CoDA: A Context-Decoupled Hierarchical Agent with Reinforcement Learning
作者: Xuanzhang Liu, Jianglun Feng, Zhuoran Zhuang, Junzhe Zhao, Maofei Que, Jieting Li, Dianlei Wang, Hao Tong, Ye Chen, Pan Li
分类: cs.CL
发布日期: 2025-12-14
备注: Accepted to WSDM '26 Oral
💡 一句话要点
提出CoDA:一种解耦上下文的分层强化学习Agent,解决LLM Agent中的上下文爆炸问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM Agent 强化学习 上下文爆炸 分层Agent 多跳问答 长上下文 PECO 上下文解耦
📋 核心要点
- 现有LLM Agent在处理复杂任务时,因上下文窗口限制,易出现“上下文爆炸”问题,导致推理失败。
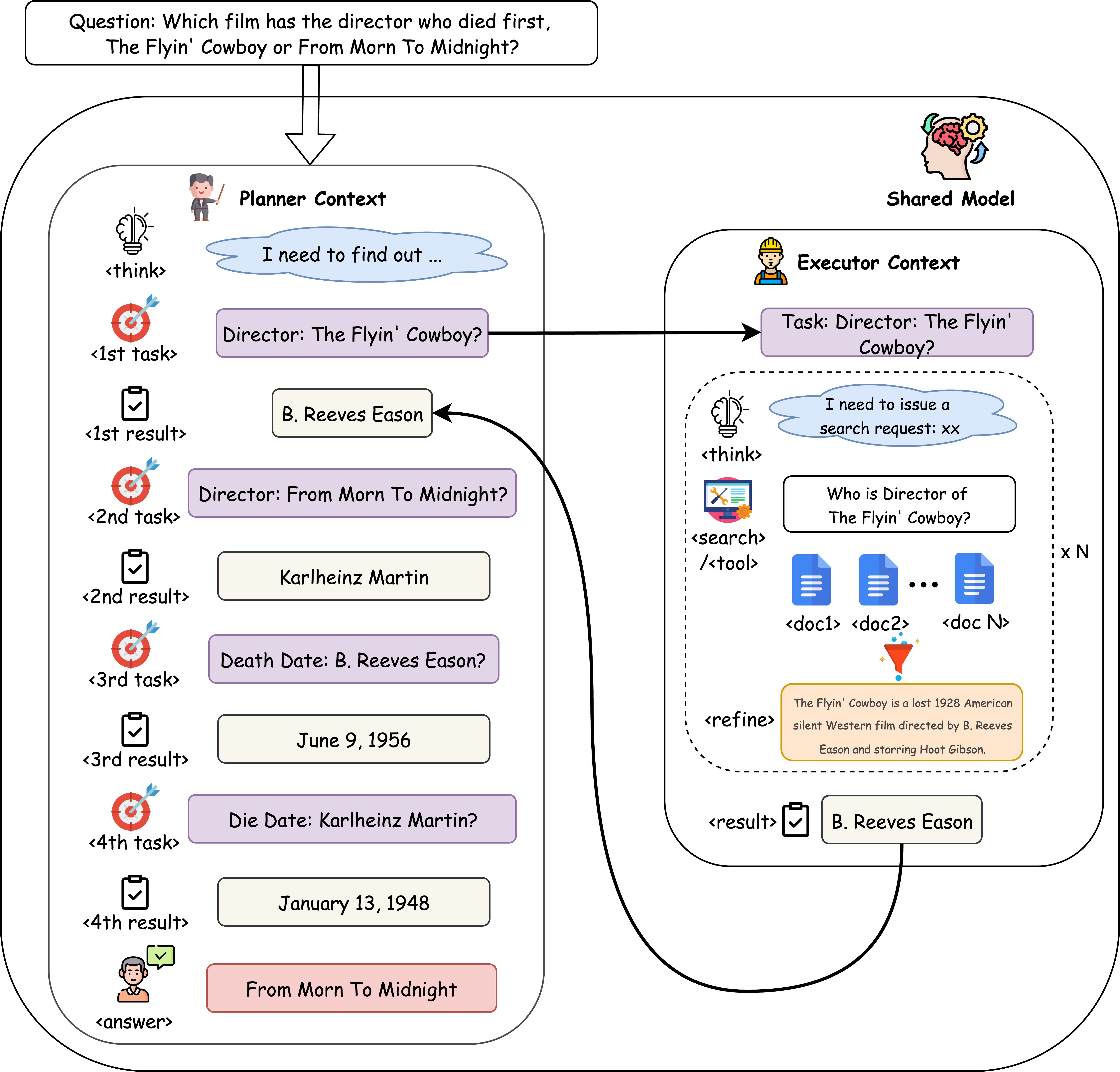
- CoDA通过解耦高层规划和低层执行,利用单一LLM在不同上下文中扮演规划器和执行器角色,缓解上下文压力。
- 实验表明,CoDA在多跳问答任务中超越现有方法,并在长上下文场景下保持稳定性能,验证了其有效性。
📝 摘要(中文)
本文提出了一种上下文解耦的分层Agent框架CoDA,旨在解决大型语言模型(LLM) Agent在复杂多步任务中因长文本输出导致的“上下文爆炸”问题。CoDA采用单一共享的LLM作为骨干网络,通过强化学习使其在两种不同的、上下文隔离的角色中运作:高层规划器在简洁的战略上下文中分解任务,低层执行器在短暂隔离的工作空间中处理工具交互。我们使用PECO(规划器-执行器协同优化)训练这个统一的Agent,这是一种轨迹级别的强化学习方法,用于联合优化规划器和执行器,通过上下文相关的策略更新促进无缝协作。实验表明,CoDA在复杂的多跳问答基准测试中显著优于最先进的基线,并在长上下文场景中表现出强大的鲁棒性,在所有其他基线性能严重下降时保持稳定,进一步验证了分层设计在缓解上下文过载方面的有效性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)Agent在处理复杂、多步骤任务时遇到的“上下文爆炸”问题。随着任务的进行,LLM Agent生成的文本不断累积,最终超出模型的上下文窗口限制,导致推理能力下降甚至失败。现有的方法难以有效管理和控制LLM Agent的上下文长度,无法在长上下文场景下保持稳定性能。
核心思路:CoDA的核心思路是将任务分解为高层规划和低层执行两个阶段,并分别由LLM Agent扮演规划器和执行器的角色。规划器负责在简洁的战略上下文中进行任务分解和制定计划,而执行器则负责在短暂隔离的工作空间中执行具体的操作和工具交互。通过这种分层结构,可以有效控制每个阶段的上下文长度,避免上下文爆炸问题。
技术框架:CoDA采用一个共享的LLM作为骨干网络,通过强化学习训练使其能够胜任规划器和执行器两种角色。整体流程如下:首先,规划器接收任务描述,生成一系列子任务和操作计划;然后,执行器根据规划器的指令,执行相应的操作并与环境交互;最后,环境返回反馈信息,用于更新规划器和执行器的策略。整个过程通过PECO(Planner-Executor Co-Optimization)进行端到端训练,PECO是一种轨迹级别的强化学习方法,可以联合优化规划器和执行器的策略。
关键创新:CoDA的关键创新在于其上下文解耦的分层结构和PECO协同优化方法。通过将任务分解为规划和执行两个阶段,并分别在不同的上下文中进行,可以有效控制上下文长度,避免上下文爆炸问题。PECO方法则可以联合优化规划器和执行器的策略,使它们能够更好地协同工作,完成复杂任务。
关键设计:CoDA的关键设计包括:1) 使用单一共享的LLM作为骨干网络,减少参数量和训练成本;2) 设计简洁的战略上下文,用于指导规划器的任务分解;3) 创建短暂隔离的工作空间,用于执行器的工具交互;4) 使用轨迹级别的奖励函数,鼓励规划器和执行器之间的协同合作;5) 通过上下文相关的策略更新,使规划器和执行器能够根据当前上下文调整策略。
