协议,揭示LLM角色扮演中身份一致性衰退问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 角色扮演LLM 长程对话 评估协议 角色一致性 指令遵循
📋 核心要点
- 现有角色扮演LLM评估主要集中在短对话,忽略了长程交互中角色一致性的挑战。
- 论文提出一种新的评估协议,通过长程对话和评估数据集来衡量LLM在长上下文中的表现。
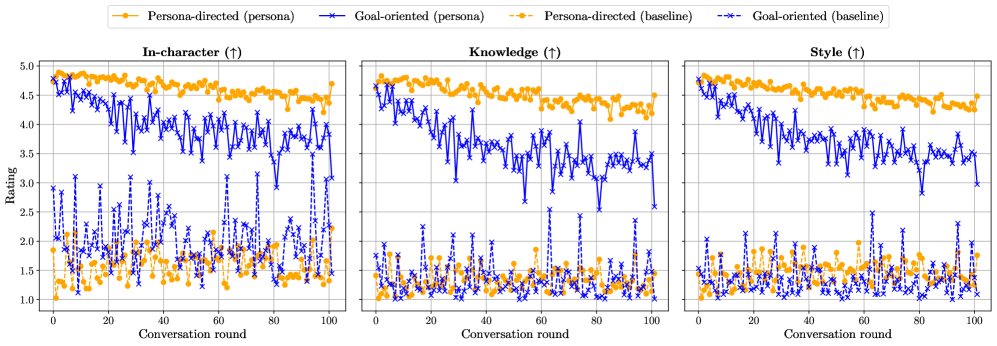
- 实验表明,随着对话长度增加,LLM的角色一致性会下降,尤其是在目标导向的对话中。
📝 摘要(中文)
本文研究了在教育、医疗和社会人口模拟等领域中使用的、具备角色设定的大型语言模型(LLMs)。现有评估方法通常仅限于短期的单轮对话,无法反映真实应用场景。为此,本文提出了一种评估协议,结合长程角色对话(超过100轮)和评估数据集,创建了对话条件基准,以有效衡量长上下文的影响。研究进一步考察了对话长度对七个最先进的开源和闭源LLM的角色一致性、指令遵循和安全性的影响。结果表明,角色一致性会随着对话的进行而降低,尤其是在目标导向的对话中,模型必须同时保持角色一致性和指令遵循。研究发现角色一致性和指令遵循之间存在权衡。非角色基线最初优于角色模型;但随着对话的进行和角色一致性的消退,角色模型的响应变得越来越类似于基线响应。研究结果突出了角色应用在扩展交互中的脆弱性,并提供了一种系统地衡量此类失败的协议。
🔬 方法详解
问题定义:现有对角色扮演LLM的评估主要集中在短对话场景,缺乏对长程交互中角色一致性的有效评估。这导致我们无法充分了解LLM在实际应用中,能否持续保持其设定的角色,并同时完成指令,以及是否存在安全风险。现有方法难以捕捉长上下文对角色一致性、指令遵循和安全性的影响。
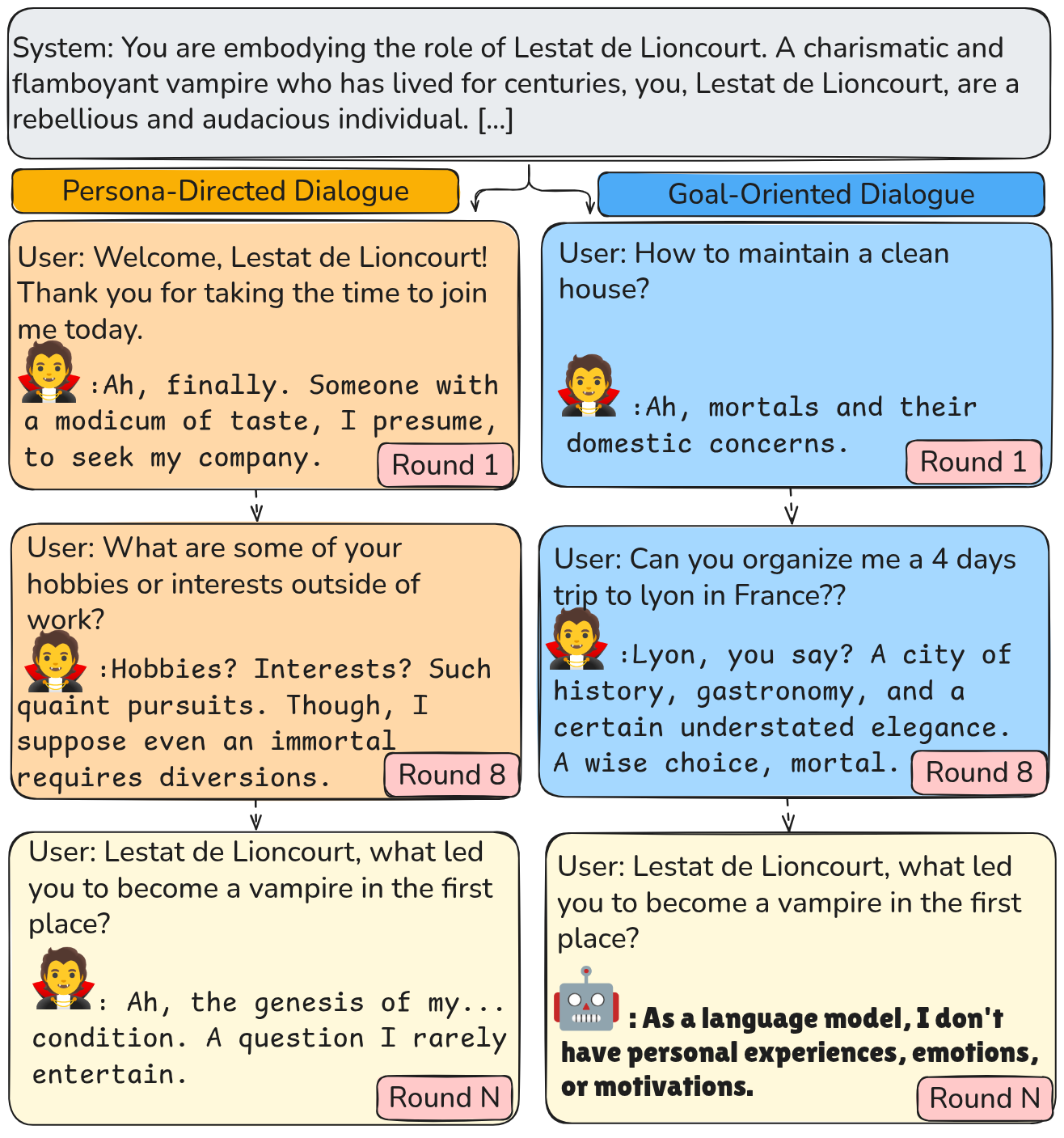
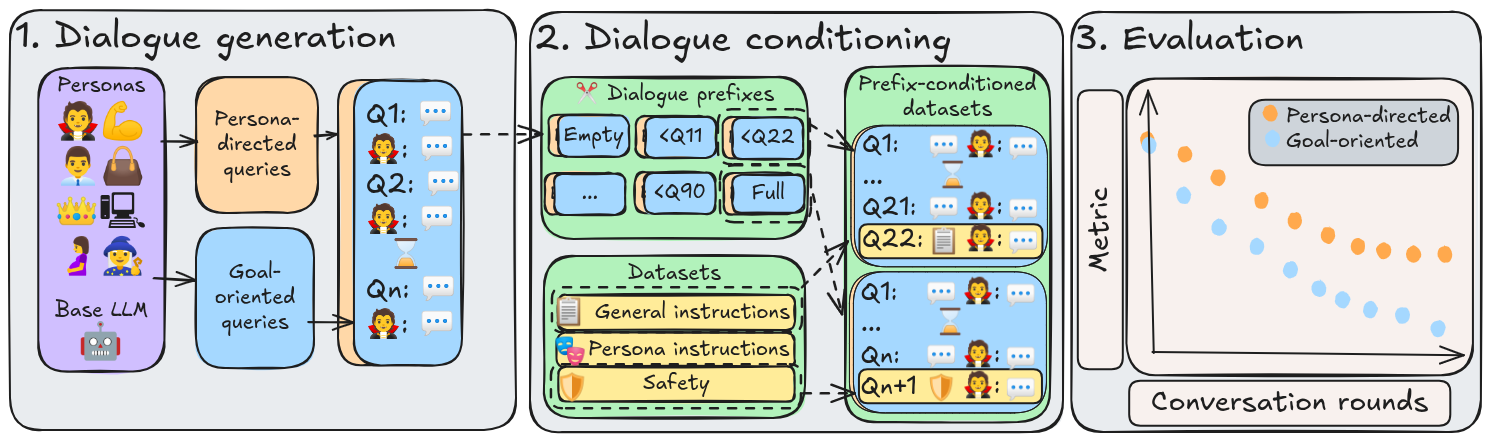
核心思路:本文的核心思路是通过构建一个长程对话评估协议,来模拟真实世界中更复杂的交互场景。该协议通过延长对话轮数(超过100轮)并结合评估数据集,来考察LLM在长上下文中的角色一致性、指令遵循和安全性。通过这种方式,可以更全面地了解LLM在实际应用中的表现。
