LexRel: Benchmarking Legal Relation Extraction for Chinese Civil Cases
作者: Yida Cai, Ranjuexiao Hu, Huiyuan Xie, Chenyang Li, Yun Liu, Yuxiao Ye, Zhenghao Liu, Weixing Shen, Zhiyuan Liu
分类: cs.CL
发布日期: 2025-12-14
💡 一句话要点
LexRel:构建中文民事案件法律关系抽取基准,揭示LLM局限性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 法律关系抽取 中文民事案件 法律人工智能 大型语言模型 基准数据集
📋 核心要点
- 现有法律AI研究缺乏对中文民事案件法律关系的深入探索,主要原因是缺乏全面的法律关系模式。
- 论文构建了一个全面的法律关系模式,并提出了LexRel基准数据集,用于评估和提升模型在法律关系抽取任务上的性能。
- 实验表明,现有LLM在准确识别民事法律关系方面存在局限性,但结合法律关系信息可以提升下游法律AI任务的性能。
📝 摘要(中文)
法律关系是民法体系中一个高度重要的分析框架,是解决纠纷和实现司法实践中法治价值的关键基础。然而,由于缺乏全面的模式,中文民事案件中的法律关系在法律人工智能(legal AI)领域仍未得到充分探索。本文首先引入了一个全面的模式,其中包含一个分层分类法和论证定义,供AI系统捕获中文民事案件中的法律关系。基于此模式,我们提出了法律关系抽取任务,并提出了LexRel,这是一个由专家注释的中文民法法律关系抽取基准。我们使用LexRel来评估最先进的大型语言模型(LLM)在法律关系抽取方面的表现,结果表明,当前的LLM在准确识别民事法律关系方面存在显著局限性。此外,我们证明了结合法律关系信息可以持续提高其他下游法律AI任务的性能。
🔬 方法详解
问题定义:论文旨在解决中文民事案件中法律关系抽取的问题。现有方法的痛点在于缺乏一个全面的、专家标注的法律关系模式和基准数据集,导致现有模型难以准确识别和抽取法律关系。
