Fine-Tuning Causal LLMs for Text Classification: Embedding-Based vs. Instruction-Based Approaches
作者: Amirhossein Yousefiramandi, Ciaran Cooney
分类: cs.CL, cs.AI
发布日期: 2025-12-14
备注: 18 pages, 6 figures
💡 一句话要点
探索高效微调因果LLM文本分类方法:嵌入式 vs. 指令式
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 文本分类 微调 低秩适应 模型量化 因果语言模型 嵌入式方法 指令微调
📋 核心要点
- 现有文本分类方法在计算资源有限的情况下,难以充分利用大型语言模型(LLM)的强大能力。
- 论文提出两种微调策略:基于嵌入的方法直接利用LLM的内部表示,指令微调方法则通过prompt->response格式进行训练。
- 实验结果表明,基于嵌入的方法在F1分数上显著优于指令微调方法,并能与领域特定模型竞争。
📝 摘要(中文)
本文研究了在资源受限情况下,高效微调仅解码器大型语言模型(LLM)用于下游文本分类任务的策略。主要探索两种方法:(1)将分类头连接到预训练的因果LLM,并针对任务进行微调(使用LLM的最终token嵌入作为序列表示);(2)以prompt->response格式指令微调LLM进行分类。为了在单个GPU上微调高达80亿参数的模型,我们将4位模型量化与低秩适应(LoRA)相结合,以实现参数高效训练。在两个数据集上的实验——一个专有的单标签数据集和公开的WIPO-Alpha专利数据集(极端多标签分类)——表明,基于嵌入的方法在F1分数方面显著优于指令微调方法,并且在相同的任务上,与微调的领域特定模型(例如BERT)相比,极具竞争力,甚至超越了它们。这些结果表明,直接利用因果LLM的内部表示,以及高效的微调技术,可以在有限的计算资源下产生令人印象深刻的分类性能。我们讨论了每种方法的优点,同时概述了在分类场景中优化LLM微调的实用指南和未来方向。