🖼️ 关键图片


📊 实验亮点
实验结果表明,CoDA在复杂的多跳问答基准测试中显著优于现有方法。例如,在某些任务上,CoDA的性能提升超过10%。此外,CoDA在长上下文场景中表现出强大的鲁棒性,在其他基线性能严重下降时,CoDA仍能保持稳定的性能,验证了其分层设计在缓解上下文过载方面的有效性。
🎯 应用场景
CoDA框架可应用于各种需要复杂推理和决策的多步骤任务,例如智能客服、自动化流程设计、机器人控制等。通过缓解LLM Agent的上下文爆炸问题,CoDA可以提高Agent在长上下文场景下的性能和鲁棒性,使其能够更好地适应实际应用需求,具有广阔的应用前景。
📄 摘要(原文)
Large Language Model (LLM) agents trained with reinforcement learning (RL) show great promise for solving complex, multi-step tasks. However, their performance is often crippled by "Context Explosion", where the accumulation of long text outputs overwhelms the model's context window and leads to reasoning failures. To address this, we introduce CoDA, a Context-Decoupled hierarchical Agent, a simple but effective reinforcement learning framework that decouples high-level planning from low-level execution. It employs a single, shared LLM backbone that learns to operate in two distinct, contextually isolated roles: a high-level Planner that decomposes tasks within a concise strategic context, and a low-level Executor that handles tool interactions in an ephemeral, isolated workspace. We train this unified agent end-to-end using PECO (Planner-Executor Co-Optimization), a reinforcement learning methodology that applies a trajectory-level reward to jointly optimize both roles, fostering seamless collaboration through context-dependent policy updates. Extensive experiments demonstrate that CoDA achieves significant performance improvements over state-of-the-art baselines on complex multi-hop question-answering benchmarks, and it exhibits strong robustness in long-context scenarios, maintaining stable performance while all other baselines suffer severe degradation, thus further validating the effectiveness of our hierarchical design in mitigating context overload.