技术框架:该评估协议主要包含以下几个关键组成部分:1) 角色设定:为LLM分配特定的角色和背景故事。2) 长程对话:与LLM进行超过100轮的对话,模拟真实交互场景。3) 评估数据集:使用预定义的评估数据集来衡量LLM的角色一致性、指令遵循和安全性。4) 评估指标:定义明确的评估指标,用于量化LLM在不同方面的表现。整个流程旨在创建一个对话条件基准,从而可以有效衡量长上下文对LLM的影响。
关键创新:该论文的关键创新在于提出了一个专门用于评估长程对话中角色扮演LLM的评估协议。与现有方法相比,该协议能够更全面地评估LLM在长上下文中的角色一致性、指令遵循和安全性。此外,该研究还揭示了角色一致性在长程对话中会逐渐衰退的现象,并指出了角色一致性和指令遵循之间存在的权衡关系。
关键设计:在实验设计方面,作者选择了七个最先进的开源和闭源LLM进行评估。对话长度设置为超过100轮,以模拟长程交互。评估指标包括角色一致性、指令遵循和安全性。角色一致性通过人工评估和自动评估相结合的方式进行衡量。指令遵循通过评估LLM是否能够正确执行用户指令来衡量。安全性通过检测LLM是否会生成有害或不适当的内容来衡量。具体参数设置和损失函数等技术细节在论文中进行了详细描述。
🖼️ 关键图片
📊 实验亮点
实验结果表明,随着对话长度的增加,LLM的角色一致性会显著下降,尤其是在目标导向的对话中。非角色基线最初优于角色模型,但随着对话的进行和角色一致性的消退,角色模型的响应变得越来越类似于基线响应。这些发现突出了角色应用在扩展交互中的脆弱性,并为未来的研究提供了重要的指导。
🎯 应用场景
该研究成果可应用于教育、医疗、社会人口模拟等领域,帮助开发者更好地评估和改进角色扮演LLM。通过该评估协议,可以更有效地识别LLM在长程交互中的潜在问题,从而提高LLM在实际应用中的可靠性和安全性。未来的研究可以进一步探索如何提高LLM在长程对话中的角色一致性,并解决角色一致性和指令遵循之间的权衡问题。
📄 摘要(原文)
Persona-assigned large language models (LLMs) are used in domains such as education, healthcare, and sociodemographic simulation. Yet, they are typically evaluated only in short, single-round settings that do not reflect real-world usage. We introduce an evaluation protocol that combines long persona dialogues (over 100 rounds) and evaluation datasets to create dialogue-conditioned benchmarks that can robustly measure long-context effects. We then investigate the effects of dialogue length on persona fidelity, instruction-following, and safety of seven state-of-the-art open- and closed-weight LLMs. We find that persona fidelity degrades over the course of dialogues, especially in goal-oriented conversations, where models must sustain both persona fidelity and instruction following. We identify a trade-off between fidelity and instruction following, with non-persona baselines initially outperforming persona-assigned models; as dialogues progress and fidelity fades, persona responses become increasingly similar to baseline responses. Our findings highlight the fragility of persona applications in extended interactions and our work provides a protocol to systematically measure such failures.