🔬 方法详解
问题定义:论文旨在解决在资源受限的情况下,如何高效地微调大型语言模型(LLM)用于文本分类的问题。现有方法,如直接全参数微调LLM,计算成本高昂,难以在单GPU等资源受限的环境下进行。同时,如何有效利用LLM的预训练知识,并将其迁移到特定的文本分类任务中,也是一个挑战。
核心思路:论文的核心思路是探索两种参数高效的微调策略,以在资源受限的情况下,充分利用LLM的强大能力。第一种方法是基于嵌入的方法,直接利用LLM的最终token嵌入作为序列表示,并在此基础上添加一个分类头进行微调。第二种方法是指令微调,通过prompt->response格式,引导LLM学习文本分类任务。
技术框架:整体框架包括两个主要分支:(1) 基于嵌入的方法:首先,使用预训练的因果LLM处理输入文本,提取最后一个token的嵌入向量。然后,将该嵌入向量输入到一个分类头(通常是一个线性层或多层感知机)进行分类。最后,使用交叉熵损失函数等进行微调。(2) 指令微调方法:将文本分类任务转化为prompt->response的形式,例如,prompt可以是“这段文本是关于什么的?”,response可以是文本的类别标签。然后,使用语言模型的目标函数(例如,最大似然估计)对LLM进行微调。两种方法都结合了4位量化和LoRA技术,以减少计算资源需求。
关键创新:论文的关键创新在于对比研究了两种不同的LLM微调策略在文本分类任务中的表现,并证明了基于嵌入的方法在资源受限的情况下,能够取得优异的性能。此外,论文还探索了4位量化和LoRA等参数高效微调技术在LLM文本分类中的应用。
关键设计:在基于嵌入的方法中,关键设计包括选择合适的LLM(例如,decoder-only模型),以及设计合适的分类头。在指令微调方法中,关键设计包括设计有效的prompt模板,以及选择合适的训练策略。两种方法都使用了4位量化来减少模型大小,并使用LoRA来减少需要训练的参数数量。损失函数通常采用交叉熵损失函数。LoRA的具体参数设置(如秩的大小)需要根据具体任务进行调整。