核心思路:论文的核心思路是构建一个全面的法律关系模式,并基于此模式构建一个高质量的基准数据集LexRel。通过在LexRel上评估现有LLM,揭示其在法律关系抽取方面的局限性,并探索利用法律关系信息提升下游任务性能的方法。
技术框架:整体框架包括以下几个主要步骤:1) 构建法律关系模式,定义法律关系类型和论证;2) 基于该模式,由法律专家对中文民事案件进行标注,构建LexRel数据集;3) 使用LexRel数据集评估现有LLM在法律关系抽取任务上的性能;4) 将抽取的法律关系信息融入到下游法律AI任务中,评估其对下游任务性能的影响。
关键创新:论文的关键创新在于构建了一个全面的、分层的法律关系模式,该模式包含了法律关系的类型和论证,为法律关系抽取任务提供了清晰的定义和指导。此外,LexRel数据集是首个针对中文民事案件法律关系抽取的专家标注基准数据集。
关键设计:论文中法律关系模式的设计是关键。该模式采用分层结构,从宏观到微观地定义了法律关系的类型。此外,论文还定义了论证,用于描述法律关系中各要素之间的逻辑关系。在实验中,论文使用了多种LLM作为基线模型,并探索了不同的方法将法律关系信息融入到下游任务中,例如作为额外的输入特征。
🖼️ 关键图片
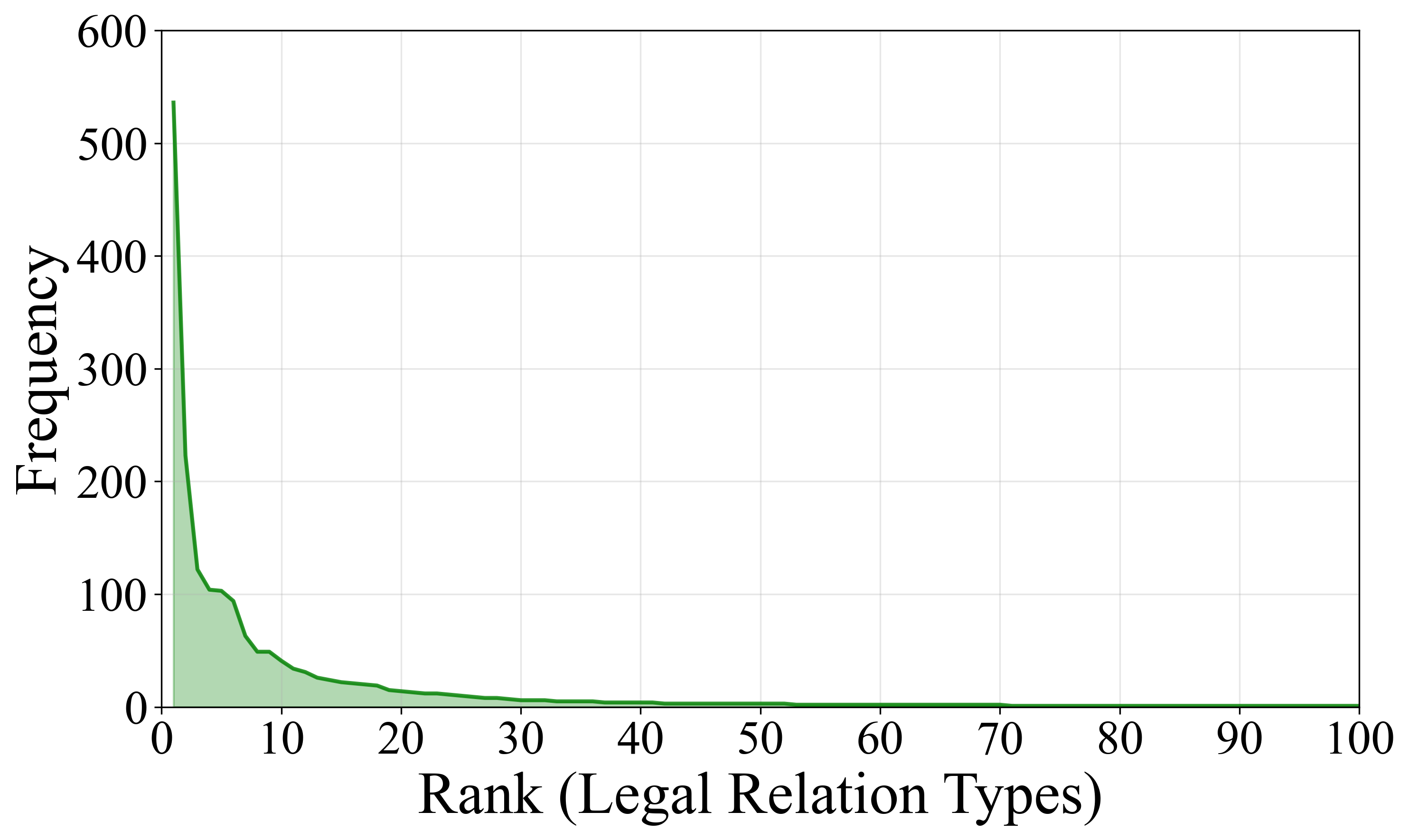
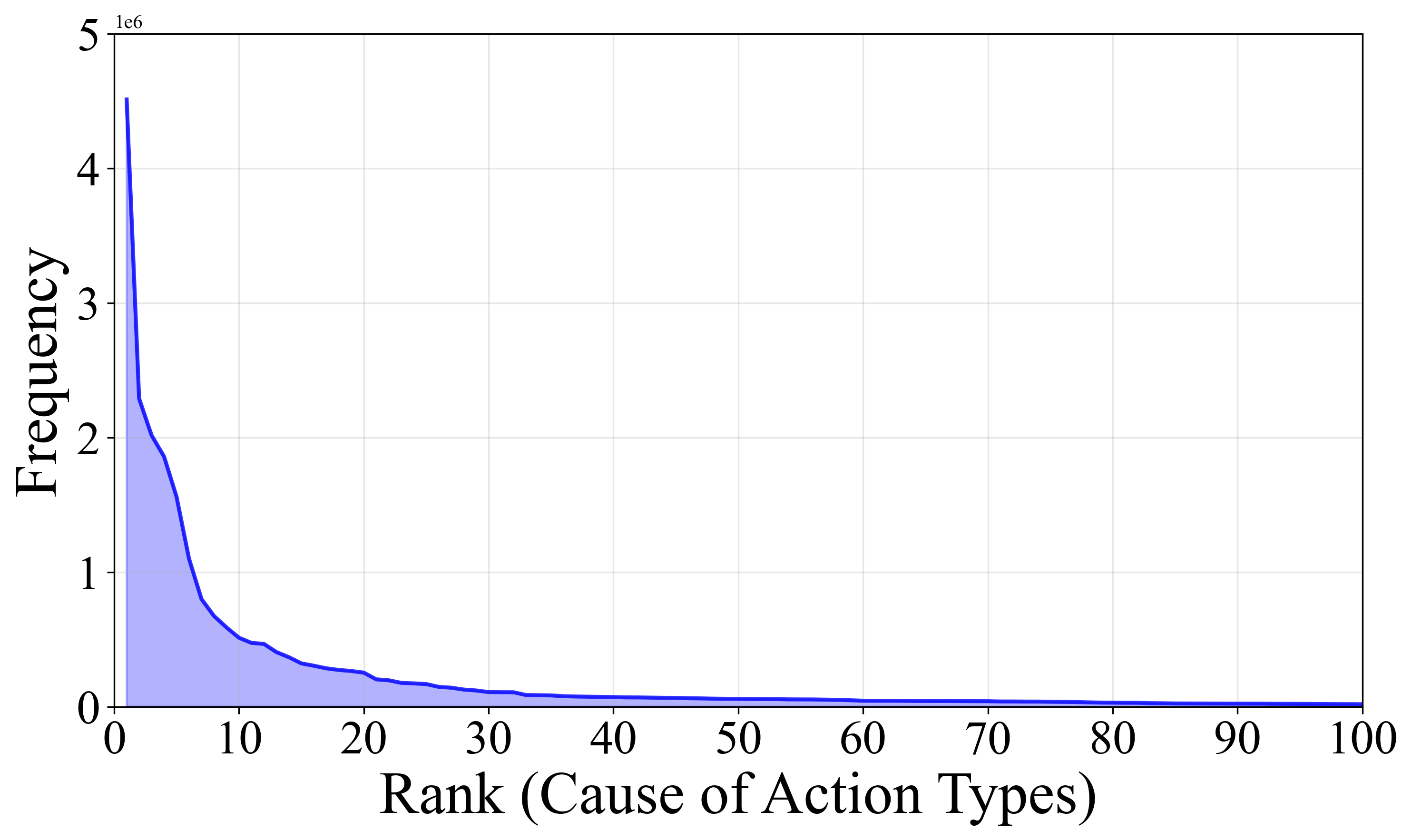
📊 实验亮点
实验结果表明,现有LLM在LexRel数据集上的法律关系抽取性能有限,表明其在理解复杂法律关系方面存在不足。然而,通过将抽取的法律关系信息融入到下游法律AI任务中,例如案件分类和判决预测,可以显著提升这些任务的性能,验证了法律关系信息的重要性。
🎯 应用场景
该研究成果可应用于智能法律咨询、案件分析、法律文书自动生成等领域。通过准确抽取法律关系,可以帮助法律从业者更高效地理解案情、分析证据,并为当事人提供更专业的法律服务。未来,该研究有望推动法律人工智能的发展,促进司法公正和效率。
📄 摘要(原文)
Legal relations form a highly consequential analytical framework of civil law system, serving as a crucial foundation for resolving disputes and realizing values of the rule of law in judicial practice. However, legal relations in Chinese civil cases remain underexplored in the field of legal artificial intelligence (legal AI), largely due to the absence of comprehensive schemas. In this work, we firstly introduce a comprehensive schema, which contains a hierarchical taxonomy and definitions of arguments, for AI systems to capture legal relations in Chinese civil cases. Based on this schema, we then formulate legal relation extraction task and present LexRel, an expert-annotated benchmark for legal relation extraction in Chinese civil law. We use LexRel to evaluate state-of-the-art large language models (LLMs) on legal relation extractions, showing that current LLMs exhibit significant limitations in accurately identifying civil legal relations. Furthermore, we demonstrate that incorporating legal relations information leads to consistent performance gains on other downstream legal AI tasks.