🖼️ 关键图片
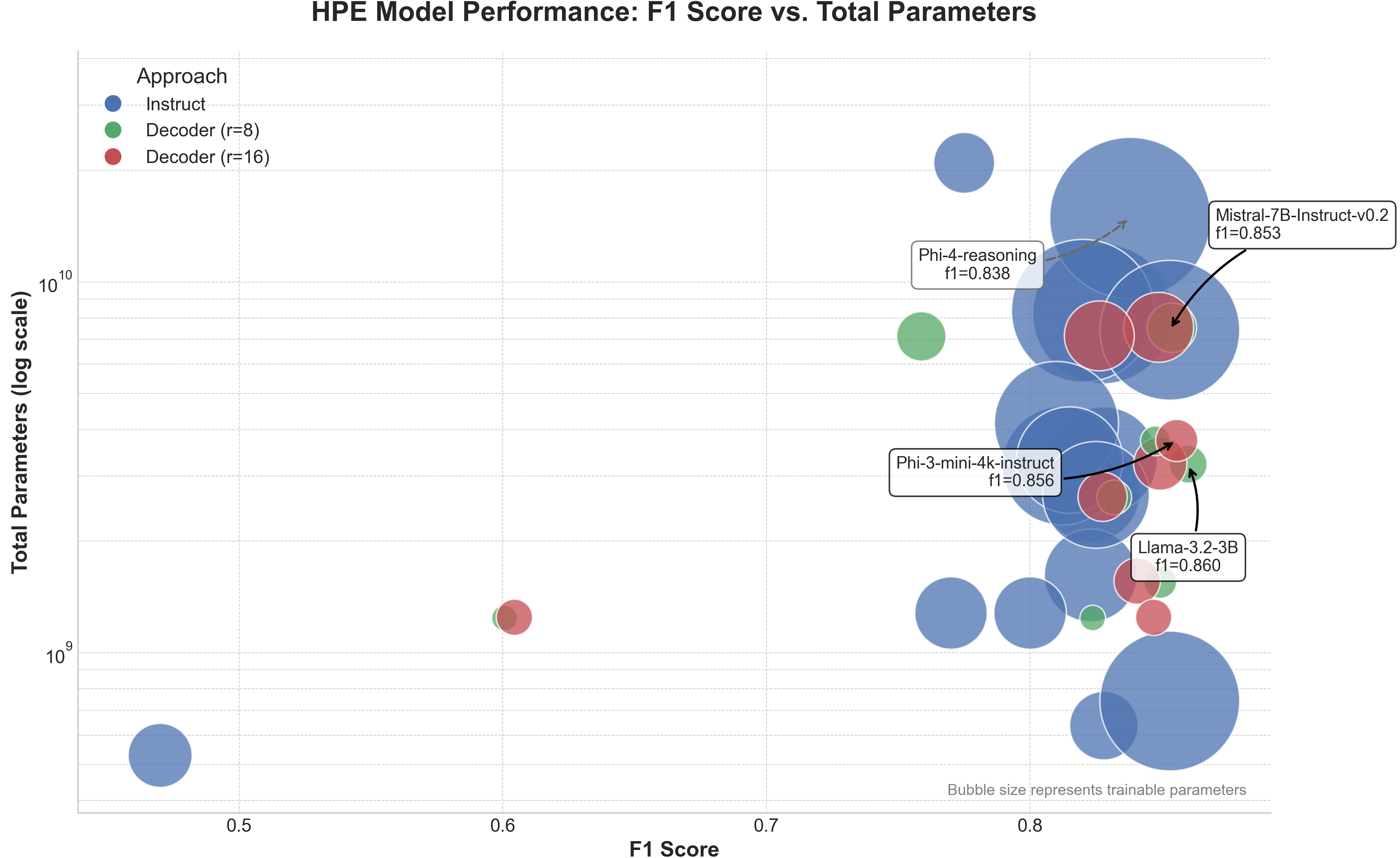
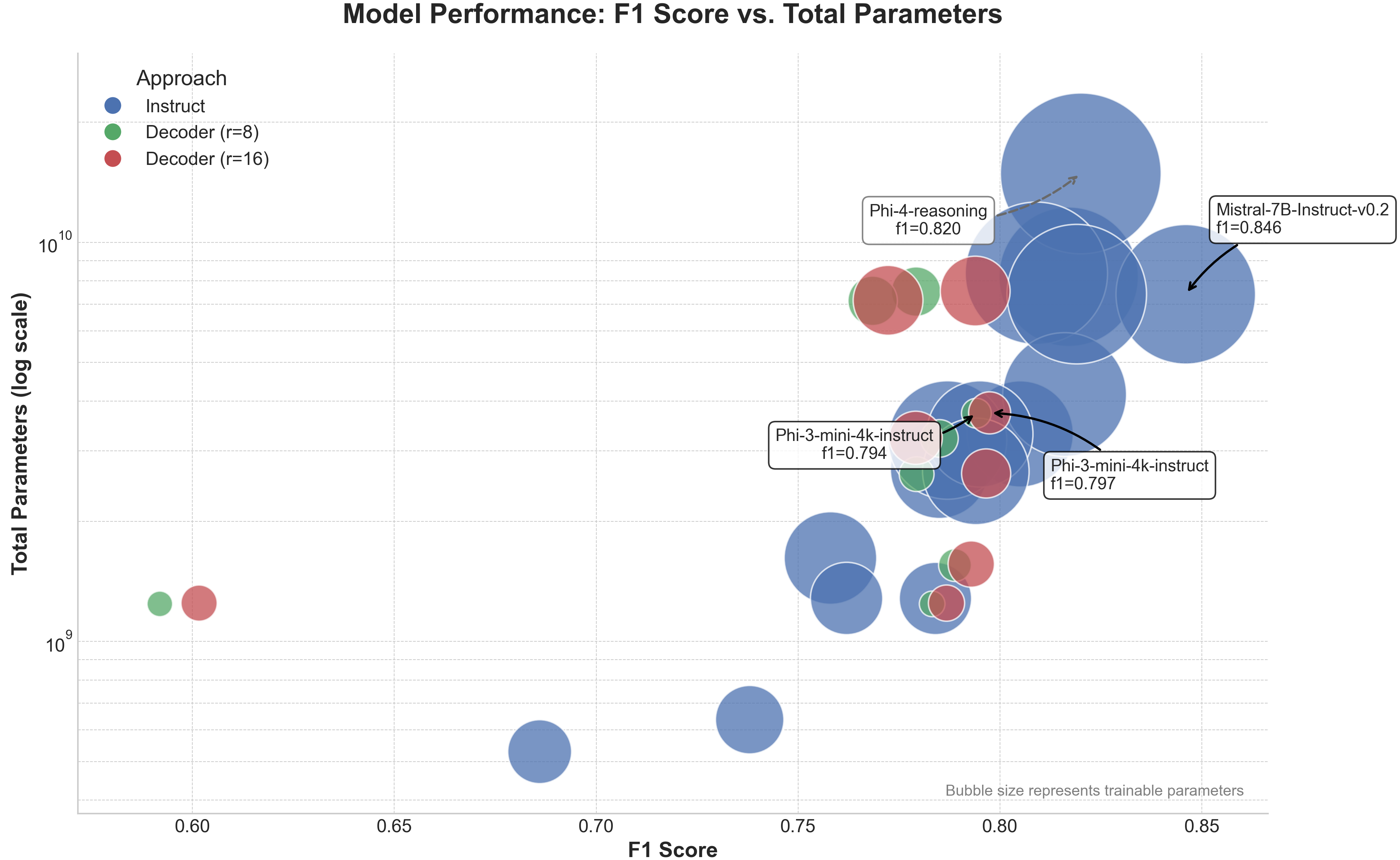
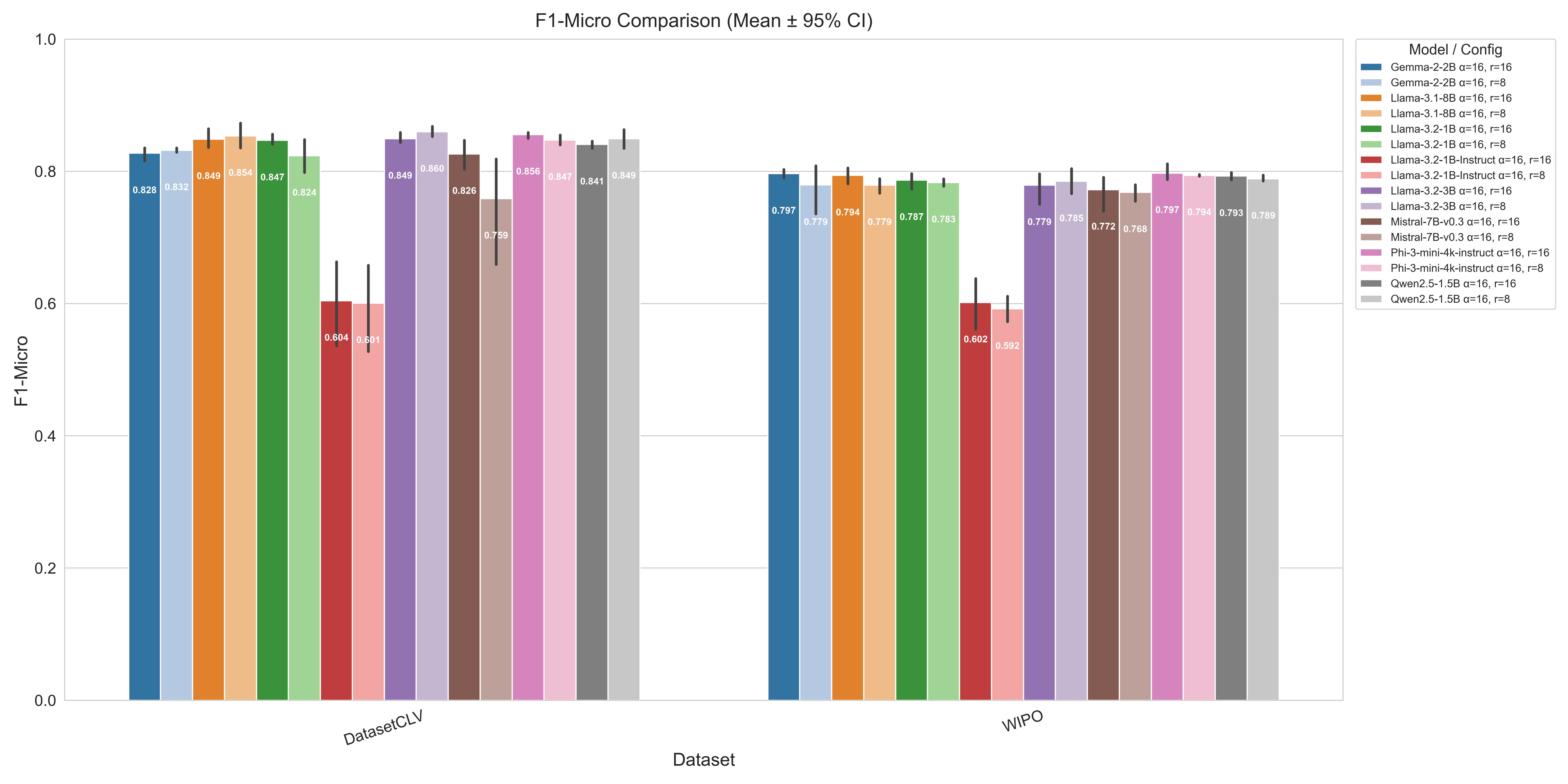
📊 实验亮点
实验结果表明,基于嵌入的方法在F1分数方面显著优于指令微调方法。在WIPO-Alpha专利数据集上,基于嵌入的方法甚至超越了微调的领域特定模型(例如BERT)。这些结果表明,在资源受限的情况下,直接利用LLM的内部表示,并结合高效的微调技术,可以取得令人印象深刻的分类性能。
🎯 应用场景
该研究成果可广泛应用于各种文本分类场景,例如情感分析、主题分类、垃圾邮件检测、专利分类等。尤其适用于计算资源有限的环境,例如移动设备或边缘计算设备。通过高效微调LLM,可以显著提升文本分类的准确性和效率,为企业和研究机构提供更强大的文本处理能力。
📄 摘要(原文)
We explore efficient strategies to fine-tune decoder-only Large Language Models (LLMs) for downstream text classification under resource constraints. Two approaches are investigated: (1) attaching a classification head to a pre-trained causal LLM and fine-tuning on the task (using the LLM's final token embedding as a sequence representation), and (2) instruction-tuning the LLM in a prompt->response format for classification. To enable single-GPU fine-tuning of models up to 8B parameters, we combine 4-bit model quantization with Low-Rank Adaptation (LoRA) for parameter-efficient training. Experiments on two datasets - a proprietary single-label dataset and the public WIPO-Alpha patent dataset (extreme multi-label classification) - show that the embedding-based method significantly outperforms the instruction-tuned method in F1-score, and is very competitive with - even surpassing - fine-tuned domain-specific models (e.g. BERT) on the same tasks. These results demonstrate that directly leveraging the internal representations of causal LLMs, along with efficient fine-tuning techniques, yields impressive classification performance under limited computational resources. We discuss the advantages of each approach while outlining practical guidelines and future directions for optimizing LLM fine-tuning in classification scenarios.